分类模型哪个好?confusion matrix/sensitivity/ specificity
今天来整理一下以前的笔记,聊聊比较分类模型的评判依据:confusion matrix.
下图是常见的confusion matrix的图:
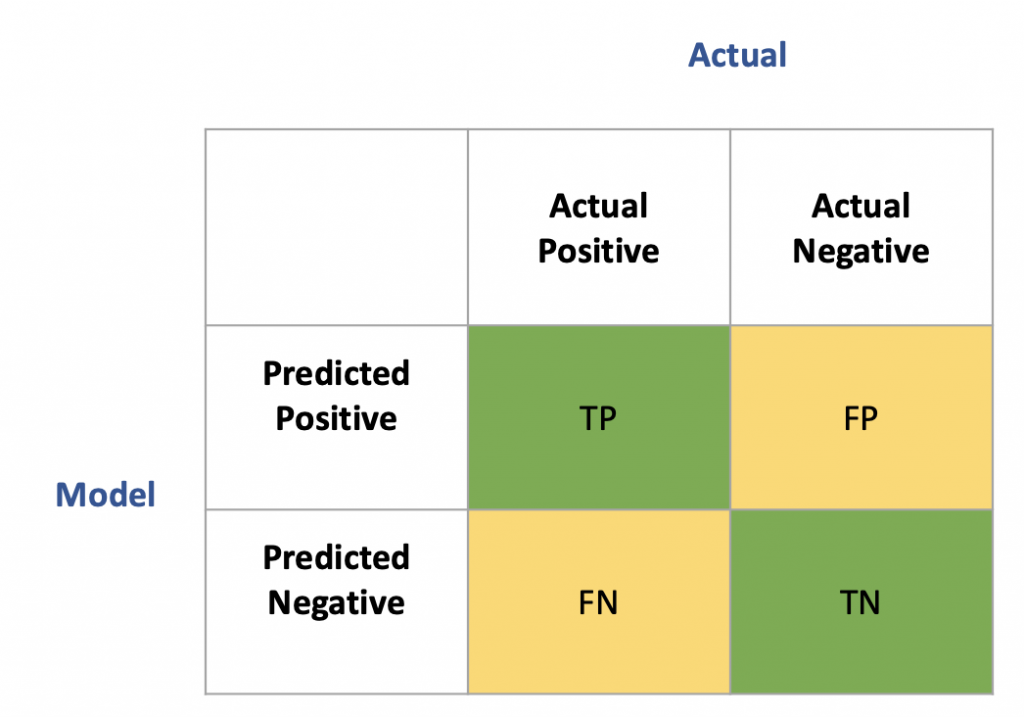
用个例子来解释上图:
假设我们今天根据血压身高体重等资料预测一群人是否有心脏病
TP(true positive):实际有心脏病且模型预测正确(有)
TN(true negative):实际没有心脏病且模型预测正确(没有)
FP(false positive):实际没有心脏病但模型预测说有,又称 type1 error
FN(false negative):实际有心脏病但模型说没有,又称 type2 error
所谓的true/false表达的是模型预测是否正确,而positive/negative会根据假设对应不同的情况,我们都希望模型预测高,所以会希望TP/FP的数量高,当纯比较数字会有点难以比较不同的模型,所以之後就衍生出了不同的比率,常见的有:
- accuracy: (TP+TN)/(TP + TN + FP + FN)
- sensitivity(recall rate): TP/(TP + FN) 所有positive中模型预测正确比率
- specificity: TN/(FP + TN) 所有negative中模型预测正确比率
- precision: TP/(TP + FP) 模型说positive的数量中有多少真正positive
- F1 score: 2 * (precision * sensitivity) / (precision + sensitivity)
根据不同的情境会使用不同的比率来比较,如果今天识别“有心脏病”的病患是主要目标,那我们就可以选择recall rate当评判标准,反之若识别“没有心脏病”的病患是主要目标的话,就可以使用specificity。
Day18 iPhone捷径-这是在哪里拍摄的
Hello 大家, 今天介绍一个官方的捷径, 这个捷径是针对图片资讯中的“位置”来查找照片拍摄的地方...
Day7 javascript 事件
HTML 事件是发生在 HTML 元素上的事情,当在 HTML 页面中使用 JavaScript 时...
[Day 15] 资料产品生命周期管理-预测模型
尽管都是模型,但预测模型目的在於预测未来,所以开发方式也会和描述型模型有所差异。 Initiatio...
上传档案 - day19
Upload Vaadin 档案上传档案使用 Upload Component,Upload 支援单...
如何在 SQL Server AOAG 设定环境之下, 套用修补程序 (patching)?
DBABootcamp 相信大家可以在网路上找到许多文章说明如何在 AlwaysOn 可用性群组 (...