爬虫怎麽爬 从零开始的爬虫自学 DAY16 html基本介绍
前言
各位早安,书接上回我们完成了 python 基本知识的介绍,今天我们要来介绍 html 也就是网页的编写语法
html 介绍
一样开启 VSCode
点选新增档案 只是这次档名取 index.html 就建立好 html 档了
建好之後要加入内容
html 是从上到下照顺序显示
并且由许多组标签构成
先给你们看最基本的结构
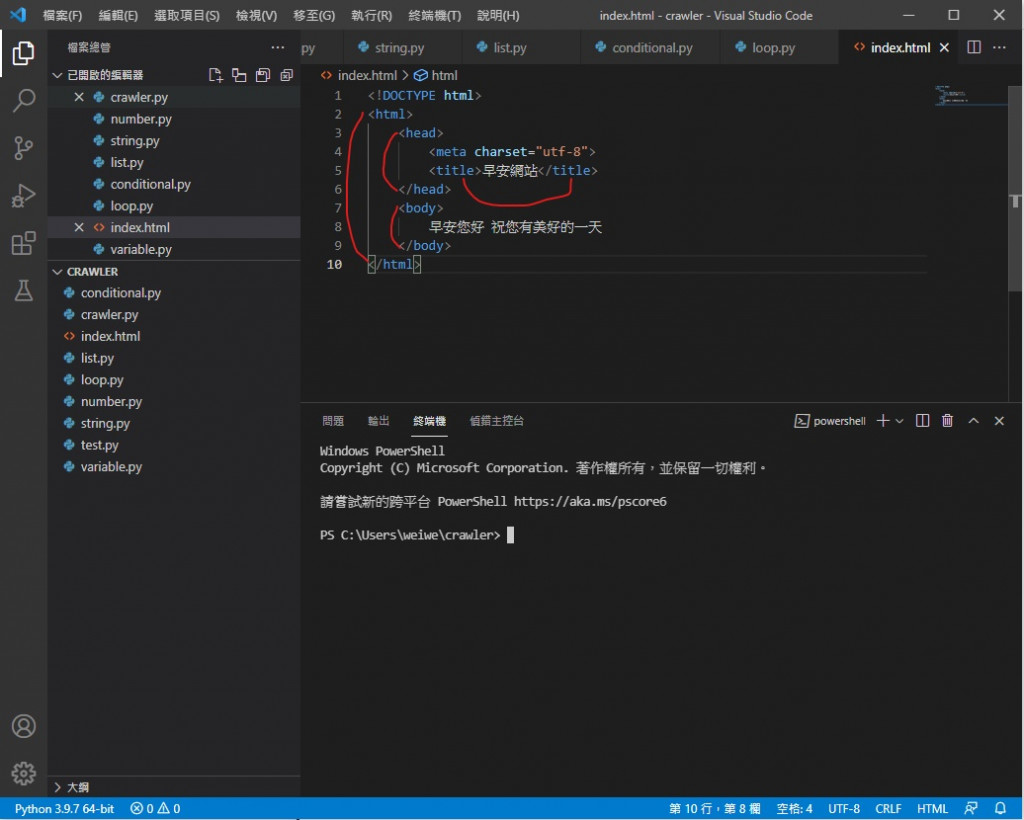
可以看到每组标签都有一个开始标签跟一个结束标签
标签由 < > (角括号)包住 结束标签会比开始标签在前面多一个 /
我们先讲如何看我们写出的网页
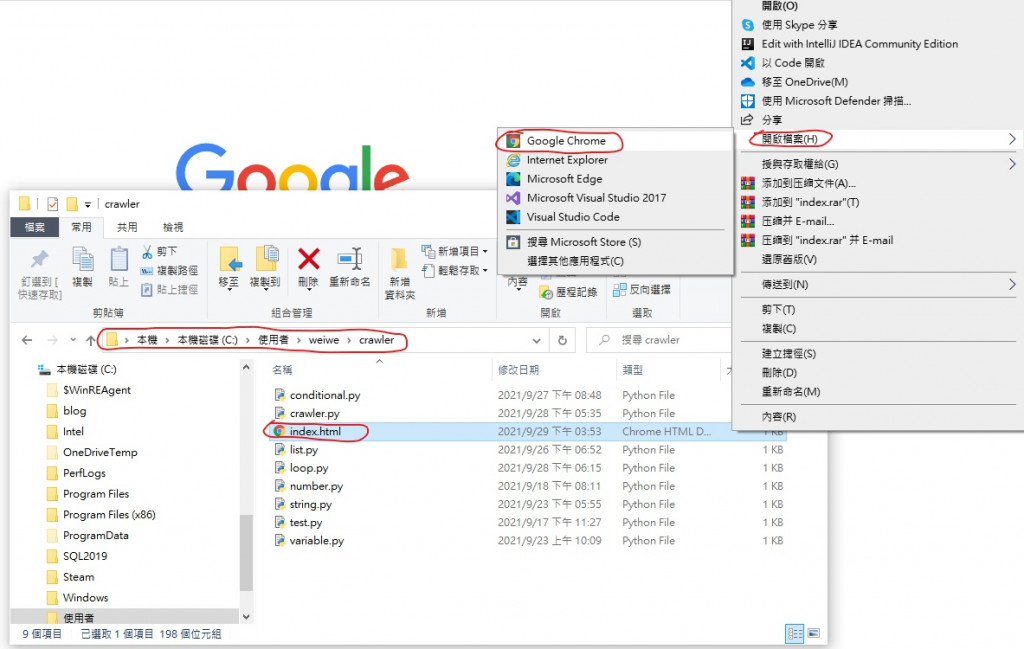
用我在图片中标示的方式打开就会看到我们刚刚写的网页 记得在 VSCode 先存档
打开长这样
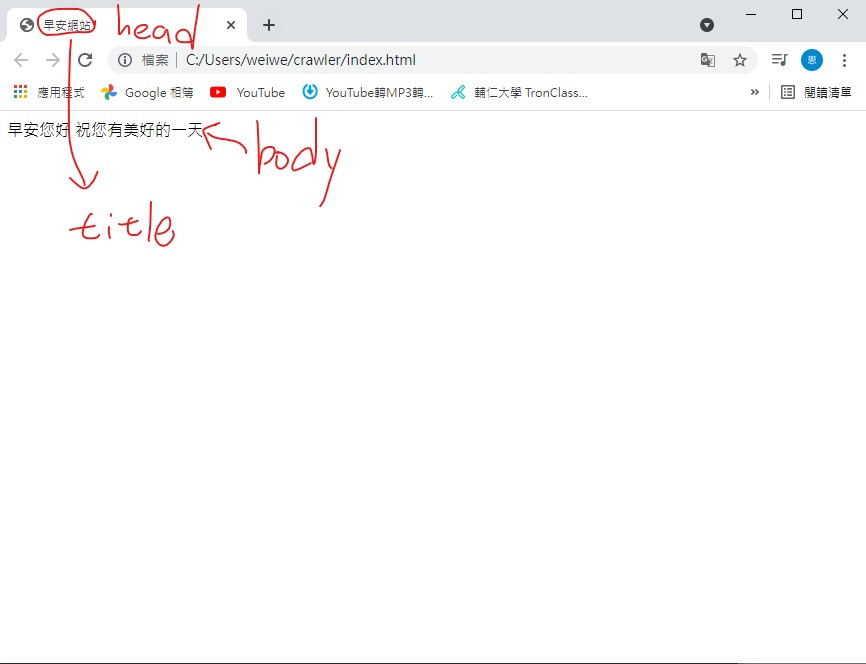
对应关系都标明在上面了
其他如下
第一行 <!DOCTYPE> 是告诉你的浏览器档案类型
下面由 < html > < /html > 包住的是网页内容
< meta > < /meta > 是告诉浏览器我们要用 UTF-8 编码方式
有缩排代表是在他的区块里面 例如: < title > 是在 < head > 里面的
html 是一层一层包住的 每个标签都一定有对应的结束标签
所以我们找资料的时候也是一层一层呼叫
有这个概念後基本上我们已经能大概知道我们到时候想抓取的资料位置在哪
html 的部分我就不细说了 剩下的明天我们实作爬虫的时候会再教大家怎麽看
目前为止我们已经掌握了python的程序基础 也对html有了基本的认识
明天我们终於可以迎来期盼已久的爬虫实作了 恭喜大家~
早安闲聊区
你知道吗?
多笑可以提升免疫力喔
每日二选一
你喜欢户外活动还是室内活动呢
最後的爬虫啦~
这篇应该是这次铁人赛中最後一次的’纯’爬虫啦!总之就是一而再、再而三地重复练习,使我能够更加熟悉爬虫...
强型闯入DenoLand[27] - Web API 介绍
强型闯入DenoLand[27] - Web API 介绍 终於来到本系列文的最终阶段 - Web...
Ruby幼幼班--Single Number
Single Number 黑魔法集合.... 题目连结:https://leetcode.com...
色码转换器再进化
前言 今天来优化 Day24 做的色码挑战器,主要增加的功能如下: 新增转换成RGBA 点选色码可以...
【day21】创建对象列表(下)
昨天我们已经按照时间去新增我们的资料了,也得到列表啦,那麽我们今天就要来建立点击事件,因为如果只有...