【15】图片标准化 [0,1] 与 [-1,+1] 的差别实验
昨天我们实验了有无做 Normalization 的差异,但我在 stackoverflow 刚好看到一篇精彩的讨论,主要争论的点是我应该把图片 Normalization 到 [0,+1] 还是 [-1,+1] 的讨论,把数值缩放到 [-1,+1] 的原因有这麽做平均值接近0且标准差接近1,其中有个讨论是如果范围有负值,那会不会受到 relu 的影响,导致大部分的数值变成0呢?
这部分是不需要担心的,因为我们的 activation 会在CNN或Dense之後,所以原先 input 是负值是有机会乘上权重後变成正值的(即权重也是负值,负负得正),因此不必担心此问题。
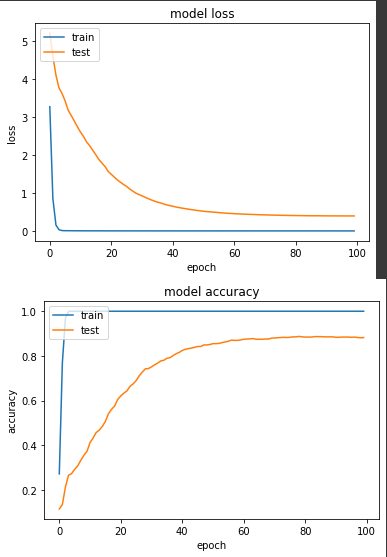
实验一:老样子将范围缩到 [0,+1]
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image /255., label. # [0, +1]
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 3.6361e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.3945 - val_sparse_categorical_accuracy: 0.8824
实验二:范围缩到 [-1, +1]
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return (image - 127.5) / 127.5, label
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 4.3770e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4737 - val_sparse_categorical_accuracy: 0.8735
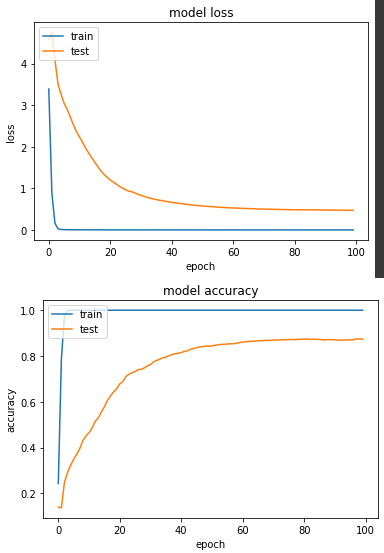
从结论来看,[0,1] 得准确度比 [-1,+1] 来得高一点点,以我自己的实务经验来说,我普遍都是缩成[-1,+1],但也看过不少开源程序码是[0,1],故两者无多大区别。
<<: [Day29] CH13:画出你的藏宝图——事件处理(下)
>>: Day 15:101. Symmetric Tree
Day-26 如何快速解决Excel乱码问题?
今日练习档 ԅ( ¯་། ¯ԅ) 你是否在网路上下载CSV档并使用Excel开启时档案内容变成乱码呢...
Day14 老人护眼模式
Zoom 你是不是常常有看东西觉得模糊需要放大镜呢?今天要来介绍完整的图表的放大、缩小、以及拖曳平...
Day11-Database——效能的储备足够吗?-N+1 query
标题参考来源 大家好~ 今天来简单认识一下 N+1 query 吧! 什麽是 N+1 query 呢...
快乐很简单,但要简单却很难。
快乐很简单,但要简单却很难。 It is very simple to be happy, but ...
远端系列-5:如何拉回远端数据库的档案?
角色情境 小明同时学会输入指令操作着终端机、 以及透过滑鼠操作着图像化介面的 Sourcetree ...