Day.18 Graph-BFS
BFS是简写,全名是Breadth-First Search(广度优先搜寻演算法)
BFS跟DFS一样,也是搜寻的演算法,一样是很常见哦!
DFS是以深度为优先,每一条路都会搜寻到尽头,BFS的做法不一样是以广度优先,会把旁边的都搜寻完再扩散出去。
来看一下图:
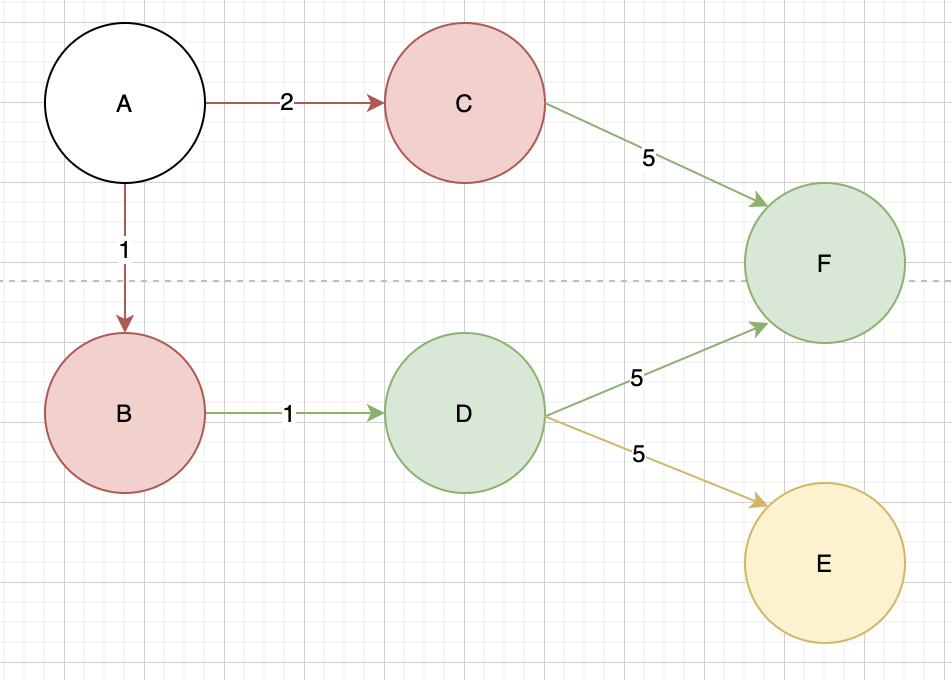
一样是从A作为起点,先把旁边的都走完,再往外去找。
A先找到B、C(红),走完了再往外找,B下一个是D(绿),C下一个是F(绿),最後D再走到E(黄)
我们需要来一个Queue,来记录接下来要走的顶点,把每一个要走的顶点放到Queue里面,再用一个index去控制顺序。
ex:
我先从A点开始走
queue: [A]
index: 0
A会先遇到B、C,再没有边了,就把index++
queue: [A,B,C]
index: 1
再从顶点B的边去搜寻,找到D,最後一样把index++
queue: [A,B,C,D]
index: 2
再重复这个过程,把每一个顶点的边走完就可以了~
程序:
func (g *Graph) BFS(target *Vertex) {
visted := g.getVistedVertex() // 用来记录走过的顶点
visted[target] = true
queue := []*Vertex{
target,
}
index := 0
for index < len(queue) {
for _, edge := range g.adjList[queue[index]] {
if !visted[edge.Vertex] {
fmt.Printf("vist: %v \n", edge.Vertex.Name)
queue = append(queue, edge.Vertex)
visted[edge.Vertex] = true
}
}
index++
}
}
func main() {
a := &Vertex{
Name: "A",
}
b := &Vertex{
Name: "B",
}
c := &Vertex{
Name: "C",
}
d := &Vertex{
Name: "D",
}
e := &Vertex{
Name: "E",
}
f := &Vertex{
Name: "F",
}
g := newGraph()
g.AddVertex(a)
g.AddVertex(b)
g.AddVertex(c)
g.AddVertex(d)
g.AddVertex(e)
g.AddVertex(f)
// A的边
g.AddEage(a, b, 1)
g.AddEage(a, c, 2)
// B的边
g.AddEage(b, d, 1)
// C的边
g.AddEage(c, f, 5)
// D的边
g.AddEage(d, e, 5)
g.AddEage(d, f, 6)
g.BFS(a)
}
output:
vist: B
vist: C
vist: D
vist: F
vist: E
一般情境来说用BFS跟DFS都可以解决问题
BFS比DFS要用更多的记忆体,因为多一个Queue去记顶点,如果要省记忆体可以用DFS
如果是要找目标附近的东西,用BFS会比较适合~
明天来讲最短路径~
>>: Day 13 AWS云端实作起手式第三弹 开始拼拼图吧
Day 21 - SwiftUI开发学习5(文字填入)
今天我们来学习如何使用填入文字的物件 正文 文字填入 TextField 可以将文字填入进去。 如果...
[Kata] Clojure - Day 27
Recursion 101 In this Kata, you will be given two ...
就决定是你了 - 阵列系列III
来到阵列系列的最後一天,今天要一次认识会改变原本阵列的Array Method,再往下看之前,先来个...
LeetCode 双刀流:53. Maximum Subarray
53. Maximum Subarray 接下来我们挑 53. Maximum Subarray ...
修改 DOM 元素样式
在网页的互动效果中,常常是当使用者符合了某个条件时,画面上的元素产生令人惊喜的变化,这些变化可简单可...