[Day 16] 我的资料哪有这麽平衡!第一季 (data augmentation)
前言
走过了资料分析、演算法选择後,
我们得知了有些可以改善模型的方向:
- 解决资料不平衡
- 学习率的设定
- 训练轮数
- 模型深度
- 阶段式训练
今天我要来着手处理资料不平衡的问题!
资料不平衡的原因有许多,
像是罕见疾病的资料(全世界只有10人拥有的疾病),
或是隐私性高的资料(信用卡刷卡资料)。
要解决这个问题,通常有两种选择:
- Over-sampling:把小类别的资料量补到和最大类别一样多。
缺点是容易over fitting - Under-sampling:把大类别的资料量砍到和最小类别一样少。
缺点是容易under fitting
资料增强(data augmentation)
资料增强就是增加资料的变化性并且增加资料量。
我用旋转、剪裁和缩放来创造出更多的图片
random_rotation:rg = Degree of rotation
random_shearintensity = Transformation intensity in degrees
random_zoom:zoom_range = Zoom range for (width, height).
- 注意:这里的影像变换是有顺序性的: 旋转 -> 错切 -> 缩放。
- 注意:这里的影像变换都是在一定范围内随机产生的,如果不设定随机种子,会每次都不一样。
def augmentation_image(img_array):
tf.random.set_seed(52671314) #设定随机种子
img_array = random_rotation(img_array, rg=30, channel_axis=2) # 旋转
img_array = random_shear(img_array, intensity=20, channel_axis=2) # 错切
img_array = random_zoom(img_array, zoom_range=(0.8, 0.8), channel_axis=2) # 缩放
return img_array
画出9张原图
samples = np.random.choice(len(X_train), 9)
fig, ax = plt.subplots(3, 3, figsize=(10, 10))
for i, image in enumerate(X_train[samples]):
plt.subplot(3, 3, i + 1)
plt.imshow(image.astype(np.float32)/255)
plt.title(
f"{int(y_train[samples][i])}: {emotions[int(y_train[samples][i])]}")
plt.axis("off")

资料增强後的图
fig, ax = plt.subplots(3, 3, figsize=(10, 10))
for i, image in enumerate(X_train[samples]):
image = augmentation_image(image)
plt.subplot(3, 3, i + 1)
plt.imshow(image.astype(np.float32)/255)
plt.title(
f"{int(y_train[samples][i])}: {emotions[int(y_train[samples][i])]}")
plt.axis("off")

数学原理
其实上面做的事情只是简单的矩阵运算!
复习矩阵运算请到均一教育平台,
上面有许多精彩的课程和点数机制让你"学"不释手。
另外,
我觉得这篇《图像的仿射变换》说得很好,
小弟我就不献丑了。
实验结果
我将X_train经过资料增强,
使每一个类别的数量都一样多(7类照片,每类7215张照片)。
扩大後的资料集称作X_train_all。
我用X_train_all训练模型,一样用X_val来验证模型。
训练出来的模型就叫做EFN_aug。
拿来和EFN_base(baseline)做比较:
| 模型 | 训练时长(秒) | acc | loss | val_acc | val_loss |
|---|---|---|---|---|---|
| EFN_aug | 4094 | 0.955 | 0.129 | 0.617 | 1.904 |
| EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905 |
1. 训练时长:
EFN_aug大概比EFN_base多花一倍的训练时间,
这是合理的,毕竟资料量也是两倍差不多。
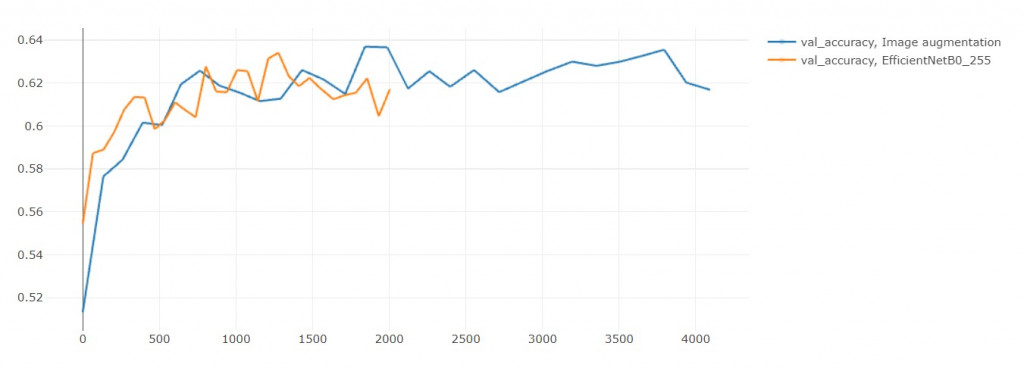
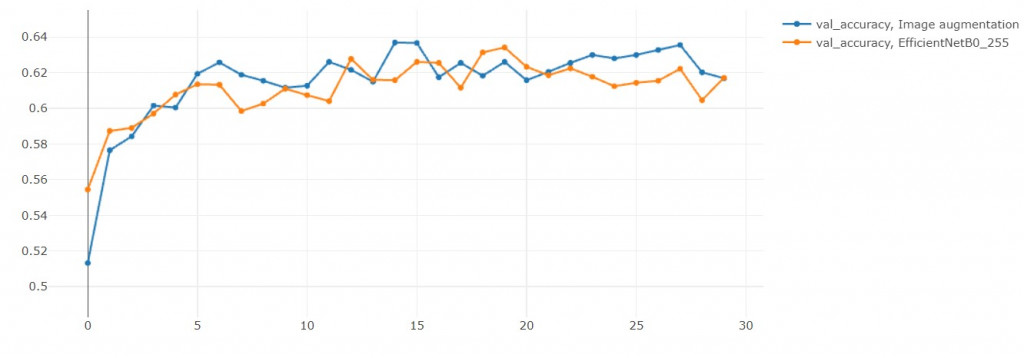
2. 验证集准确率
结果准确率没有提升
(但其实在第29轮是超越原本模型的)
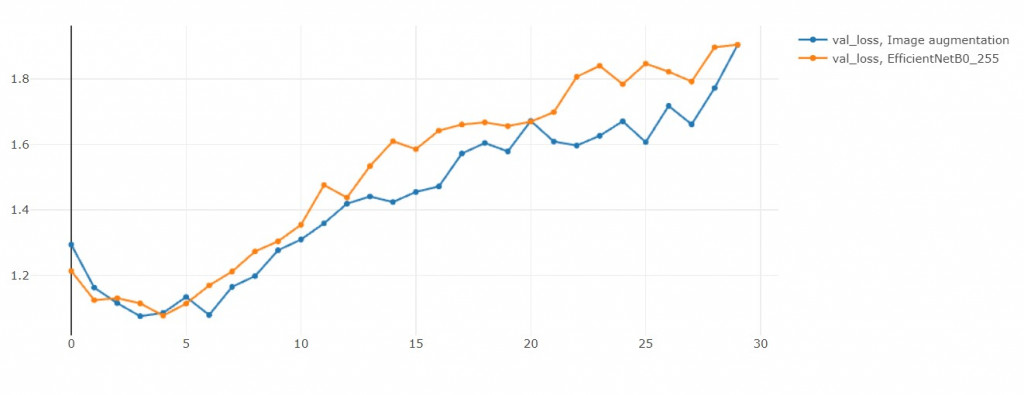
3. 验证集损失函数值
虽然说Over sampling会容易overfitting,
但是和EFN_base比起来,
EFN_AUG反而没有那麽overfitting。
这是个有趣的现象。
(或许我不小心增强出验证集的人脸)
结语
资料扩增有助於解决资料不平衡的问题,
但也要注意扩增时的情况合理性,
像是把人脸旋转180度就不合理(笑脸变成哭脸),
或是把扭曲到看不出人样,
也会使表情有所变化。
但是我需要花两倍的时间才能使Val_loss降低0.001,
这值得吗? 不值得
但有差吗? 没差!
训练一个模型从半小时变成一小时而已。
所以我还是会用这个技巧在实务上。
那有其他方法处理data imbalance吗?
有的!我们明天来介绍
Day 18 Sort
演算法在程序设计中扮演重要的角色,而演算法和时间复杂度有很大的关联, 时间复杂度本意为程序执行的时间...
追求JS小姊姊系列 Day5 -- 工具人登场
前情提要 突然出现在我身後的三人组是!郑列,方函式,阿物件 而三人中,站在最前方的就是郑列。 三人:...
18. 解释 JSONP 如何运作
(其实现在应该很少使用JSONP了,只是跟上一篇比较有关所以顺便整理,简单了解一下就好。) JSON...
Day13# defer
第 13 天要介绍 defer 是什麽,那麽我们就进入正题吧 ─=≡Σ(((っ゚∀゚)っ defer...
day6_Windows,Linux, MacOs 的虚拟化方案
什麽是虚拟化? 这里泛指模拟不同 os 与 cpu 架构的模拟器,所以包含小时候常玩的 GBA,GB...