Day 09 - Kbars 转换及储存至资料库
因前篇谈到透过api.kbars抓取1分K的资料内容,但我们在看盘或盘後分析时,可能会用到其它类型的K线,例如:5分K或15分K。本篇会先说明1分K要如储存并转换成其它的K线资料。
本篇重点
- DataFrame 基本功能操作
- SQLite 简介
- 透过 Pandas,将资料储存至 SQLite 及读取
- kbars 资料转换(换算成5分K)
DataFrame 基本功能操作
https://datacarpentry.org/python-ecology-lesson/03-index-slice-subset/
在上一篇,我们说到api.kbars抓的资料最小单位就是一个交易日,若我们要抓这个交易日中的特定时间区间的kbar资料,就只能透过DataFrames做筛选。
首先,透过DataFrame.head()及DataFrame.tail(),可以取得DataFrame最前面或最後面的资料,在呼叫head()或tail()时,可以指定所要回传的资料笔数;若没有指定,预设就是回传5笔资料
df.head() #回传最前面的资料,没有指定资料笔数,预设为5笔
df.tail(3) #回传最後面3笔的资料
也可以透过Slice的方式,取得特定几笔的资料。这个功能与Python中List的Slice操作方式相同
df[start:stop:step]
# start 开始位置,不指定则以第一个元素开始
# stop 停止位置,不指定则取到最後一个元素
# step 每个元素间的位移量
df[:10] #从index 0的元素开始取,当元素的index为10时则停止
df[:10:2] #从index 0的元素开始取,当元素的index为10时则停止,每个元素位移量为2
df[1:10:2] #从index 1的元素开始取,当元素的index为10时则停止,每个元素位移量为2
df[1:9:2] #从index 1的元素开始取,当元素的index为9时则停止,每个元素位移量为2
除了上述一般Slice的方式,DataFrame更强的地方在於,可以依资料内容指定特殊条件,例如:
df.ts = pd.to_datetime(df.ts)
df[df.ts >= '13:00:00'] #依df.ts栏位,抓'13:00:00'之後的kbar资料
同样的方式,也可以套用在tick资料上面
df = pd.DataFrame({**ticks})
df.ts = pd.to_datetime(df.ts)
df[df.volume > 100] #抓成交量大於100的tick资料
如果要单纯抓某些栏位的资料,可以用下列的方式
df.ts #抓ts栏位中的资料
df['ts'] #与上一行的作用相同
SQLite 简介
SQLite - 维基百科介绍:https://zh.wikipedia.org/wiki/SQLite
SQLite是一个轻量级的资料库,在使用时并不像其它资料库需先安装DB Server及其它设定,它也可以说是目前最多人使用的资料库,因为在手机的通讯软件app,都是用SQLite来储存讯息纪录。
目前若要查看sqlite资料库内容,可用许多软件。
这里介绍使用DB Browser for SQLite
DB Browser for SQLite:https://sqlitebrowser.org/
打开上面的网址後,点「Download」
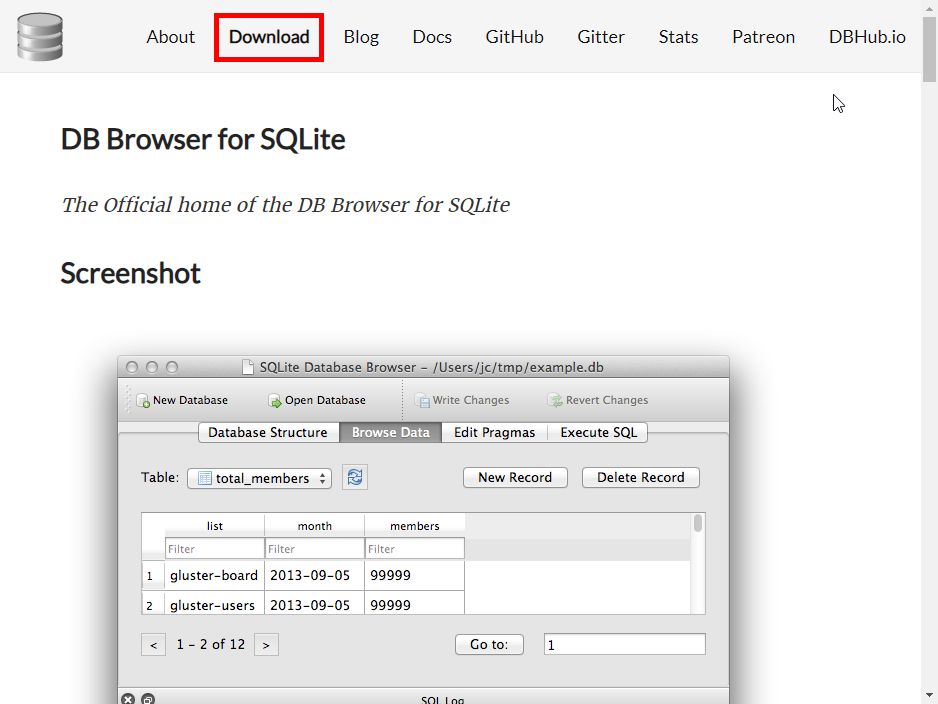
程序有分安装版及免安装版,这里我选择「DB Browser for SQLite - .zip (no installer) for 64-bit Windows」这个免安装版本
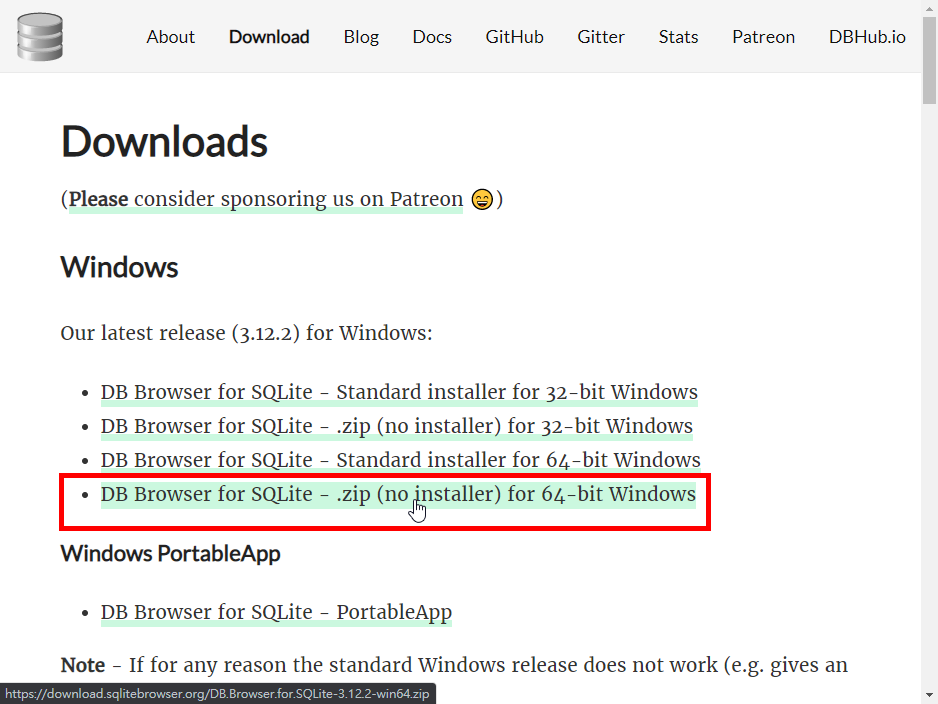
下载完成并解压缩後,程序的执行档为「DB Browser for SQLite.exe」这个档案
透过 Pandas,将资料储存至SQLite
一般我们要把资料储存至资料库,需要了解基本的SQL语法操作,并透过SQL语法将资料写入资料库的Table中。但是透过Pandas,我们可以先不用了解SQL语法,就可将DataFrame的资料储存至资料库中。
DataFrame.to_sql,可参考官方的说明文件:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_sql.html
以下范例为将kbars资料,稍做调整後储存至SQLite中
from dotenv import load_dotenv
import os
import shioaji as sj
import pandas as pd
import sqlite3 #汇入sqlite3模组
load_dotenv('D:\\python\\shioaji\\.env')
api = sj.Shioaji()
api.login(
person_id=os.getenv('YOUR_PERSON_ID'),
passwd=os.getenv('YOUR_PASSWORD')
)
conn = sqlite3.connect('shioaji.db') #建立资料库连线,若档案不存在,会自动建立
#抓2330台积电,2021-08-02~2021-09-10间所有ticks
kbars = api.kbars(api.Contracts.Stocks["2330"], start="2021-08-02", end="2021-09-10")
df = pd.DataFrame({**kbars})
df['date'] = pd.to_datetime(df.ts).dt.date #增加date栏位,并将df.ts转换成日期资料
df['time'] = pd.to_datetime(df.ts).dt.time #增加time栏位,并将df.ts转换成时间资料
df['code'] = '2330' #增加 code 股票代码栏位
df.to_sql('stocks_kbars', #所要写入的Table名称
conn, #传入上面所建立的sqlite3.Connection
if_exists='append', #当Table已存在於资料库中,所要做的动作
index=False #预设为True,设为False表示写入资料时,不将index栏位写入
)
if_exists这个参数,预设值为'fail',意思是若Table已存在於资料库中,就直接跳出错误讯息;若设为'append',表示若Table已存在,则保留原本的Table资料,并将新的资料写入到Table中;若设为'replace',若Table已存在,则在写入时,会先将原本的Table删除後重新建立,并将新的资料写入到Table中。
使用 DB Browser for SQLite 查看资料库内容
接着,执行刚才下载的DB Browser for SQLite,并按「打开资料库」
选择SQLite所在的资料夹,并选择资料库档案
开启後,就可以看到Pandas建立的Table
若要查看Table中的资料,请点「Browse Data」
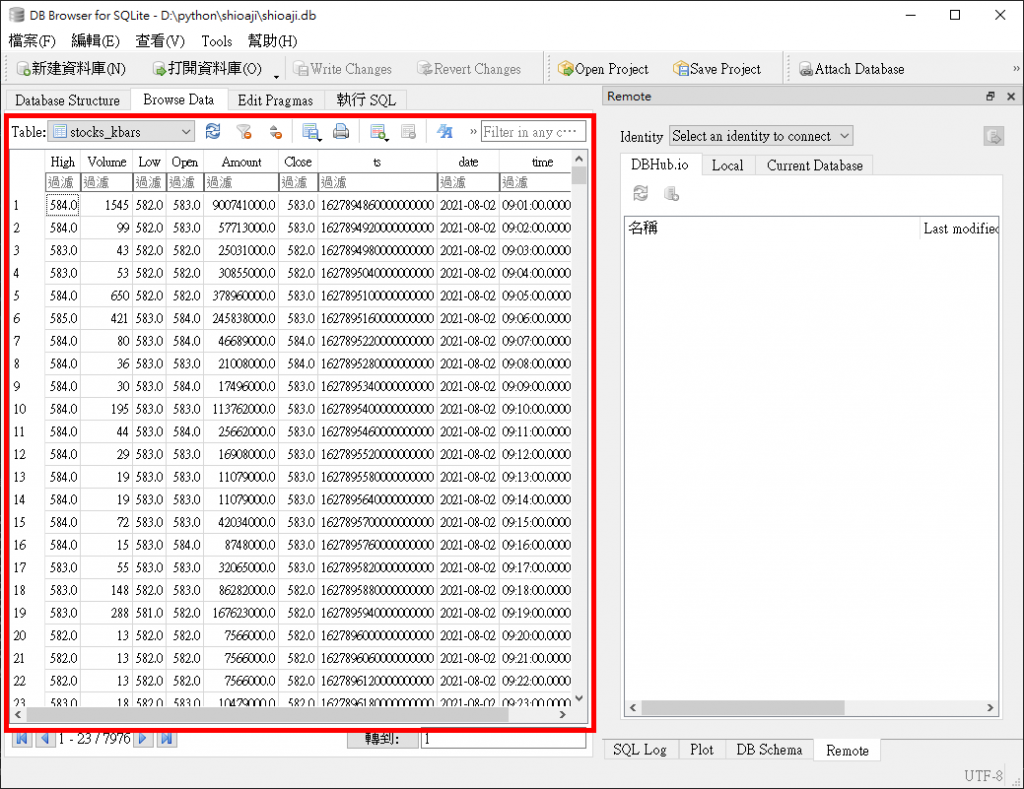
若资料有正常写入SQLite,可以看到所抓取的kbar资料内容
透过 Pandas 读取 SQLite 中所储存的资料
在前面储存至资料库时,有提到可以不用先了解SQL语法;但若要直接用Pandas直接将SQLite中的资料读取出来时,就需要写到简单的SQL语法。
import pandas as pd
import sqlite3
conn = sqlite3.connect('shioaji.db') #建立资料库连线
#从stocks_kbars这个Table中,取得所有资料,并转换为DataFrame
df = pd.read_sql('SELECT * FROM stocks_kbars', conn)
SQLite 对於刚接触程序的人,是一个很容易上手的资料库,透过 Pandas 也可以直接对 SQLite 做存取
如果你想要使用其它的资料库,可参考以下文章,使用Pandas + SQLAlchemy做存取
https://www.sqlshack.com/introduction-to-sqlalchemy-in-pandas-dataframe/
https://hackersandslackers.com/connecting-pandas-to-a-sql-database-with-sqlalchemy/
kbars 转换(1分k to 5分k 或 10分k)
前一篇的Kbars中提到,api.kbars抓出来的资料是1分K,若需要5分K或10分K,可以透过pandas.DataFrame.resample达到
官方说明文件:https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.resample.html
以下为将1分K资料转为5分K的范例:
df.index = df.ts #将ts资料,设定为DataFrame的index
kbars_5min_high = df.High.resample('5min').max() #最高。以5分钟重新取样一次後,取最大值
kbars_5min_low = df.Low.resample('5min').min() #最低。以5分钟重新取样一次後,取最小值
kbars_5min_close = df.Close.resample('5min').last() #收盘。以5分钟重新取样一次後,取最後一笔
kbars_5min_open = df.Open.resample('5min').first() #开盘。以5分钟重新取样一次後,取第一笔
透过resample重新取样後,就可以再透过pandas.concat,将上面的资料重新组合成一份5分K的DataFrame资料
官方说明文件:https://pandas.pydata.org/docs/reference/api/pandas.concat.html
df_5min_kbars = pd.concat([kbars_5min_open, kbars_5min_close, kbars_5min_high, kbars_5min_low], axis=1)
接着执行print(df_5min_kbars.head()),可以看到转换出来的5分K资料内容
Open Close High Low
ts
2021-09-17 09:00:00 600.0 601.0 601.0 600.0
2021-09-17 09:05:00 601.0 600.0 601.0 600.0
2021-09-17 09:10:00 600.0 601.0 602.0 600.0
2021-09-17 09:15:00 601.0 601.0 602.0 601.0
2021-09-17 09:20:00 602.0 600.0 602.0 600.0
同样的,若要把1分K资料转换成10分K资料,只要把resample中的参数改为'10min'即可
<<: 全端入门Day24_後端程序撰写之多一点点的Node.js
Day 14:专案02 - PTT C_chat版爬虫01 | 爬虫简介、request和response、Requests
⚠行前通知 先前已经学过Python但想学爬虫的人可以回来罗~ 从今天起就开始大家最期待的网页爬虫的...
【左京淳的JAVA学习笔记】第四章 回圈
while及do-while回圈 文法如下 while (条件式){ 执行内容 } 当条件式为tru...
未来狂想:天气气候监测领域
人的科技文明发展始终来自於人性 在科技进步的情况之下,我们已经习惯於使用科技的帮助来介入我们的生活,...
[Day5]C# 鸡础观念- 让变数学会七十二变的高手~运算子
运算子 程序的世界中,变数是无时无刻一直在变化的, 变数的变化也成为程序的精随所在, 但为甚麽变数会...
战略思考与规划(Strategic Thinking and Planning)
使命与愿景(Mission and Vision) .一个组织不是无缘无故存在的。它是为目的而建立...