Day.18 InnoDB资料储存 - 主索引架构 (Clustered Index)
在设计资料表的过程中索引的设计会跟查询效率有直接的关系,随着数据量的增加一条查询SQL语句有无吃到index对执行上的效率差异是明显可见的。
套用索引最常看到的比喻,index(索引)就像是书的目录。
有了目录你就能根据上面定位好的页数纪录去找到对应资料,相反的没有这些目录,你就得慢慢的去找到你要的内容(全表扫描)。
MySQL数据路径底下的资料库档案内可以看到,InnoDB储存资料库资料有3个档案分别为:
-
db.opt
.opt档纪录该资料库预设字符集编码和字符集排序规则。 -
table_name.frm
.frm档存放这个表的相关资料(表结构定义)资讯。 -
table_name.ibd
.ibd档存放这个表的资料与索引内容。
InnoDB表资料档案本身就是按B+Tree组织的主索引结构,资料与索引的储存以Clustered Index来聚集组织。
InnoDB将索引分成Cluster Index & Secondary Index
-
聚集索引 Clustered Index (primary Index) 是什麽?

-
先看MySQL如何选择Clustered key规则:
-
建表时有primary key,选primary key。
-
没有primary key的话,选第一个not null的unique key。
-
以上都没有,产生一个auto increment的隐藏栏位做clustered key。
-
每个表只会有一个Clustered Index(表纪录只能用一种物理顺序存放)
-
-
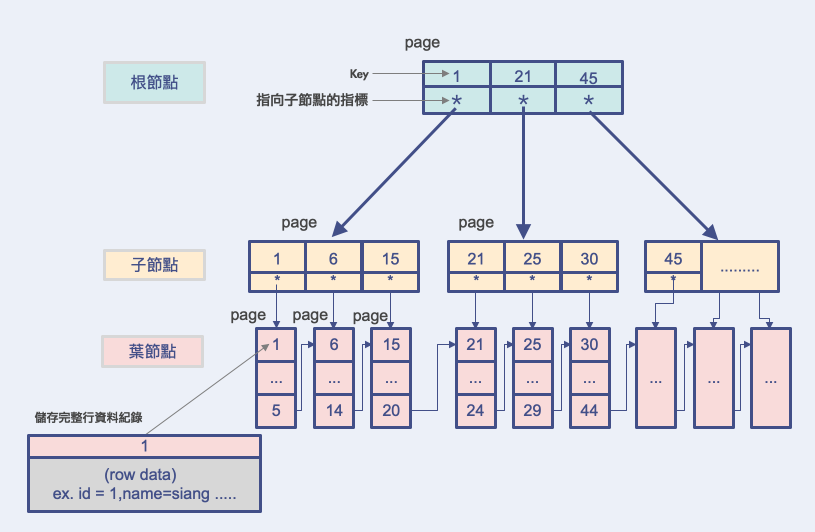
InnoDB采用B+Tree来作为组织实现储存资料的主索引结构,用以下图来解释~
-
leaf node(叶节点) 真正存资料的地方
储存主键值的row data和一个指向相邻节点的指标。 -
非叶节点
储存key的值和指向child node的指标,作用在定位到具体的纪录位置。 -
左闭合区间查询
查询资料采用左闭合区间查询。 ex.[a,b) =包含a但不包含b的区间范围。
-
-
运作逻辑:
还记得在前面InnoDB架构介绍时有提到资料与索引都是储存在磁碟中的,要使用的话会先将资料所在的page载入内存中才进行动作。内存和磁盘以page为单位交换资料!!
那问题来了当数据量大的时候,索引档案的大小可能会很大,总不能直接用一次性的载入memory,所以在资料查询时会分多次磁碟IO逐一加载disk page(对应B+tree的node),将索引相关资料分批载入memory。从根节点开始逐层索引到叶节点後返回资料。
-
Page
InnoDB磁盘管理的最小储存单位。page default: 16KB <-最多存放16KB的资料 -
针对B+Tree架构整理以下特点:
- Clustered Index: 决定了资料的分布。换句话来说当表的建立起来後,资料表中的资料排序方式会依照clustered index 的key值来排序。
引用官方叙述
If index records are inserted in a sequential order (ascending or descending), the resulting index pages are about 15/16 full. If records are inserted in a random order, the pages are from 1/2 to 15/16 full.
可见存放资料时不会把全page空间都用完,而是保留一部分做日後的新增更新。纪录循序插入page维持在约15/16满,纪录乱序插入的话page维持在约1/2~15/16满。
- 主键值的有序与无序影响塞资料的效能和page空间使用率
上面提到资料会按照主键值顺序存放,对於有序主键值(ex.自增ID)来说,当我们新增一笔资料时,mysql根据主键值将其插入当前索引节点的後续位置,不需做额外的搬动,当page到达(15/16)後,开一个新page存放资料。那当使用(值不重复的随机值PK)就会遇到需要插入到现有page的某个位置,造成page之间的资料搬动,增加效能上的开销。
以上图B+tree结构举例来说,当我要查找ID=26的这笔资料
第一次IO:
- 将根节点page载入内存判断主索引值位於哪个子节点page。
- 范围: (21<= 26 <45) -> 走中间线到子节点的第二个page
第二次IO:
- 取出子节点的第二个page,载入内存中判断。
- 范围: (25<= 26 <30) -> 走中间线到达存放资料所在的叶节点page
第三次IO:
- 取出叶节点资料所在page,载入内存中。
- 命中 ID= 26 这笔纪录返回。
看完以上内容对於InnoDB主索引架构有了基本的认识,有一个部分在这篇我没提到,有兴趣可以去看看~就是MySQL为何选择了B+Tree? B+tree & B-tree差异在哪?
像是针对只有叶节点才存放资料的特性可以比对出以下差异~
-
(B+tree)在子节点上因为没有存放资料,所以在一个page 16K限制下相比(B-tree)能存放更多的key,B+tree磁碟读写更好,一次的IO载入资料量更多。
-
(B+tree) key相关的资料只存在叶节点上,保证查询的稳定,都要到达叶节点後才拿得到资料。而(B-tree)在子节点中存放资料,命中key就能拿到资料。
明天来介绍Secondary Index~
<<: [Angular] Day26. Reactive forms (二)
android studio 30天学习笔记-day 16-databinding Recyclerview
今天会使用databinding的方式去实作一个Recyclerview。 建立model publ...
[Day14] 团队系统设计 - 重塑 Planning 会议
本篇文章来介绍「规画系统」(Planning System) 中的:Planning 会议。我相信熟...
26 - MarkdownLint - Lint Markdown 文件
Markdown 格式不需要编辑器添加任何的支援就可以撰写,利用简单的语法就可以定义各种样式,是现今...
[用 Python 解 LeetCode] (003) 80. Remove Duplicates from Sorted Array II
题干懒人包 给定一个排列好的列表,将它整理成重复项最多出现两次,比方说以下 [1,1,1,2,2,3...
Day 23 - 开发人员工具的日常
前言 今天再来聊聊另一个重要的工具,是很多人刚开始学 Javascript 就一路接触到现在,如果没...