Day23-pytorch(6)iris资料集示范classifier模型pytorch完整训练过程
先import各种会用到的套件

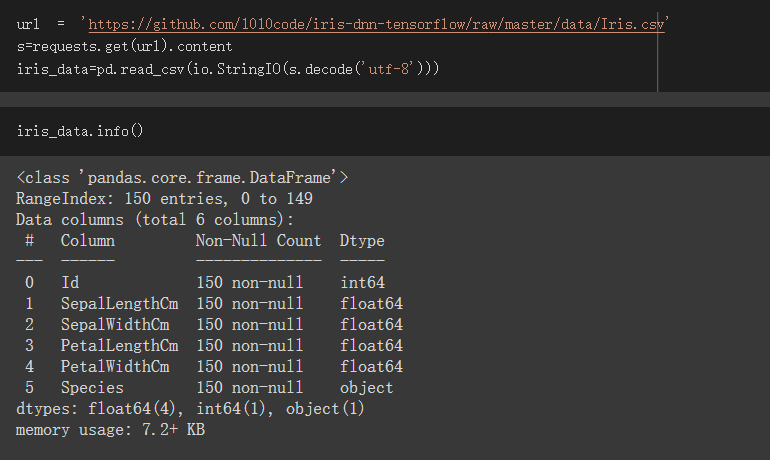
载入iris资料集
此载入iris方式我是使用别人提供的方法
此资料集包含六个栏位
Id ,不会用到,只是标明这是第几个资料
SepalLengthCm,萼片长度,资料型态为浮点数,无缺失值
SepalWidthCm,萼片宽度,资料型态为浮点数,无缺失值
PetalLengthCm,花瓣长度,资料型态为浮点数,无缺失值
PetalWidthCm ,花瓣宽度,资料型态为浮点数,无缺失值
Species,花的种类,资料型态为物件,无缺失值
资料前处理
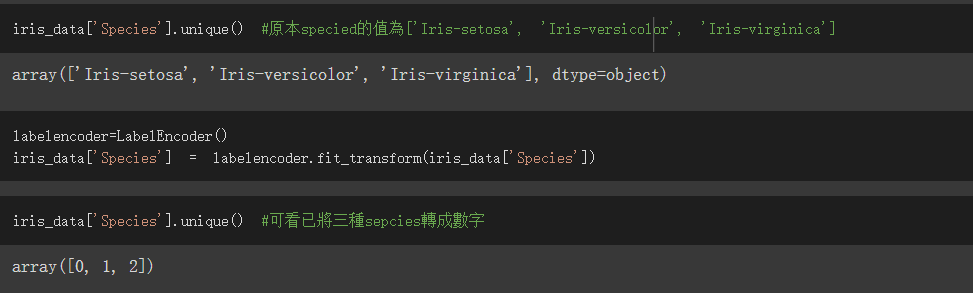
我们的训练目标为Species栏位,可是它的资料型态是物件不是数值,所以无法拿下去train
使用sklearn.preprocessing中的LabelEncoder将其都转为数字
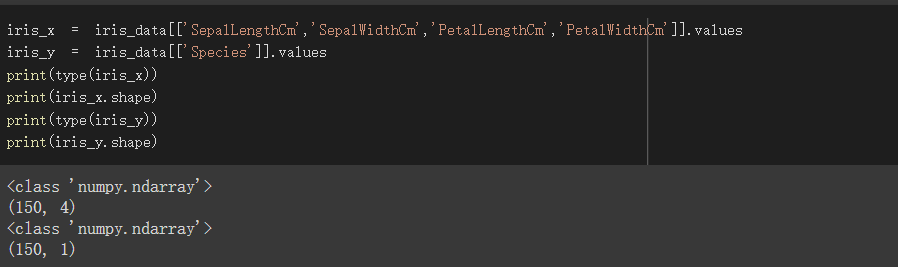
将pandas转为numpy
使用dataframe索引将会用到的栏位转为numpy
iris_x为我们的特徵值,iris_y为我们的训练目标
正规化
正规化特徵值,以利训练模型

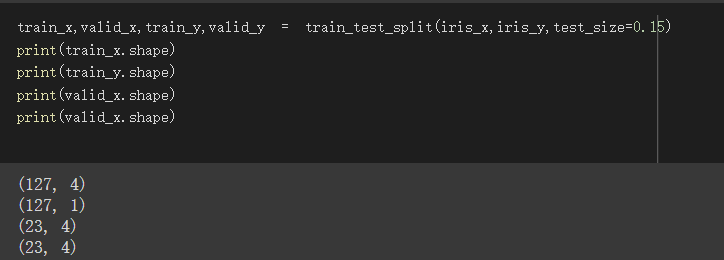
分成train_set与validate_set
使用sklearn.model_selection中的train_test_split
将资料分成训练集、验证集
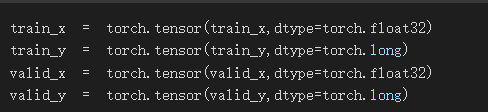
转换成tensor
使用pytorch训练前,记得将资料转成tensor才可运算
x资料dtype设为float32,y资料dtype设为long
Dataset

DataLoader

model
模型的样子随便你怎麽设
要注意两点:
第一个输入必须与资料特徵值相同
输出数需与资料要分成的类别数相同,我们要分成三种,所以设为3

criterion、epoch、optimizer、n_batch
大部分都与昨天的介绍相同
只有criterion不一样,因为是分类模型,这里使用了CrossEntropyLoss
pytorch的CrossEntropyLoss里已经有内建softmax,所以我们的model不用自己加入softmax

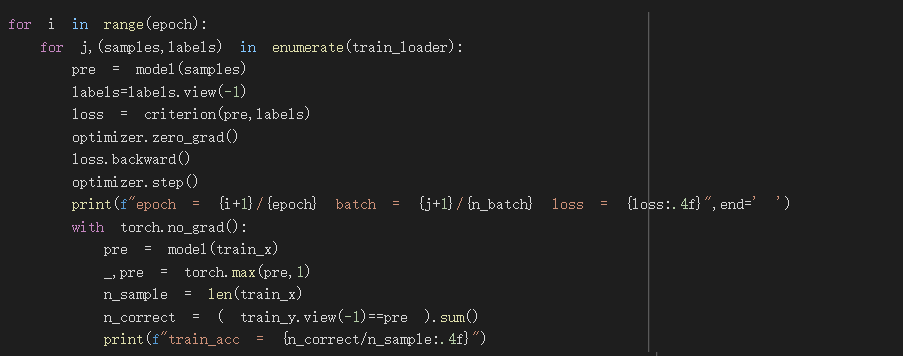
训练模型
这里我只介绍与昨天不同的地方
criterion是CrossEntropyLoss,後面要放入的target资料dimension必须是1
label=label.view(-1),将y资料改成了dimension为1的样子
with torch.no_grad(): 表示停止运算微分
其下面的程序码在计算在train资料集的正确率
torch.max(pre,1)会送回每一行最大值及最大值的索引值
我们只需用到索引值所以pre前面为底线
n_sample总共有几笔资料
n_correct预测正确的有几笔资料
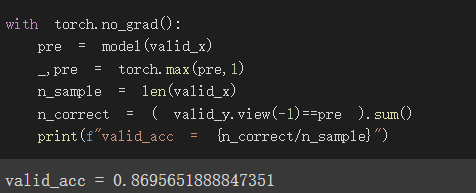
验证集正确率
送上colab连结,可自行在上面多做点练习更加熟悉pytorch
https://colab.research.google.com/drive/1xDiomDrQSUEx79qYHTixelzSmMK7ho8C?usp=sharing
LeetCode 双刀流:Stack 与 Queue 的相互实作
Stack 与 Queue 的相互实作 先看一下题目描述 225. Implement Stack...
Day20 跟着官方文件学习Laravel-Breeze
前面我们自己写了登入登出及注册,但其实laravel有提供我们身份验证的套件,这些工具包会自动提供我...
Gin 表单
Golang Gin 表单 今天真的有点爆炸了,几乎没时间补文章,只能抽空拿点时间来写,如果在gin...
iOS APP 开发完成,如何进进行内测和公测?
进入测试阶段,测试是非常重要的,提前排除可能出线的bug,减少正式上线可能会造成的损失。 内测-超级...
Day30 专案的结束以及新的开始
在 Day25 要求的功能,还剩下一个还没完成 不过实际上并没有推荐前10部影片的必要性 作为最後一...