[Day 17] 我的资料哪有这麽平衡!第二季 (class weights)
前言
走过了资料分析、演算法选择後,
我们得知了有些可以改善模型的方向:
- 解决资料不平衡(Now)
- 学习率的设定(Not yet)
- 训练轮数(Not yet)
- 模型深度(Not yet)
- 阶段式训练(Not yet)
为了解决资料不平衡的问题,
昨天尝试过资料增强,
但效果不是很明显,
今天我将尝试调整类别权重(class weight)。
类别权重
MSE
现在我们从损失函数(loss function)下手,
以最简单的Mean Squared Error举例:
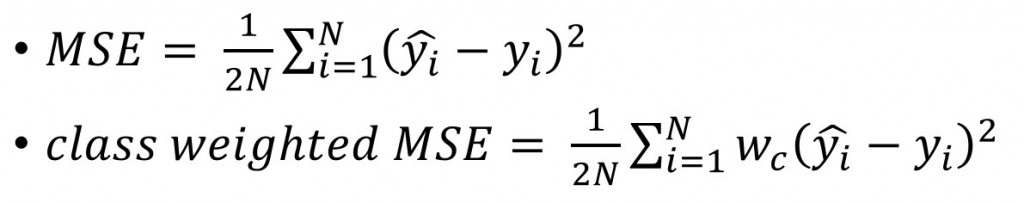
我们现在有N笔资料,y^是预测值;y是实际值,
对於每一笔资料i来说,我们去计算预测值和实际值差的平方,
然後取平均值。(为什麽要除以2? 因为导数比较好看 :D)
class-weighted
class-weighted MSE就是在计算第i笔资料时乘以一个权重,
如果这个权重比较大,那这笔资料的loss就会影响整体loss较多。
所以只要对某一个类别的所有资料乘以一个大大的权重(W_c),
就等於这一类别影响整体loss很多。
由於最佳化理论就是在想办法降低loss,
所以当某一类别占据大部分的loss时,
最佳化方法降低loss时,就是在特别学习该类别的资料。
你想要哪个类别被特别关注,就把该类别的权重调大就对了!
对於资料量较少的类别(像是罕见疾病),
我们预设模型在学习辨识它们时会有困难(因为给他学的材料不够多),
所以把资料量少的类别权重提升就对了!
程序码
在实务上有一个简单地决定类别权重的方式,
那就是把每一类权重设成该类资料量的倒数。
例如:
| 类别 | 资料量 | 类别权重 |
|---|---|---|
| A | 1 | 1 |
| B | 10 | 0.1 |
| C | 100 | 0.01 |
以下是我的实作方式,
如果有更简单的方式欢迎提出XD
class_sample_size = [np.where(y_train == c)[0].shape[0]
for c in range(len(emotions.keys()))]
max_class_size = np.max(class_sample_size)
class_weight = [max_class_size/size for size in class_sample_size]
class_weight = dict(zip(emotions.keys(), class_weight))
# class_weight =
# {0: 1.8060075093867334, 1: 16.548165137614678, 2: 1.7610446668293873, 3: 1.0, 4: 1.4937888198757765, 5: 2.275307473982971, 6: 1.4531722054380665}
上面做成一个dictionary是因为keras.fit()下参数的时候需要。
hist1 = model.fit(X_train, y_train_oh, validation_data=(X_val, y_val_oh),
epochs=epochs, batch_size=batch_size, class_weight=class_weight)
- 特别说明: training时才会被class_weight影响,validation set的loss计算还是照旧。
实验结果
训练出来的模型就叫做EFN_classWeight。
拿来和EFN_base(baseline)做比较:
| 模型 | 训练时长(秒) | acc | loss | val_acc | val_loss |
|---|---|---|---|---|---|
| EFN_classWeight | 2557 | 0.931 | 0.315 | 0.603 | 1.844 |
| EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905 |
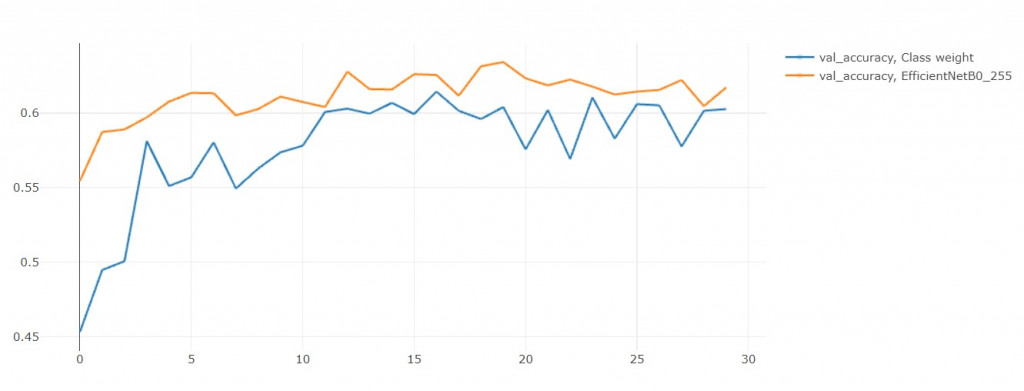
1. 验证集准确率
结果准确率居然降低了
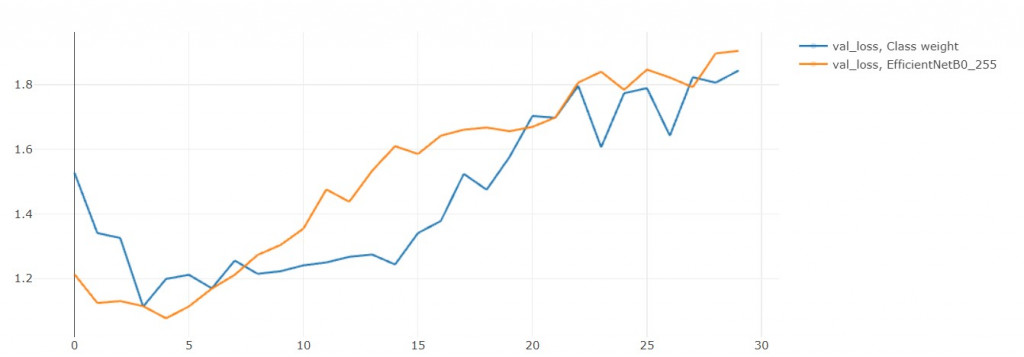
2. 验证集损失函数值
loss果然是降低了!
结语
虽然说验证集准确率降低了,
但不要忘记这是因为我们还没"训练完全",
从train_loss和val_loss的趋势来看: over fitting的现象减缓了,
如果再继续训练个10 epochs可能就能在acc上超越EFN_base了!
【图解演算法教学】一次搞懂「资料结构」与「演算法」到底是什麽?
Youtube连结:https://bit.ly/35x3dih 这次我们将精确定位出,在整个演算...
Day 25 - Watch os 开发学习2(Button)
今天我们继续学习watch os的开发。 正文 上面所展示的是按下Button之後会将下面的Text...
[Day 25] Edge Impulse + BLE Sense实现手势动作辨识(下)
=== 书接上回 [Day 24] Edge Impulse + BLE Sense实现手势动作辨识...
[Android Studio 30天自我挑战] 完赛心得
完赛心得 今天是铁人赛的最後一天, 一开始以为要写30篇的技术文章有点太难了, 为了写不一样的内容让...
JavaScript Day 8. 浅谈 Function-操作实例
上一篇大略的说明了 function 的两个大类别,这里试着放比较多的简易操作实例。 注册多组函式 ...