[Day 14] 多棵决策树更厉害:随机森林 (Random forest)
随机森林 (Random forest)
今日学习目标
- 随机森林介绍
- 随机森林的树是如何生成?随机森林的优点?
- 随机森林如何处理分类问题?
- 随机森林如何处理回归问题?
- 实作随机森林分类器
- 比较随机森林与决策树两者差别。
随机森林
随机森林其实就是进阶版的决策树,所谓的森林就是由很多棵决策树所组成。随机森林是使用 Bagging 加上随机特徵采样的方法所产生出来的整体学习演算法。还记得在前几天的决策树演算法中,当模型的树最大深度设定太大的话容易让模型过拟合。因此随机森林藉由多棵不同树的概念所组成,让结果比较不容易过度拟合,并使得预测能力更提升。
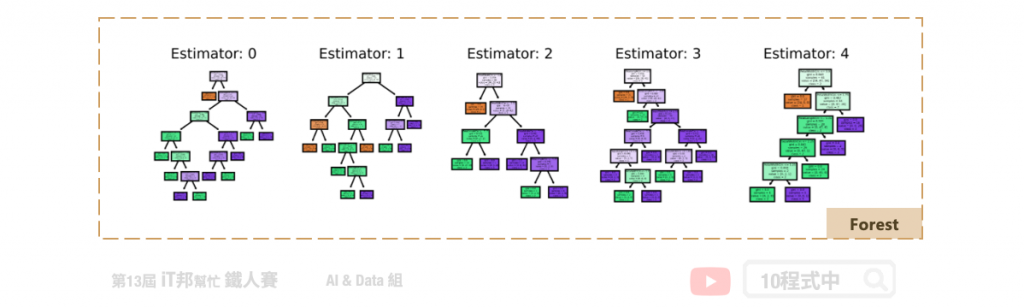
随机森林的生成方法
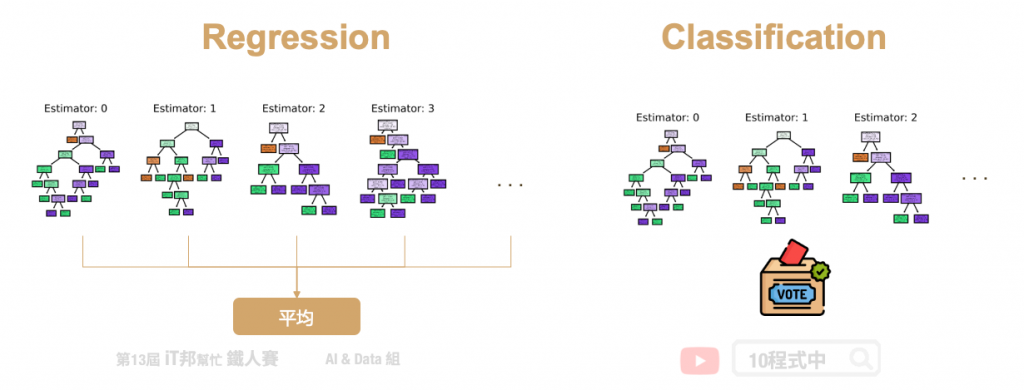
首先从训练集中抽取 n’ 笔资料出来,然而这 n’ 笔资料是可以被重复抽取的。假设我们有一千笔资料我们要从中抽取 100 笔资料出来,这 100 笔资料里面可能会有重复的数据。接着第二步从这些抽取出来的资料中挑选 k 个特徵当作决策因子的後选,因此每一棵树只能看见部分的特徵。第三步重复以上步骤 m 次并产生 m 棵决策树。透过 Bootstrap 步骤重复 m 次,做完之後我们会有 m 组的训练资料,每一组训练资料内都有 n’ 笔资料。最後再透过每棵树的决策并采多数决投票的方式,决定最终预测的类别。因为随机森林每一棵树的特徵数量可能都不同,所以最後决策出来的结果都会不一样。最後再根据任务的不同来做回归或是分类的问题,如果是回归问题我们就将这些决策数的输出做平均得到最後答案,若是分类问题我们则用投标采多数决的方式来整合所有树预测的结果。
- 从训练集中抽取 n’ 笔资料出来
- n’ 笔资料随机挑选 k 个特徵做样本
- 重复 m 次,产生 m 棵决策树
- 分类: 多数投票机制进行预测、回归: 平均机制进行预测
随机森林中的随机?
随机森林中的随机有两种方面可以解释。首先第一个是随机取样,在模型训练的过程中每棵树的生成都会先从训练集中随机抽取 n’ 笔资料出来,而这 n’ 笔资料是可以被重复抽取的。此抽取资料的方式又称为 Bootstrap,它是一种在统计学上常用的资料估计方法。第二个解释随机的理由是在随机森林中每一棵树都是随机的特徵选取。每一棵树都是从 n’ 笔资料中随机挑选 k 个特徵做样本。
在 sklearn 中,最多随机选取 log2N 个特徵
随机森林的优点
- 每棵树会用到哪些训练资料及特徵都是由随机决定
- 采用多个决策树的投票机制来改善决策树
- 与决策树相比,不容易过度拟合
- 随机森林每一棵树都是独立的
- 训练或是预测的阶段每一棵树都能平行化的运行
[程序实作]
随机森林(分类器)
Parameters:
- n_estimators: 森林中树木的数量,预设=100。
- max_features: 划分时考虑的最大特徵数,预设auto。
- criterion: 乱度的评估标准,gini/entropy。预设为gini。
- max_depth: 树的最大深度。
- splitter: 特徵划分点选择标准,best/random。预设为best。
- random_state: 乱数种子,确保每次训练结果都一样,splitter=random 才有用。
- min_samples_split: 至少有多少资料才能再分
- min_samples_leaf: 分完至少有多少资料才能分
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
- get_depth: 取得树的深度。
from sklearn.ensemble import RandomForestClassifier
# 建立 Random Forest Classifier 模型
randomForestModel = RandomForestClassifier(n_estimators=100, criterion = 'gini')
# 使用训练资料训练模型
randomForestModel.fit(X_train, y_train)
# 使用训练资料预测分类
predicted = randomForestModel.predict(X_train)
使用Score评估模型
我们可以直接呼叫 score() 直接计算模型预测的准确率。
# 预测成功的比例
print('训练集: ',randomForestModel.score(X_train,y_train))
print('测试集: ',randomForestModel.score(X_test,y_test))
输出结果:
训练集: 1.0
测试集: 0.8888888888888888
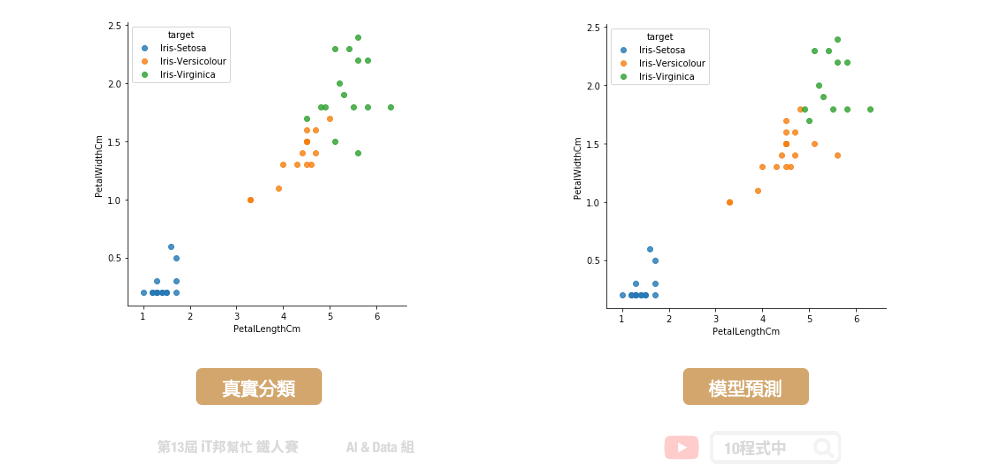
我们可以查看训练好的模型在测试集上的预测能力,下图中左边的是测试集的真实分类,右边的是模型预测的分类结果。由於训练资料笔数不多,因此模型训练容易过度拟合训练集的分布。最终在测试及预测的表现上仅有 0.88 的准确率。
特徵重要程度
只要是决策树系列演算法,不管是分类器或是回归器都能透过 feature_importances_ 来检视模型预测对於特徵的重要程度。
print('特徵重要程度: ',randomForestModel.feature_importances_)
输出结果:
特徵重要程度: [0.09864249 0.01363871 0.44211602 0.44560278]
随机森林(回归器)
Parameters:
- n_estimators: 森林中树木的数量,预设=100。
- max_features: 划分时考虑的最大特徵数,预设auto。
- criterion: 评估切割点指标,mse/mae。
- max_depth: 树的最大深度。
- splitter: 特徵划分点选择标准,best/random。预设为best。
- random_state: 乱数种子,确保每次训练结果都一样,splitter=random 才有用。
- min_samples_split: 至少有多少资料才能再分
- min_samples_leaf: 分完至少有多少资料才能分
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测。
- score: 预测成功的比例。
- get_depth: 取得树的深度。
from sklearn.ensemble import RandomForestRegressor
# 建立RandomForestRegressor模型
randomForestModel = RandomForestRegressor(n_estimators=100, criterion = 'mse')
# 使用训练资料训练模型
randomForestModel.fit(x, y)
# 使用训练资料预测
predicted=randomForestModel.predict(x)
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: Day 0x10 - 整理解密函数与 Webhook api
>>: #26 JS: HTML DOM Events - Part 4(Start Over Version)
[Android Studio 30天自我挑战] ImageView元件介绍
现在在手机或是平板上都会许多图片的应用,这次介绍ImageView与ImageButton这两个元件...
存放资料的 state、module
在 JavaScript 中,储存资料的方式,长这样。 { name: 'Chris', age: ...
Day19 Lab 2 - Object storage 数据校验和去重
本篇我们会分两部分 - 校验和去重 前面讲到的Metadata,如果有了Metadata,我们可以做...
Day19 NodeJS-Express IV
前一篇说明了Express中的样板引擎与样板的使用,是比较偏向前端的部份,今天的主题是前端和後端资料...
【第十九天 - Flutter Firebase Dynamic Links】
前言 今日想要介绍 Deep Link,这边我只有接收 deeplink 的连结实作,并没有使用动态...