GPU程序设计(3) -- 矩阵运算
前言
GPU卡原来是针对游戏开发及显示加速的设计的,後来才扩散至挖矿、深度学习...等其他领域,而游戏内的物件移动、旋转都是依靠矩阵运算达成的,因此,我们就来看看如何使用GPU进行矩阵运算。
多执行绪的设定
之前 <<<...>>> 都是设定为整数,为方便3D动画的处理,CUDA允许定义为3维的结构(x/y/z),区块也是一样,程序码如下,x=5, y=4, z=1:
dim3 dimBlock(5, 4, 1);
gpu_inner_product <<<1, dimBlock >>> (d_a, d_b, d_result);
第一个参数也可以是3维的结构,称为Grid。
z=1 亦即 2D 的概念。
矩阵相乘
矩阵相乘,通常称为点积(Dot product)或内积(Inner product),算法如下图:
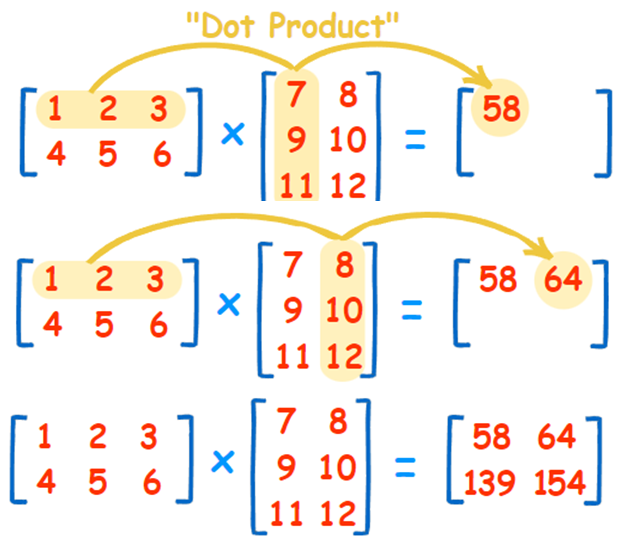
图三. 矩阵点积(Dot product),图片来源:『How to Multiply Matrices』
简单的讲,就是输出所在的格子是第一个输入矩阵的【列】与第二个输入矩阵的【行】点积的结果,因此,程序撰写如下:
- 定义两个输入矩阵的列数及行数:
#define A_ROW_SIZE 5
#define A_COLUMN_SIZE 4
#define B_ROW_SIZE 4
#define B_COLUMN_SIZE 3
- 矩阵计算:
// 输出所在格子的座标
int row = threadIdx.x;
int col = threadIdx.y;
// 点积
for (int k = 0; k < A_COLUMN_SIZE; k++)
{
// 第一个输入矩阵的【列】与第二个输入矩阵的【行】相乘
d_c[row * B_COLUMN_SIZE + col] += d_a[row * A_COLUMN_SIZE + k] *
d_b[k * B_COLUMN_SIZE + col];
}
透过多维执行绪的设定,就可以免除2D/3D转为1D的计算,只可惜一个区块最大执行绪只有1024,碰到较大的矩阵还是会爆掉,不过,还是可以解决,只是比较麻烦一点,读者可以想想看,笔者的想法放在文末。
结语
完整程序放在『GitHub』的InnerProduct目录。
神网路经的矩阵尺寸通常非常大,例如MNIST,60000笔资料,每笔28x28个像素,相乘起来一定超过1024的限制,因此,每个执行绪就必须负责一个区块的计算,而不仅仅是单格而已,这时就可以使用区块的多维设定,可以参阅『CUDA - Matrix Multiplication』说明。
我们的基因体时代-AI, Data和生物资讯 Day02- 机器学习在生物资讯中之应用
上一篇我们的基因体时代-AI, Data和生物资讯 Day01- 超越摩尔定律的资料增长介绍了生医领...
Day21 - 【概念篇】在Flow这段小旅途外的风景
本系列文之後也会置於个人网站 在这一小段路中介绍了Password Flow、Implicit F...
Day1-介绍与开始
嗨大家好~我是凯西!接下来是我开学的三十天实力增进计画的纪录 规划上会刷leetcode加强我的py...
介绍RESTful api(Day9)
RESTful api是什麽 在网路上有蛮多说明他的内容,我觉得API 是什麽? RESTful A...
Day9: MFA启用、IAM Access Analyzer
上篇我们讲到在AWS Console 里面如何建立role以及Policy,今天我们来看如何启用MF...