Microsoft Azure Machine Learning - Day 2
Chap.I Practical drill 实战演练
以下内容来自这里
Prat1. Create Azure ML Workspace
此处将会练习创建 Azure ML,使用其内建的笔记本功能(内容来自这里)
1-1. 创建一个 ML 环境
所有服务 → AI + 机器学习服务 → 机器学习
基本
资源群组:RG1(随便取)
工作区名称:WS(随便取)
区域:美国西部(此处建议美西或日本,网路比较顺)
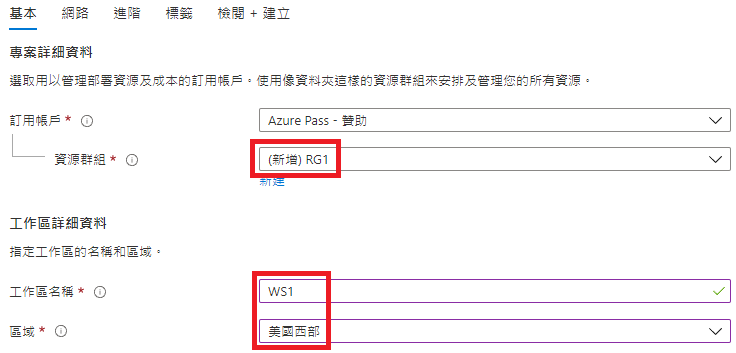
建立
1-2. 开启 python 编写笔记本
前往资源 → 启动工作区
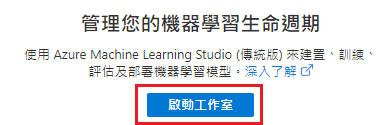
新增笔记本
此时会发现右上角显示「找不到任何计算」,那是因为目前我们尚未建立虚拟机
1-3. 建立虚拟机
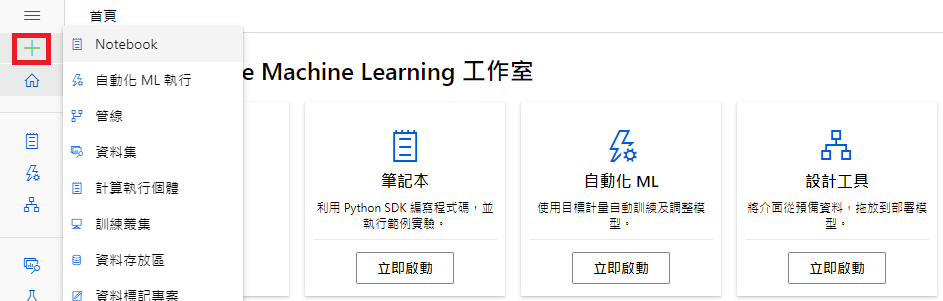
在左侧可以发现互动按钮,点选「计算」後,上方出现四个选项
- 计算执行个体:建立一台虚拟机,用於开发阶段。
- 计算丛集:建立多台虚拟机,会互相支援,当遇灾害时可无缝接轨计算工作,用於开发阶段。
- 推断 (inference) 丛集:使用训练後的模型,去预测服务的目标
- 附加的计算:链接到其他 Azure 计算资源,如:其他虚拟机、Azure Databricks...等
此时,我们先选择建立计算执行个体
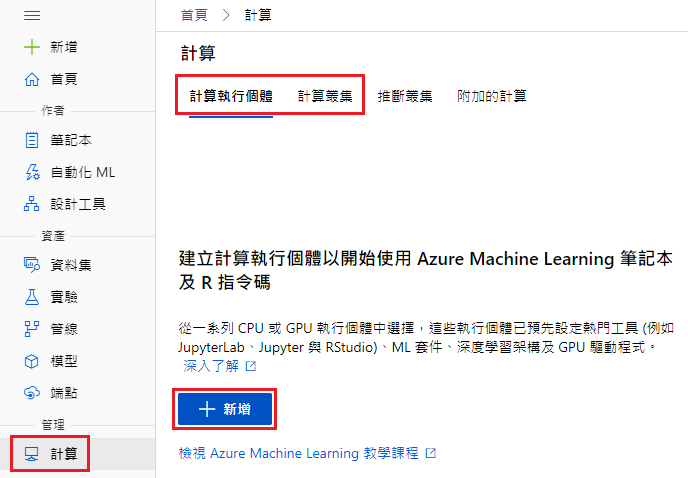
必要设定
计算名称:myCP(随便取)
虚拟机器类型:CPU(比较省钱)
核心类型选:Standard_DS11_v2(比较省钱)

进阶设定
使用预设即可
建立
1-4. 使用笔记本
回到笔记本,会发现已经可以选用刚建立的虚拟机来计算

这时我们用以下程序码,试着把连线到这的主机名称印出来
首先,安装套件
pip install azureml-sdk
尝试印出所有连线的主机名称
from azureml.core import Workspace
ws = Workspace.from_config()
for compute_name in ws.compute_targets:
compute = ws.compute_targets[compute_name]
print(compute_name, ':', compute.type)
此时会发现下方出现一排文字:
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code EET7MBNGK to authenticate.
照着指示点击网站,输入验证码(也就是 EET7MBNGK)并登入就可以了
>> myCP : ComputeInstance
1-5. 删除资源
Prat2. Use Automated Machine Learning
此处将会练习创建 Automated ML,并用其评估模型(内容来自这里)
2-1. 配置机算资源
计算 → 计算丛集 → 新增
虚拟机器
位置:美国西部(连线比较快)
虚拟机器类型:CPU(比较省钱)
核心类型选:Standard_DS11_v2(比较省钱)

进阶设定
计算名称:Cluster(随便取)
节点数目下限:0(闲置的时候会自动关闭多余此数量的虚拟机)
节点数目上限:2
建立
2-2. 建立资料集
首先把这里的资料下载下来,存成 diabetes.csv 档名
接着选择资料集 → 建立资料集 → 来自本机的档案
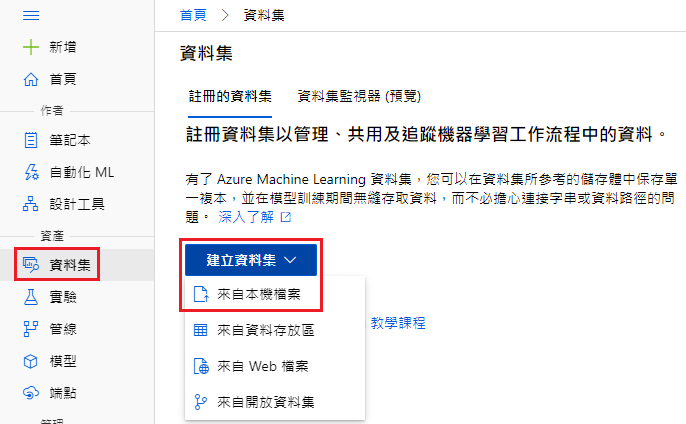
基本资讯
名称:diabetes.csv
资料集类型:表格式
描述:Diabetes data(随便)

资料存放区与档案选取
为你的资料集选取档案 → 上传档案 → 找到刚才存到电脑中的 diabetes.csv

设定与预览
档案格式:分隔符号(其它选项还有纯文字、Parquet 档案、JSON 行等)
分隔符号:逗号(看你的档案用什麽分隔资料)
编码:UTF-8
资料行标头:所有档案都有相同的标头
(V) 资料集包含多行资料
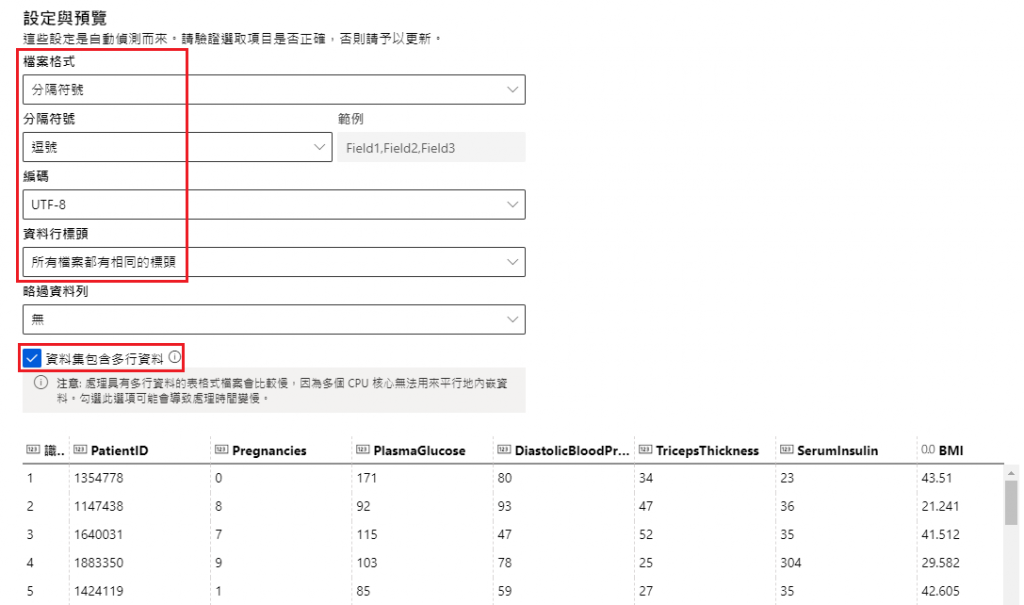
结构描述
使用预设即可
确认详细资料
建立
2-3. 布置一个自动化 ML
自动化 ML 即是让 Azure ML 自动帮你使用资料集计算,找出最佳 model
自动化 ML → 新增自动话 ML 回合
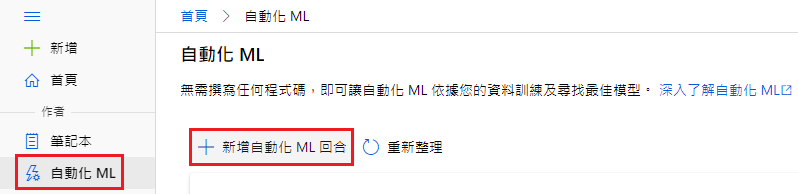
选取资料集
选取 diabetes.csv

实验名称
新增实验名称:mslearn-automl-diabetes(随便)
目标资料行:Diabetic(这个栏位是选择资料集中的 y 值)
选取计算类型:计算丛集
选取 Azure ML 计算丛集:Cluster
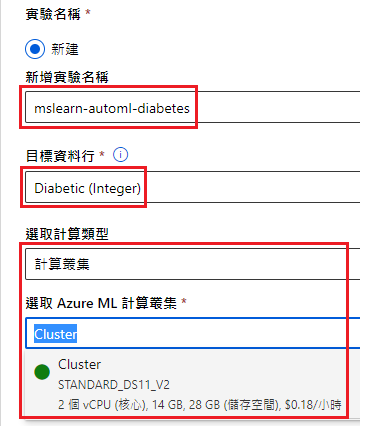
选取工作和设定
因为这个资料集是糖尿病,因此选择分类(预设就是分类)
点选下方「检视其他组态设定」
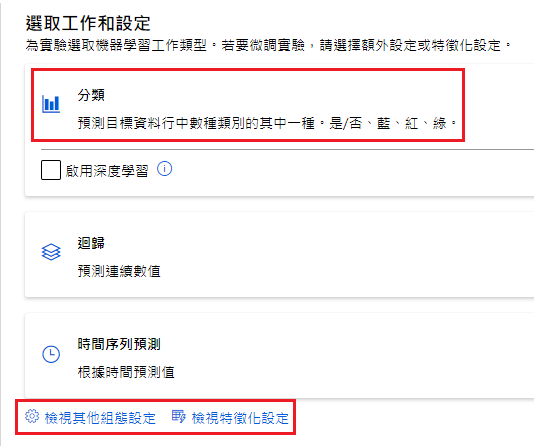
其他组态
主要计量:加权後的 AUC(采用 AUC 对模型评分)
(V) 解释最佳模型
封锁的演算法:(有些模型不适合演算此类型资料,可以从这里剃除)
训练作业小时:0.5(作业超过半小时就结束演算)
计量分数阈值:0.90(90% AUC 以上会结束演算)
储存
验证和测试
2-4. 查看模型评分
实验 → mslearn-automl-diabetes → khaki_rhubarb_3p1l7btj → 详细资料
最佳演算法名称:MaxAbsScaler, LightGBM
加权後的 AUC:0.98996
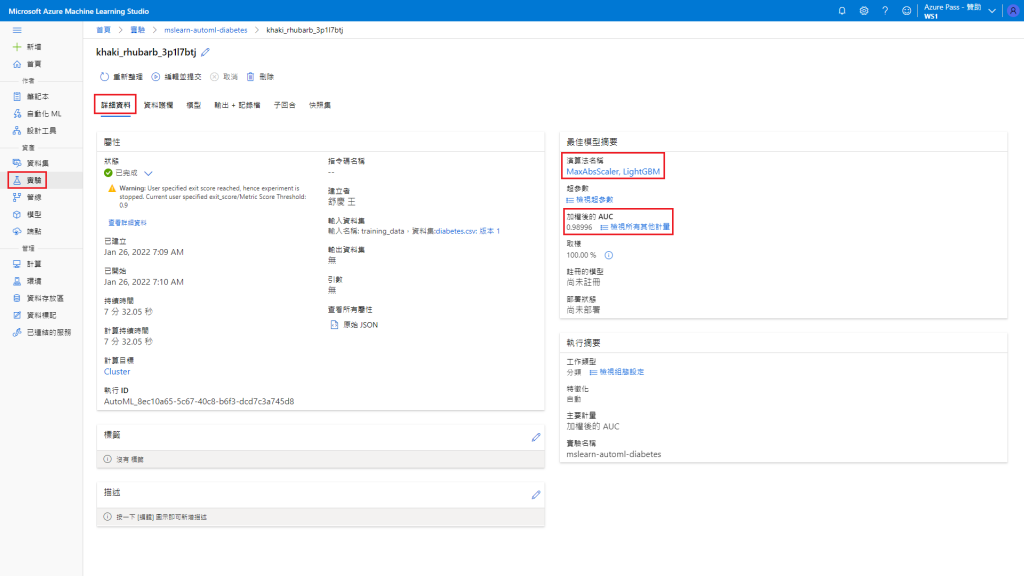
2-5. 将训练好的模型部属
接续上一步骤,点击 MaxAbsScaler, LightGBM → 部属 → 部属到 Web 服务
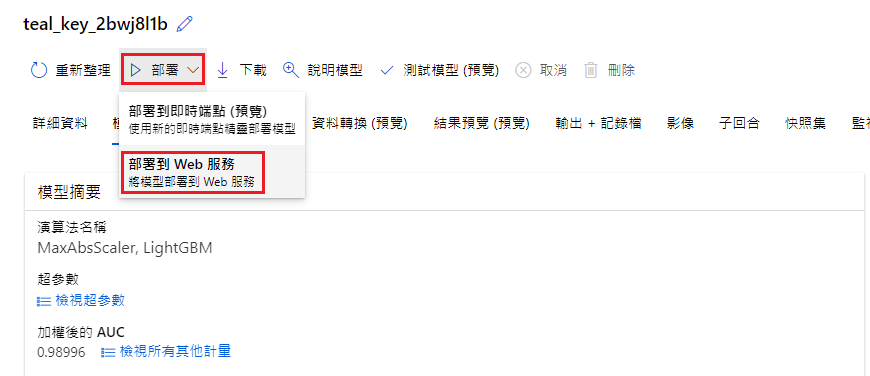
部属模型
名称:auto-predict-diabetes(随便)
描述:Predict diabetes(随便)
计算类型:Azure 容器执行个体
(V) 启用验证
(X) 使用自订部属资产
部属
2-6. 测试部属服务
端点 → 测试 → 选择资料输入方式(此处为 csv) → 测试
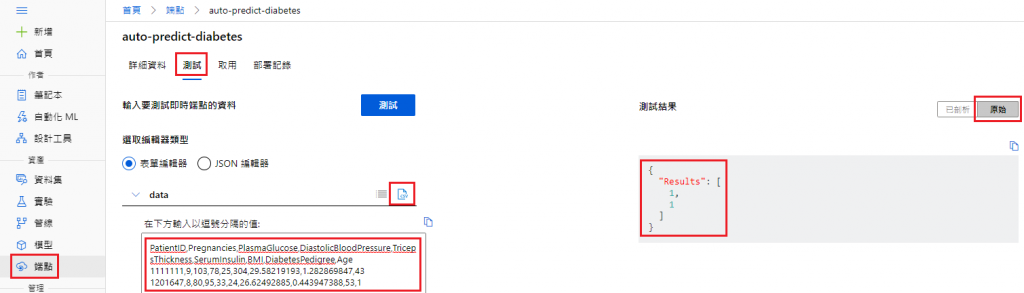
可以看到两位病患都成功被预测为 1!!!
2-7. 删除资源
Prat3. Use Azure Machine Learning Designer
此处将会练习 Azure Machine Learning Designer 创建模型(内容来自这里)
Azure ML 提供了设计 pipeline 的功能,可以自定义想要的生产管线;或者使用现成的范本操作。
我们就直接使用 Part2. 建立的「计算丛集」与「资料集」来操作,不额外建立。
3-1. 建立自己的 pipeline
设计工具 → 新增管线 → 易於使用的预建模组
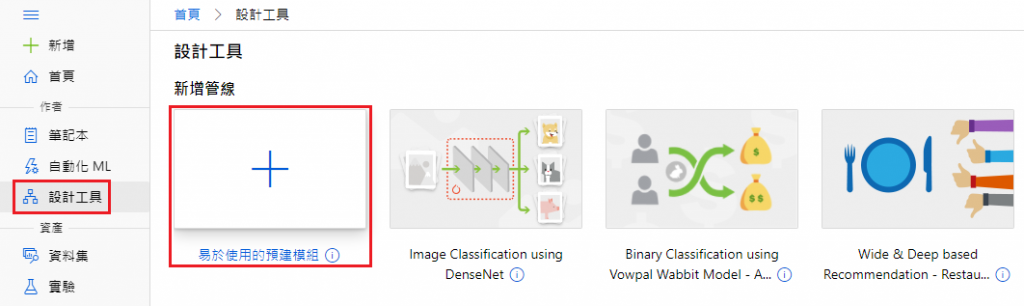
点选小齿轮进入设定
选取计算类型:计算丛集
选取 Azure ML 计算丛集:Cluster
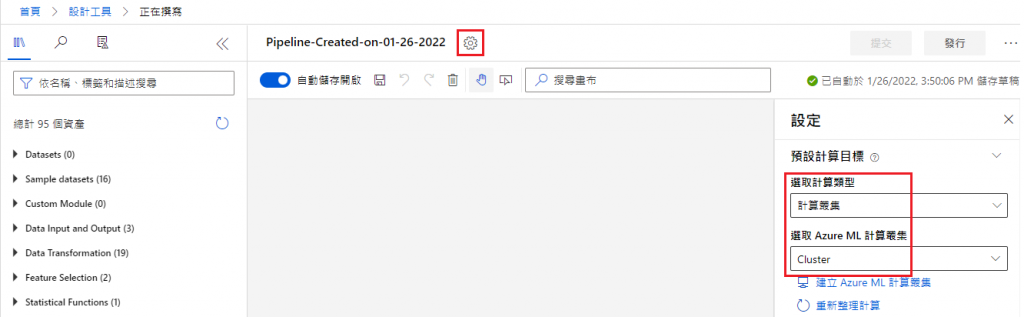
接着会看到一面灰色的画布,我们会在这建立自订的管线
Datasets
首先,点选 Datasets,用滑鼠将其拖曳至画布
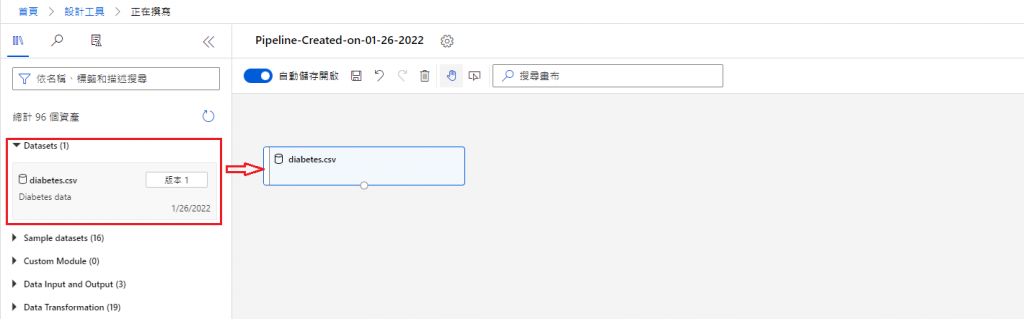
Normalize Data
接着在搜寻栏查找 Normalize Data 并拖曳到画布,将 Datasets 连接到 Normalize Data
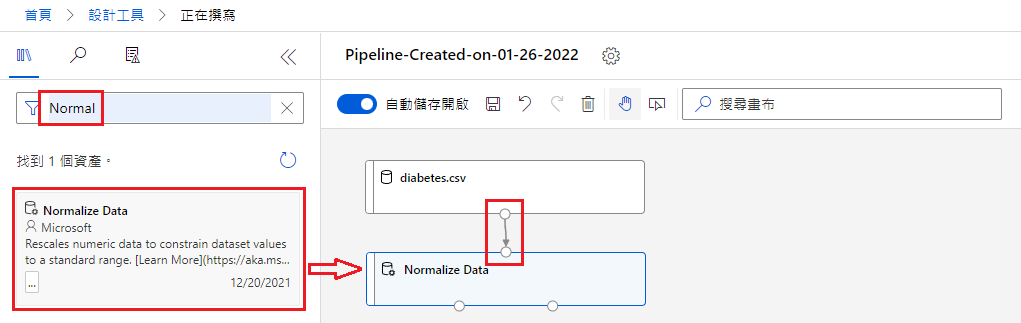
此时点选 Normalize Data,系统会要求我们选取「需要标准化」的栏位
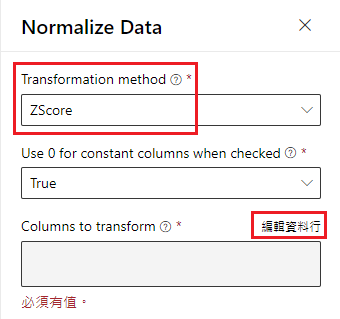
依次输入以下栏位:
- PlasmaGlucose
- DiastolicBloodPressure
- TricepsThickness
- SerumInsulin
- BMI
- DiabetesPedigree
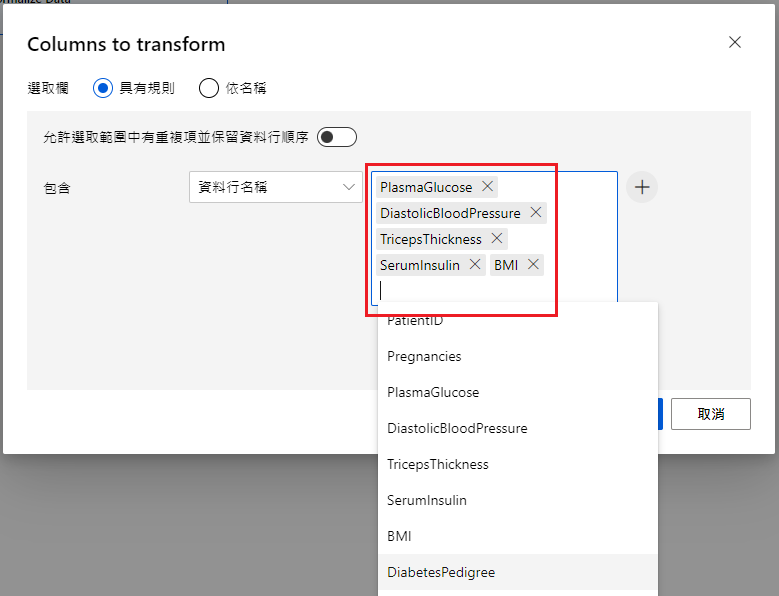
Split Data
第三步是分割资料,一样拖曳到画布,将 Normalize Data 连接到 Split Data
值得注意的是,分割方法有以下三种:
- Split Rows:用「指定比例(预设 50-50)」将资料拆成「两份」。
- Regular Expression:用「单列的值」划分。如:性别、有/无抽菸...等。
- Relative Expression:不等量切割,用「数字区间」划分。如:成本、年龄或日期...等。
Split mode:因为是分析糖尿病,所以选择 Split Rows 就好。
Fraction of rows
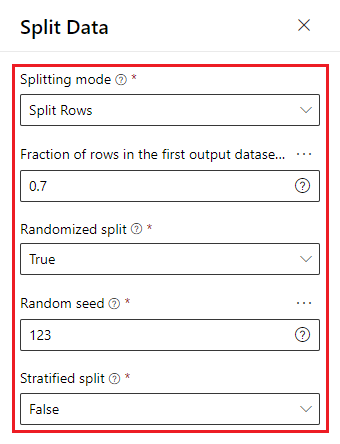
Train Model
第四步,把 Train Model 拖曳进画布,并把 Split Data 连接到 Train Model 的「右上」(稍後会解释)。
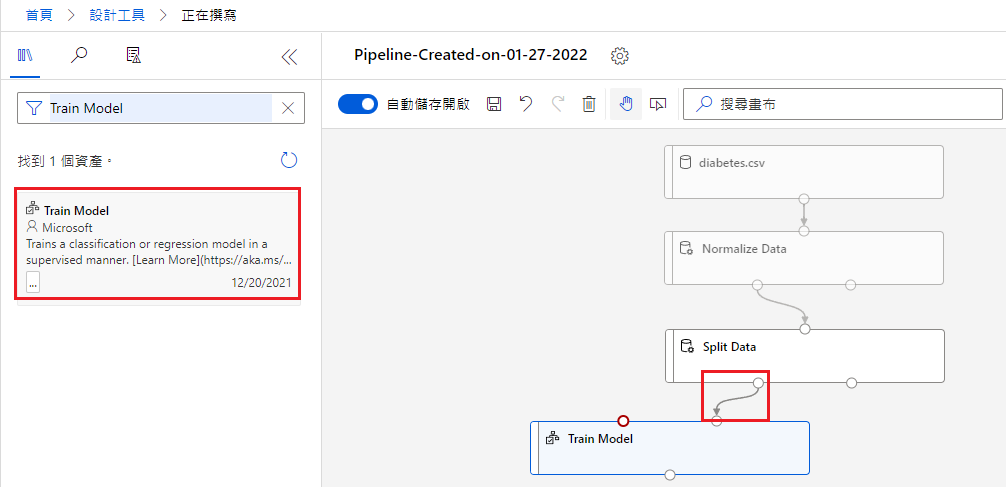
接着点画布中的 Train Model,设定 Label Column:Diabetic(要分析的 y)

Two-Class Logistic Regression
选择一个演算法,这边选用的是 Two-Class Logistic Regression。
将它拖曳到 Split Data 的左方;Train Model 的上方,并将它与 Train Model 连接。
这边的意义是,Train Model 将 Split Data 的资料用 Logistic Regression 建模。
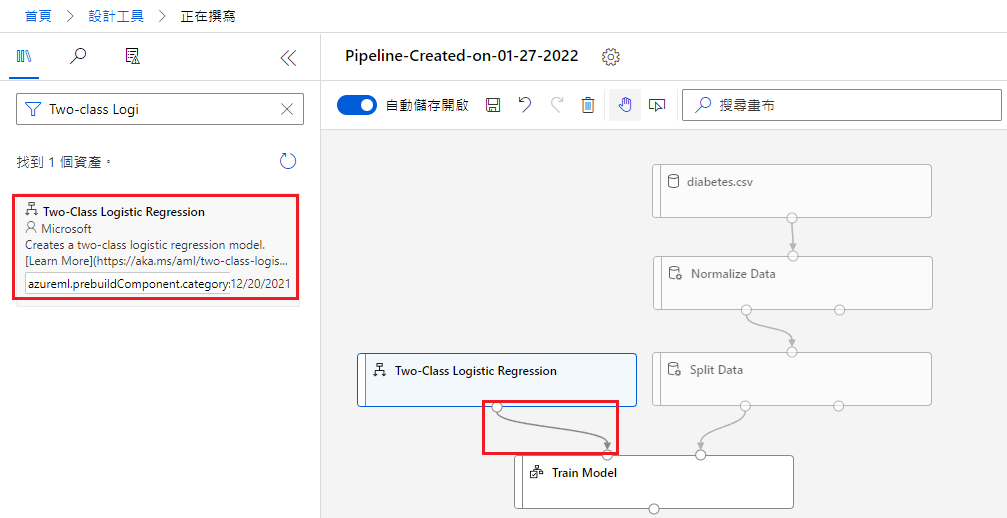
Score Model
第五步,把 Score Model 拖曳进画布,把 Train Model 连接到 Score Model 的「左上」;同时把 Split Data 连接到 Score Model。
这边的意义是,Score Model 将 Split Data 的资料为 Train Model 跑分。
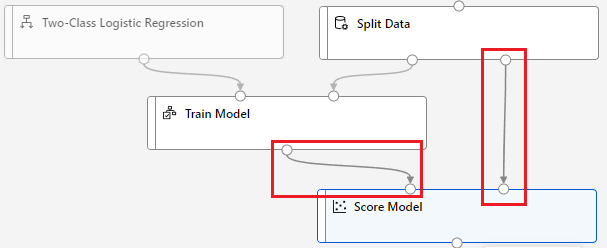
Evaluate Model
最後是评分模型,直接拖曳并将 Score Model 连接即可。可同时连接多个模型。
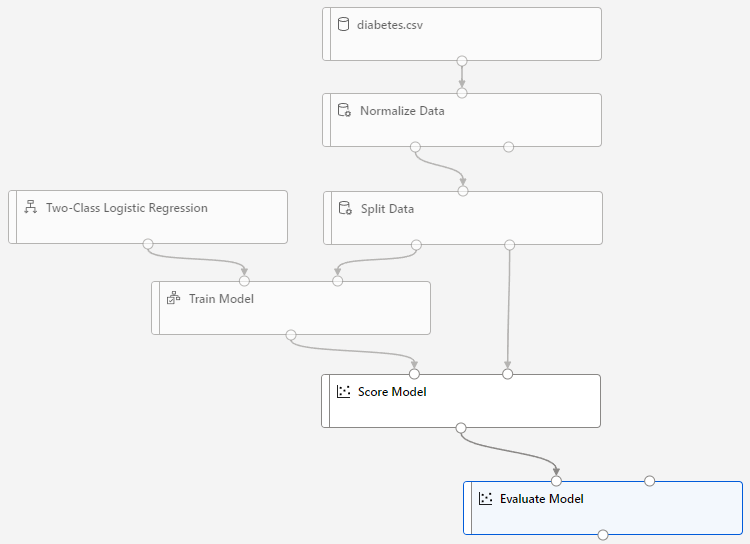
按下右上角的「提交」,新增实验名「mslearn-designer-train-diabetes」,就完成了自定义的 Pipeline了~
3-2. 查看资料
完成产线并且执行後,我们可以对单个步骤按右键预览资料。
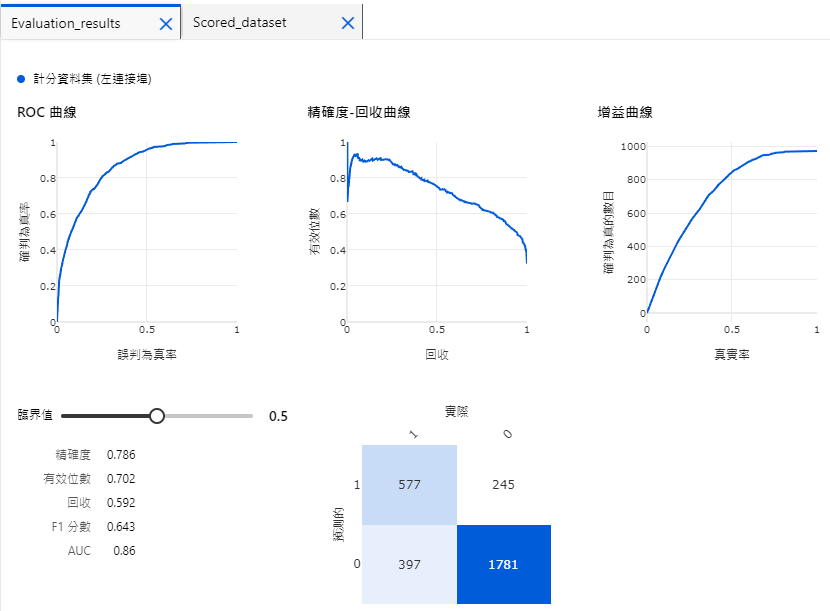
比方说,我们对 Score Model 按右键预览资料,就可以看到模型的预测机率
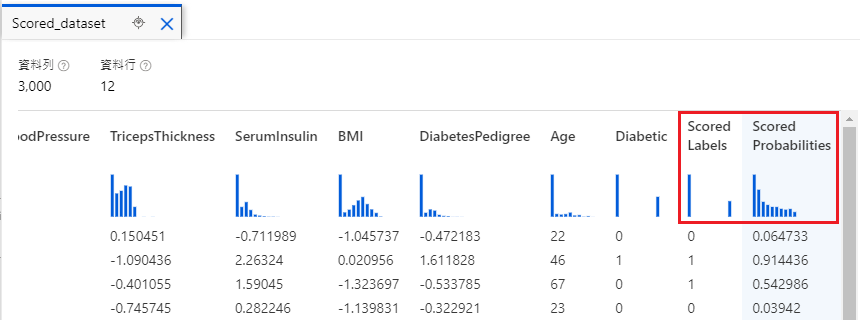
而对 Evaluate Model 查看,则会显示 ROC (AUC),混淆矩阵等资讯
3-3. 部属即时推断管线
提交完成後,右上角提交旁边会多出一个「建立推断管线」,其中又分成:
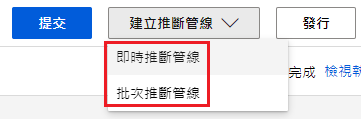
- 即时推断(Real-Time)管线:呼叫後执行,立即回传预测结果,问一回一。
- 批次推断(Batch)管线:呼叫後执行,但预测结果将存储於主机,待全部资料解析完成,方可手动查询。
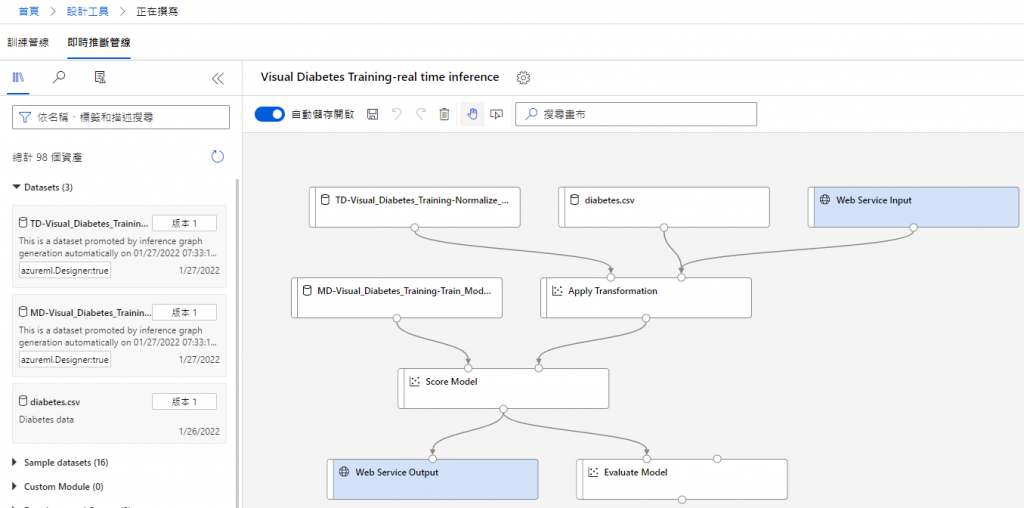
这边为了方便,选择即时推断管线就好,完成後如下
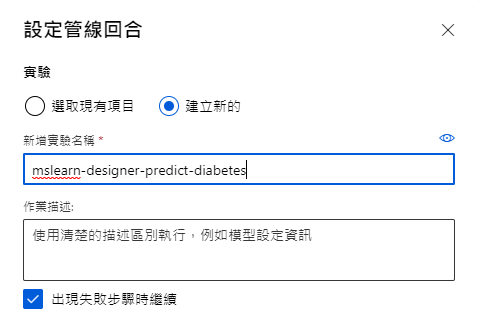
接着按右上角「提交」,新增实验名「mslearn-designer-predict-diabetes」
3-4. 部属即时端点
提交完成後,就可以按右上角「部属」,进入设定画面
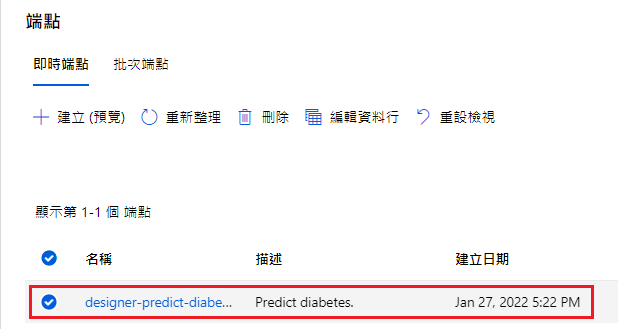
名称:designer-predict-diabetes
描述:Predict diabetes.
计算类型:Azure 容器执行个体

部属完成後,在端点就可以看到部属完成了!
.
.
.
.
.
补充
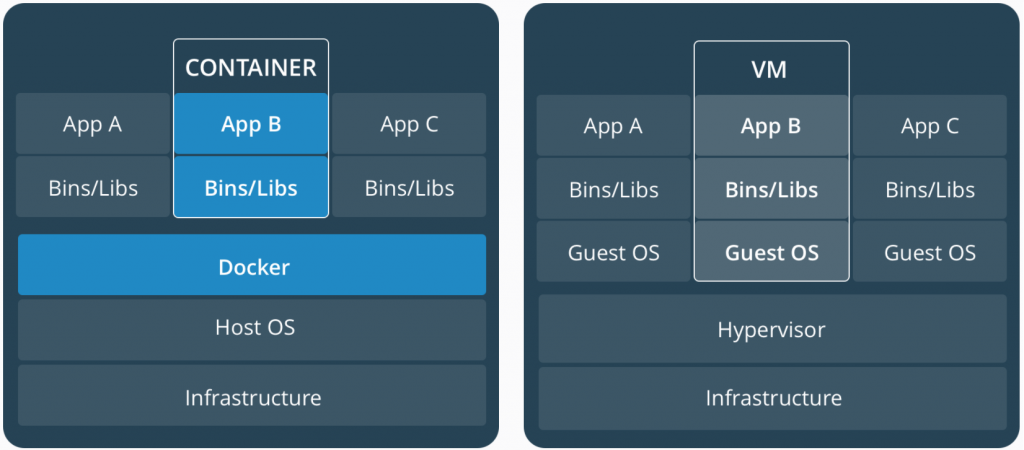
虚拟机与容器最大的差异在於,虚拟机有 Guest Operating System (Guest OS),而容器则无。
相同的资源量,Docker 的利用率更高,可以设定更多的 Containers,且启动速度更快。
10.MYSQL运算子
每一种语言都有自己运算的符号,SQL也不例外,下面帮大家整理了一些常用的一些运算子,这些运算子会在条...
[Day3] Jetpack Compose: 为什麽这个EditText不会动?
今天跑去面试新工作和准备下一阶段面试,十一点才想到要写,所以就意思意思一下XD,之後会回来补齐的Q...
Thunkable学习笔记 4 - 变数(Firebase EMail登入的延伸)
这篇是 Thunkable学习笔记 2 - 加入Firebase登入功能(使用EMail) 的功能加...
Day13: HTTP服务器
哈罗~~大家好!!星期五好愉快~~马上进入主题吧!! 今天要介绍的是使用NodeJs建立後端的服务器...
软件工程师(ASP.NET)面试心得分享
这是我自己面谈後的反省心得,有些要注意的地方真的是讲到烂了,网路上应该也很多面谈教学,但还是想整理...