心血管疾病notebook使用MLFlow做记录
上一篇我们已经完成心血管疾病资料的训练并且产生model档. 本篇我们再来加入MLflow的功能, 练习一下要怎麽将每次训练的参数、metric与model记录起来.
在心血管疾病的范中, Tracking功能仍然使用MLFlow进行说明
这份notebook可以从下方连结下载:
https://github.com/masonwu1762/ithome-ironman
- notebook: cardiovascular_disease_prediction_notebook_mlfow.ipynb
- dataset: cardio_train.csv
在上一篇notebook的最後我们继续加上下列内容
首先我们先装mlflow, 好让我们可以在notebook呼叫mlflow的程序库.
!pip install mlflow
接着指mlflow import进来
# Import mlflow
import mlflow
import mlflow.sklearn
接着我们要呼叫set_tracking_uri函式并设定MLFlow的IP与port, 这样才能我们才能将想要log起来的资料传到指定的MLFlow server.
在Day7已安装好MLFlow server , 而且在Day8的内容中已说明过MLFlow可支援的四种uri的格式, 请再参考Day7与Day8的内容
mlflow.set_tracking_uri("http://172.23.180.10:30534")
然後设定做这次训练的主题, 在MLflow是称为experiment. 因为我们这次是使用心血管疾病的资料执行训练, 所以我们把experiment的名称叫做cardiovascular_disease
mlflow.set_experiment("cardiovascular_disease")
最後我们就要把之前训练过程的parameter、metric与model记录起来.
然後继续加上下列内容
with mlflow.start_run(run_name="jack-run-1"):
mlflow.log_param('split_rate', split_rate)
mlflow.log_metric('precision', precision_score(y_test, predict))
mlflow.log_metric('recall', recall_score(y_test, predict))
mlflow.log_metric('accuracy', accuracy_score(y_test, predict))
mlflow.sklearn.log_model(model, artifact_path="xgb-model")
我们来执行二次. 第一次是将split_rate设定为0.2, 也就是训练资料占80%, 而测试资料占20%
请将cell 16 的split_rate设定为0.2
split_rate = 0.2
再将run name设定为jack-run-1
with mlflow.start_run(run_name="jack-run-1"):
我们重新执行一训练, 等整个notebook执行完成之後, 再去MLFlow看一下结果, 应该会看到有一笔记录被记下来了, 如下图:
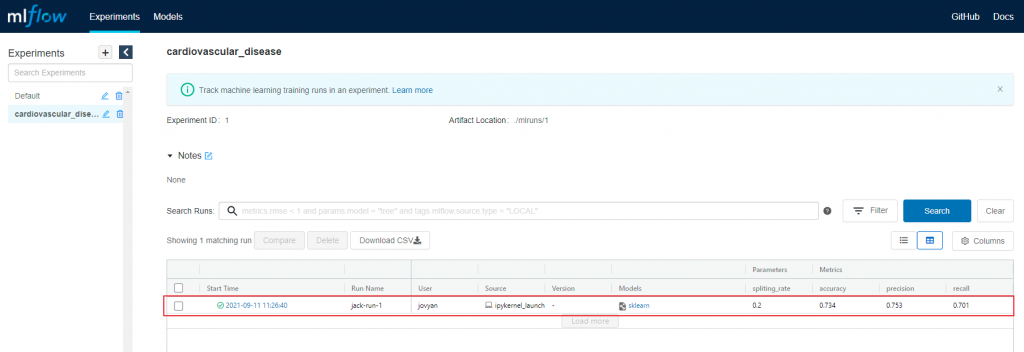
接下来再来执行第二次, 我们把 cell 16的 split_rate设定为0.3
split_rate = 0.3
再将run name设定为jack-run-2
with mlflow.start_run(run_name="jack-run-2"):
然後我们再来执行一次notebook. 然後可以在MLFlow上看到二笔资料.

使用这种方式就可以将每次执行训练的parameter、metric与model记录记来
<<: Day11-Database——效能的储备足够吗?-N+1 query
>>: [Angular] Day26. Reactive forms (二)
EP11 - 为你的 portal 添加 Load Balance 和挂载 Web ACLs
Elastic Load Balancing 什麽是 Elastic Load Balancing ...
Day 30 [分享] 学习 JavaScript 的优秀资源
底下为一些资源 JavaScript 标准参考教程(alpha) ECMAScript 6 入门 现...
在 Fedora 34 上安装官方呒虾米的 iBus 表格档 (影片录制步骤)
Fedora 34 内建 iBus 平台,直接安装行易有限公司释出的呒虾米表格档,使用完整度最高。 ...
[Day 03] 机器学习产品生命周期 — 救救我啊我救我
MLOps is an emerging discipline and comprises a s...
Day 23 - WooCommerce: 建立信用卡付款订单 (上)
图 23-1: 设定页面 昨天已经完成了永丰金流信用卡收款 API 所需要的设定选项页面,并填入 ...