【10】多分类问题下 Sparse Cross Entropy 与 Categorical Cross Entropy 的用法差异
要来讨论今天主题前,先来复习一下什麽是交叉熵 Cross-Entropy ,我觉得这部影片介绍得很不错,简而言之,我们可以将交叉熵当作资讯的乱度,也就是我们一般所说的 loss 值,在做机器学习训练时,我们训练的目的是将这个值降的越低越好,而根据交叉熵的公式可以得出,要让这个值变小就需要预测值和真实值越符合。
而在 Tensorflow 中,提供了三种交叉熵可以使用,分别是CategoricalCrossentropy, SparseCategoricalCrossentropy 和 BinaryCrossentropy。
我们今天主要介绍 SparseCategoricalCrossentropy 和 CategoricalCrossentropy 两者的使用方式和模型训练比较。
从名称来看 Sparse 及代表稀疏的意思,也就是说这个训练集的资料中,在最後一层的dense node 只会有一个是1其他都是0,假设是mnist,视觉呈现上如下
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[1 0 0 0 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 1 0 0 0 0 0 0 0 0]
也因为每笔资料只会对一个属性为1,所以训练时可以不用手动去做 one-hot 的动作。
相对CategoricalCrossentropy 的应用场景,一笔资料可能在其他属性上也可能是1,假设今天的分类器是分析人脸属性,我们的 label 可能是[男 女 高兴 生气 难过 有眼镜 有胡子],那麽资料视觉呈现可能就会是
[1 0 0 1 0 0 1] # 一位有胡子表情生气的男性
[0 1 1 0 0 1 0] # 一位有眼镜表情高兴的女性
[0 1 0 0 1 0 0] # 一位表情难过的女性
[1 0 0 1 0 1 1] # 一位有胡子有眼镜表情生气的男性
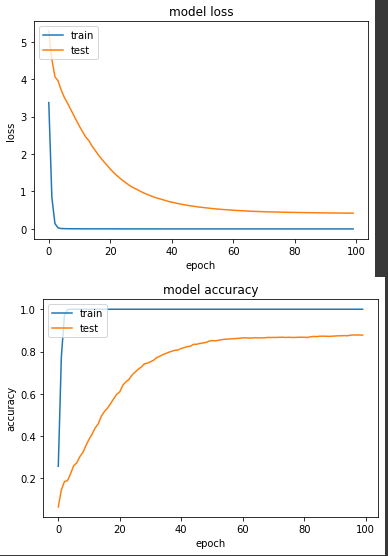
实验一: SparseCategoricalCrossentropy
前几天的训练中,我们持续使用的 entropy,在使用时,需要注意 label 必须是个 integer ,也就是像这边如果有102个分类,那喂进来的前五笔 label 必须是 [32, 44, 72, 100, 82] ,直接表明是第几个 label 的编号,所以在normalize_img中,我们直接将 label 输出即可。
def normalize_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., label
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 5.0338e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.4206 - val_sparse_categorical_accuracy: 0.8775
实验二: CategoricalCrossEntropy
如上所述,由於一笔资料可能会有多个属性(虽然我们用的这个资料集不是),所以我们必须将 label 做 one-hot 转换。
def normalize_img_one_hot(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., tf.one_hot(label, NUM_OF_CLASS)
def normalize_img_one_hot(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
return image / 255., tf.one_hot(label, NUM_OF_CLASS)
ds_train = train_split.map(
normalize_img_one_hot, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img_one_hot, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
产出:
loss: 3.9605e-04 - categorical_accuracy: 1.0000 - val_loss: 0.4483 - val_categorical_accuracy: 0.8804
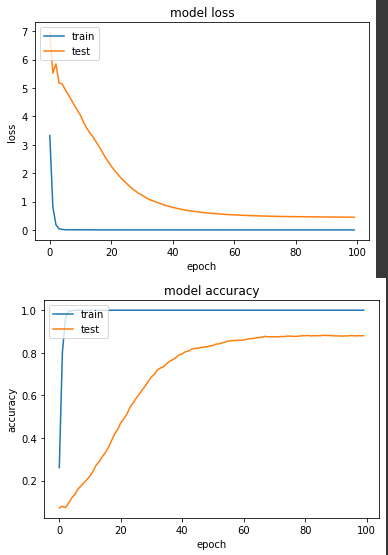
从结论来看,两者最终的准确度都差不多,CategoricalCrossEntropy 略高一些,但从收敛速度来看,SparseCategoricalCrossentropy 在第38个 epoch 准确度达到80%,CategoricalCrossEntropy 则是第42个 epoch 准确度达80%,但如果说我们都确定今天这个资料集每笔只会有一个属性为1的话,当然还是建议大家直接使用SparseCategoricalCrossentropy。
<<: pip install安装套件时遇到『use_2to3 is invalid』错误
Day 8 | 3ds Max转档至unity要点Part2
昨天已经介绍完建模时需要注意的事项,接下来要说明输出前的准备 目录 物件座标归零 转动坐标系 输出的...
D01 / 为什麽要写这个? - 前言
Hi 我是 Tomaz. 第一次参加铁人赛,和各位铁人一起进行磨练,希望撑得过去 ? 认真学 Co...
关於 GIMP
关於 GIMP 教学原文参考:关於 GIMP GIMP 是一套免费且跨平台的影像处理软件,也是教育部...
[13th][Day16] docker push
VOLUME 为 container 添加一个 volume ,一个 VOLUME 可以分给多个 c...
Laravel Queue Job:深入理解 timeout 的运作
work 和 listen 的差别 让 queue work 开始执行任务的指令有两个:work 和...