[Day 10] Reactive Programming - Reactor (generate & create)
前言
之前介绍产生Flux 的方法都是固定的遵循特定逻辑的,若今天有需要客制化特殊的逻辑来产生资料,Reactor提供了generate、create来动态的产生Flux。
generate
只能一个接着一个产生资料,而且是同步的(synchronous),需要传入两个参数,第一个参数是初始值的supplier,第二个则是资料如何产生逻辑的generator,透过SynchronousSink来呼叫next()、error(Throwable) 或是 complete()。
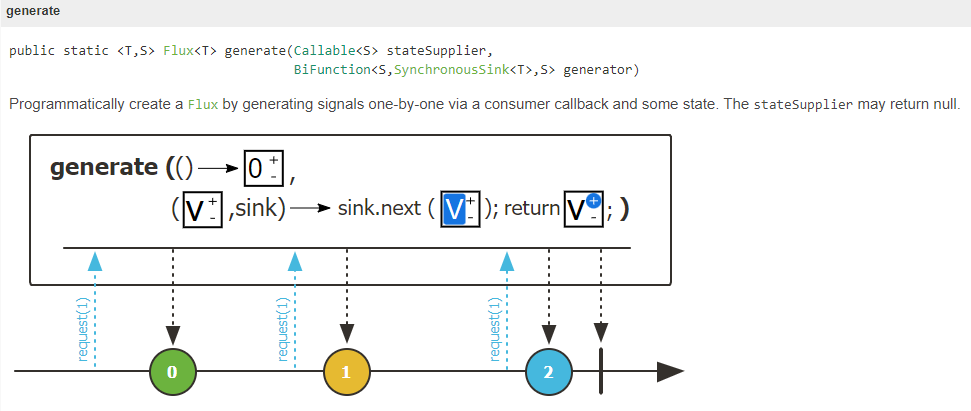
官方提供的范例,首先第一个参数初始化state为0,在generator里面,根据state定义了如果产生资料(sink.next(...)),根据state定义何时结束(sink.complete()),并定义state改变的逻辑( state + 1),从output可以看到sink.next中产生的结果就是generator产生的资料,state ==5则结束
Flux<String> flux =
Flux.generate(
() -> 0,
(state, sink) -> {
sink.next("3 x " + state + " = " + 3 * state);
if (state == 5) sink.complete();
return state + 1;
});
flux.subscribe(System.out::println);
/*
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
*/
state也可以是可更改(mutable)的物件,每次产生资料的同时都会去修改state本身,而这边还有传入第三个参数是在最後会执行的Consumer,如果你的state跟DB连线有关或是其他的资源,适合用来清理与state有关的资料,从范例可以看出Consumer可以取得最後一次的state。
Flux<String> flux =
Flux.generate(
AtomicLong::new,
(state, sink) -> {
long i = state.getAndIncrement();
sink.next("3 x " + i + " = " + 3 * i);
if (i == 5) sink.complete();
return state;
},
(state) -> System.out.println("state: " + state));
flux.subscribe(System.out::println);
/*
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
state: 6
*/
一开始有说明只能一个接着一个,所以如果同时执行两次 sink.next("3 x " + i + " = " + 3 * i);,就会抛出错误。
reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalStateException: More than one call to onNext
Caused by: java.lang.IllegalStateException: More than one call to onNext
create
create是更进阶动态产生Flux的方法,有别於generate一次只能产生一笔资料,create则适用於多笔,透过FluxSink来呼叫next()、error(Throwable) 或是 complete(),不需要透过state来控制逻辑。
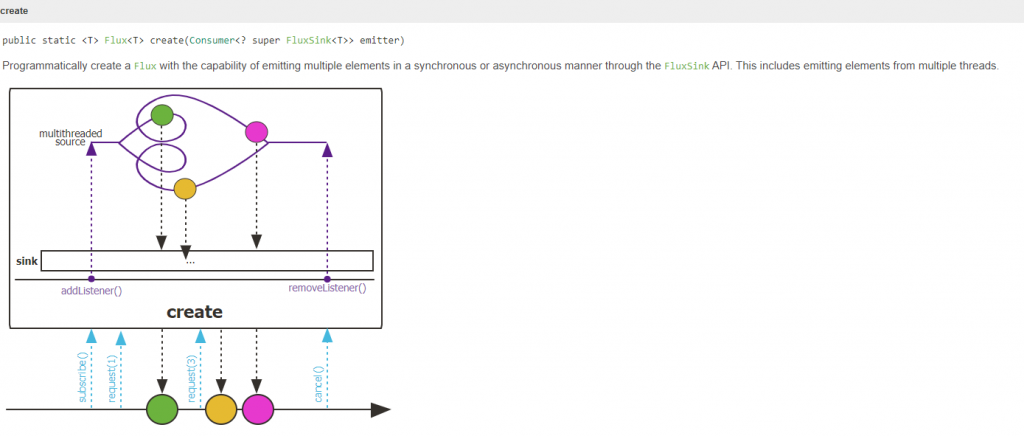
官方提供的范例,说明create适用於将现有已存在的api转换为Flux,假设有一个监听器有两个method,一个是资料处理的逻辑(参数就是资料),另一个则是完成,这样就可以透过create转换为Flux,注册监听器後,每当资料累积後触发onDataChunk就会将资料透过sink.next(s) 推送出去。
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register(
new MyEventListener<String>() {
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s);
}
}
public void processComplete() {
sink.complete();
}
});
});
由於create一次产生多笔,有别於generate的单笔,create产生资料的速度是无法预期的,也就是说有可能subscriber是来不及消化其所产生的资料,所以create可以多传一个参数代表FluxSink.OverflowStrategy,有以下几种策略:
-
IGNORE:完全无视下游的request,案照自己的节奏产生资料,有可能会导致IllegalStateException, -
ERROR:当消费不了publisher所产生资料的第一时间就会IllegalStateException,与IGNORE相似但更为极端,IGNORE本身可能会根据operators会有一些少少的buffer,还有一点点可能性不会发生错误。 -
DROP:无法消化的资料都抛弃。 -
LATEST:只保留最新的资料。 -
BUFFER:预设使用,会将无法消化的资料保存,如果资料量差距太大有可能会导致OutOfMemoryError。
比较Create Generate
-
FluxSinkvsSynchronousSink -
Consumer只会执行一次且产生0至多笔资料 vsConsumer执行多次每次只产生一笔资料 - 无法知道速率所以需要提供
OverflowStrategyvs 根据subscriber的要求来决定产生资料。 - 没有状态控制 VS 可以根据状态来决定处理逻辑
结语
如果能知道会有固定多少的资料量需要处理,可以考虑使用create,若来源资料是未知,使用generate可以透过状态来控制处理逻辑会是更好的方式。
>>: Day08:Build Private Chat(建立私人频道)
Day22 Vue 认识Porps(1)
在之前的铁人赛中我们知道了元件的实体状态、模板等作作用范围都应该要是独立的,意味这子元件是无法修改父...
[Day 02] 工欲善其事,必先利其器 - [C#]丰收款API必备前置作业(一)
正当磨刀霍霍,打开永丰银行提供的铁人赛专用Spec来试玩金流API时,哇!不得了~总共55页的文件居...
day6: CSS style 规划 - CSS in js
在经历了传统 CSS 後,发现了一些 CSS 的缺点 全域污染 - CSS class name 会...
[Day 12] iOS 学习流水帐
Swift 语言相关的特性纪录 (算基本的东西): 可选型别: 为了避免程序运算中因所使用变数为空值...
伸缩自如的Flask [day 25] Flask with web cam
github: https://github.com/wilsonsujames/webcam/tr...