DAY 17 Big Data 5Vs – Variety(速度) Glue Data Brew
目前为止Glue的三个工具,可以依使用者的开发习惯与技术背景来选用,而AWS是以客户为导向的公司,对於越来越多跨领域的人才都要希望能够善加应用手中资料的需求下,AWS也应运而生了另一个服务—Glue Data Brew,让使用者只要带着资料来,就可以在不需要编撰任何程序码的情况下,利用AWS积年累月资料经验所提供建立的250个内建ETL范本,将资料清洗成符合自己使用需求的资料集,方便接下来的分析与机器学习建模使用。

基本元件介绍:
Project专案:进入服务业面可以在右方先建立专案,建立时选定Dataset,选择Recipe
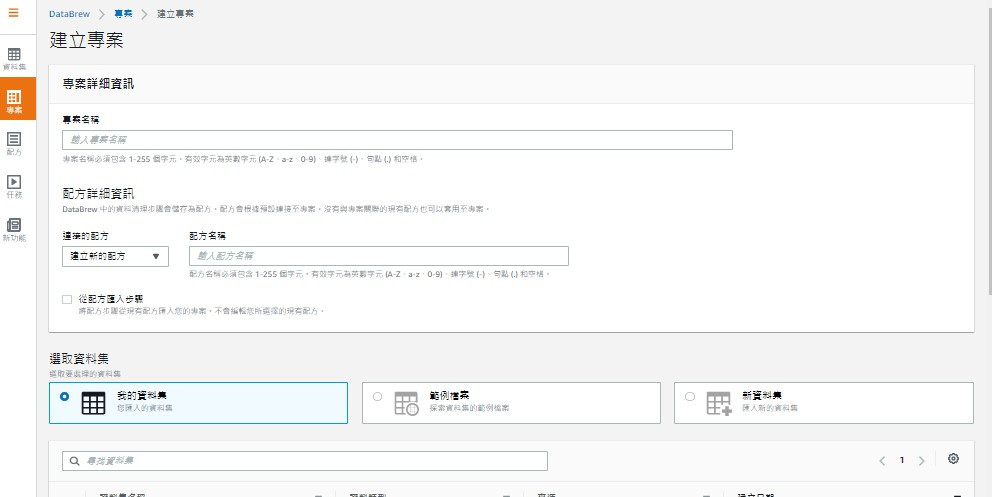
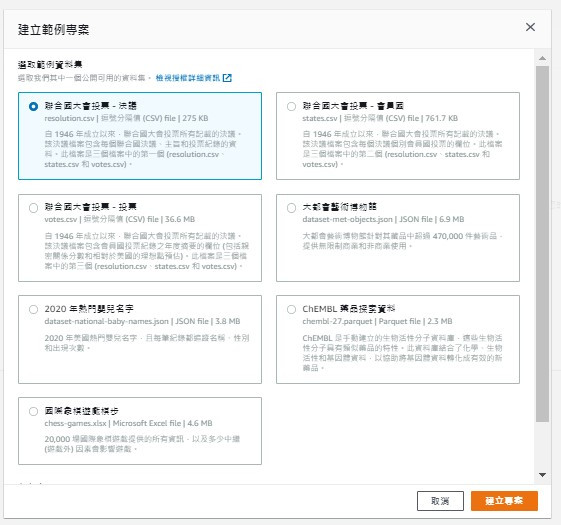
或是直接选择建立内建的范本专案
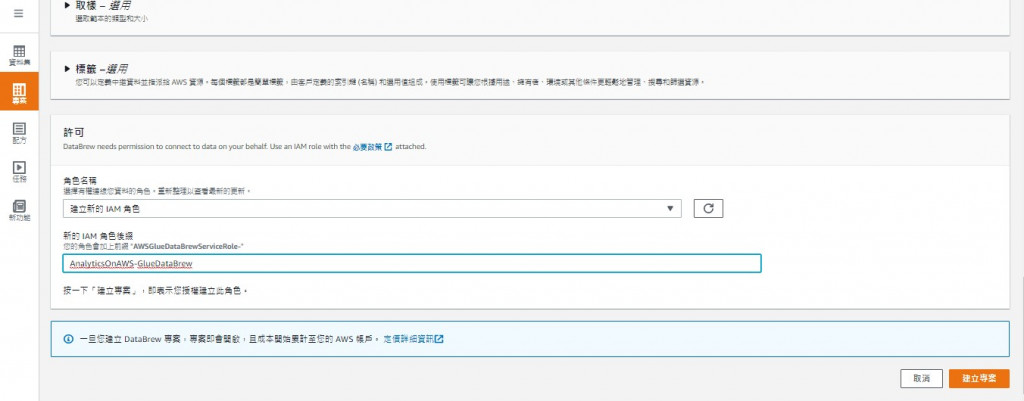
记得选用的role需要拥有相关资源的权限(例如S3)
Dataset:与data catalog一样并没有实际存有资料本身,而是记录着metadata
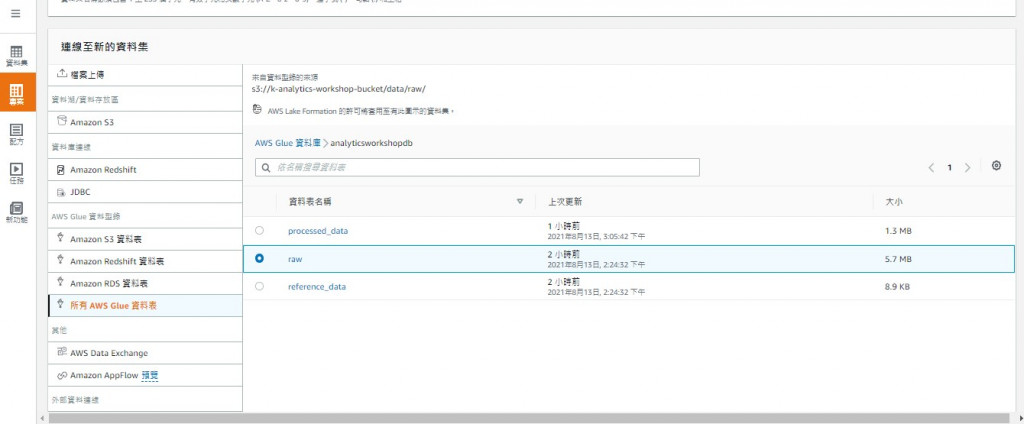
也可以从本地上传
Recipe:是一步步资料处理流程的集合,如果不使用范本也可以上传自己编写的版本,或是修改范本让资料能清洗成更符合自己所需的样子。注意上传档案须是JSON档。
Job:Recipe的执行实例,可以按需执行
两个值得一提的功能是:
Data lineage:视觉化呈现资料流,可以追踪资料处理的状态进度
Data profile:提供基本资料轮廓的叙述统计资讯,类似pandas的describe功能
花了许多篇幅介绍资料处理工具,因为资料清洗是个非常关键却又耗时的过程,资料清洗的程度与否直接影响着分析结果,所以常常是一个资料分析系统中的痛点,不只是Glue Data Brew,市面上也有许多其它为了解决这个问题而产生的工具,例如Informatica、Tableau Prep等
但Glue所适用的资料量大约1TB左右,如果要处理更大量(可能10TB以上)的资料,就需要另一个更强壮的服务 — Amazon EMR。明天做介绍。
<<: Day 0x1C UVa10420 List of Conquests
>>: Windows Server 2019 如何安装 Mail Server,使用 hMailServer 来管理收发信
Day28 - HTML 与 CSS (10) - 网页设计
网页设计 环境:将多页面的档案建立,连结确认彼此间的关系 layout (布局):评估多个页面皆会出...
Day 17 | Flutter的常用 widgets - Container、Row、Column
StatefulWidget 的build 回到昨天 StatefulWidget 的 build ...
【第十天 - Two-pointer 介绍】
Q1. Two-pointer 是什麽? 我个人认为双指标 ( Two-pointer ) 比较像写...
硬碟管理实作
昨天介绍完硬碟管理,来实作吧~ TIPS: Array在unRaid指的是资料池,并非POOL(在u...
[今晚我想来点 Express 佐 MVC 分层架构] DAY 30 - 是结束,也是开始
补充 经过这 30 天的考验(?),如果对 Express 与 MVC 架构情有独锺,又对 Type...