[Day29] BERT(二)
一. 预训练的BERT
接下来会介绍hugging face这个团队提供的BERT的套件来做介绍~BERT的model本质本来就是预训练模型。今天主要介绍 Bert 预训练模型的使用方法。
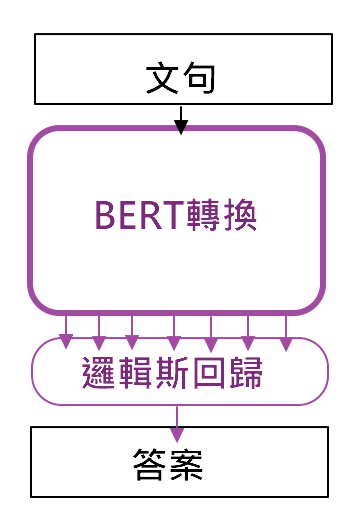
如下图,此图来自Coupy的'NLP 100天马拉松'的图,网路上有人利用BERT将句子转成编码,再经过自己设计好的分类器,如罗吉斯回归、LSTM都可以唷~~
二. 程序实现
接下来我们载入google 的 BERT,并利用他来转换成句子的编码
- 载入套件
import numpy as np
import pandas as pd
import torch
import transformers as ppb # pytorch transformers
- bert 的config设定
configuration = ppb.BertConfig()
configuration
输出後如下图:

- 文字前处理,以句子'为什麽圣结石会被酸而这群人不会'为例
def tokenize(text):
text = re.sub('[^\u4e00-\u9fa5A-Za-z0-9]','',text)
return text
text = '为什麽圣结石会被酸而这群人不会'
train_text = tokenize(text)
- 载入pre-trained model
# 载入 Bert 模型
model_class, tokenizer_class, pretrained_weights = (ppb.BertModel(configuration), ppb.BertTokenizer, 'bert-base-chinese')
# 载入预训练权重以及 tokenizer
tokenizer = tokenizer_class.from_pretrained(pretrained_weights)
model = model_class.from_pretrained(pretrained_weights)
- 将句子里的词编号:
max_len = 32
train_text = tokenizer.encode(train_text, add_special_tokens=True, max_length=max_len, truncation=True, padding=True)
train_text
输出後如下图:

- BERT的输入需要有input_idx(上一步)、padding的idx(後面补0)、attention mask(要做attention的词设为1,padding的词设为0):
padded = np.array([train_text + [0]*(max_len-len(train_text))])
attention_mask = np.where(padded != 0, 1, 0)
input_ids = torch.tensor(padded).to(torch.int64)
attention_mask = torch.tensor(attention_mask).to(torch.int64)
with torch.no_grad():
last_hidden_states = model(input_ids, attention_mask=attention_mask)
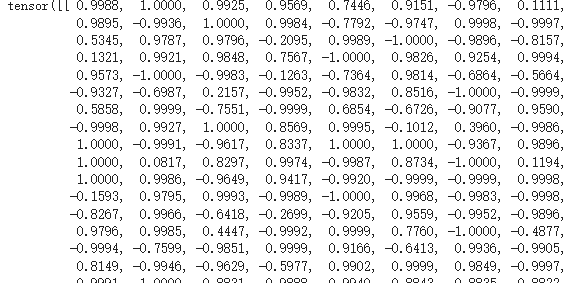
- 最後将'为什麽圣结石会被酸而这群人不会'进行编码,通常是取pooler_output作为句子的编码,如下:
last_hidden_states.pooler_output
output,编码为768维度的向量:
bert其实对於句子的编码语意理解那边是不太好,满多人推荐SBERT这个方法,有兴趣可以查一下唷~~
[24] 用 python 刷 Leetcode: 66 plus-one
原始题目 You are given a large integer represented as ...
Day22 Vue 认识Porps(1)
在之前的铁人赛中我们知道了元件的实体状态、模板等作作用范围都应该要是独立的,意味这子元件是无法修改父...
[Day12] - Django REST Framework 专案建立
我们透过 Docker Compose 建立环境,并在其上建立Django REST Framewo...
30-20 之 Domain Layer - UnitOfWork
接下来这篇我们要来谈谈,我个人觉得很重要的 UnitOfWork,这个东西很多人知道要,但是应该也不...
#21 JS: Object - Constructors
About Constructors “The way to create an 'object t...