Day11 - 除噪模型: FCDAE
全连接神经网路的层和层之间,神经元都是互相连接,而层内的神经元彼此没有连接。我们会使用两种 FCDAE 架构,其输入资料是含有噪音的多训练资料,将 11 个连续音框串接起来,大小是 429 维的向量作为输入,输出则是输入向量正中间音框对应的乾净训练资料,大小是 39 维。我们以隐藏层(hidden layer)数量作为区分这两种架构。两种架构都会在训练过程应用批量正规化(Batch Normalization, BN),观察是否对实验结果有所帮助。
Batch Normalization 参考论文: https://arxiv.org/pdf/1502.03167.pdf
第一种架构如图 1,以FCDAE(3h)表示,网路有3层隐藏层,每一层都是500个神经元,参数量约735K
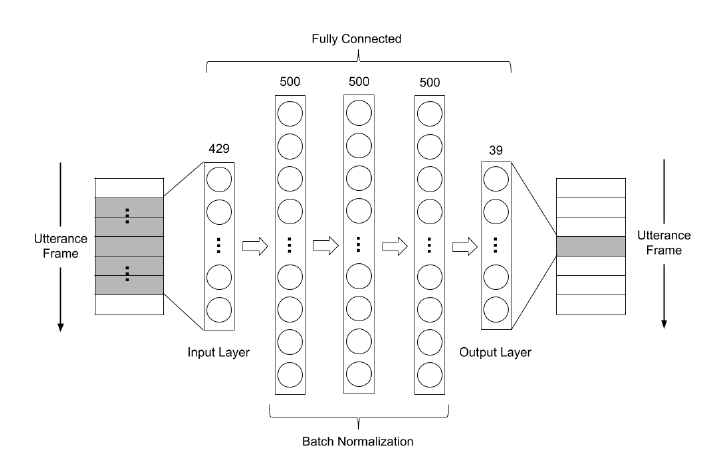
图 1: FCDAE(3h)的架构图,有3层隐藏层,每一层都是500个神经元
第二种架构如图 2,本论文以FCDAE(5h)表示,是以FCDAE(3h)的架构为基础
做修改。此网路有5层隐藏层,第一层和第二层有500个神经元,第三层有273个神经
元,第四层和第五层有300个神经元,参数量约 786K。和第一种架构相比,在参数量
略增加约51000个的情况下,我们加深网路的层数,目的是观察在参数量相差不多的
条件下,网路的深度是否会影响除噪表现。除此之外,此网路的架构是不平衡的,即
编码器和解码器的大小不相同。在训练两个全连接除噪自动编码器的超参数设定如下:
- learning rate : 0.001
- activation function: LeakyReLU ($\alpha=0.3$)
- optimizer: Adam
- mini-batch size: 100
- epoch: 100
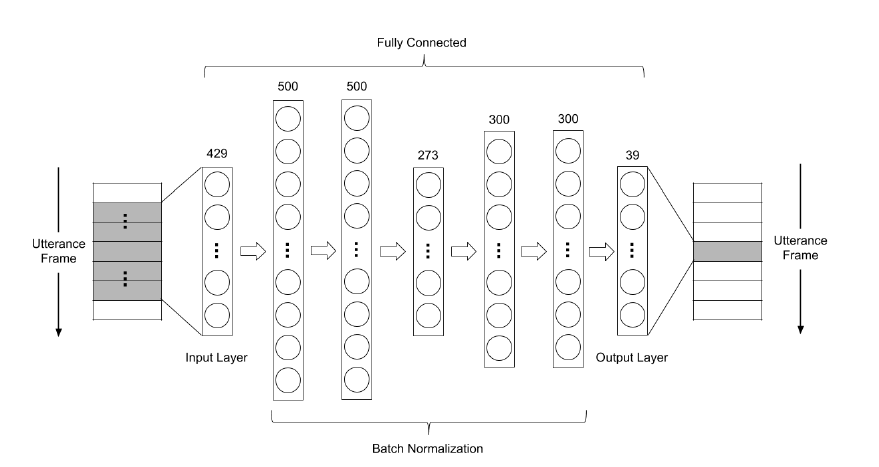
图 2: FCDAE(5h)的架构图,有5层隐藏层,第一层和第二层有500个神经元,第三层
有273个神经元,第四层和第五层有300个神经元
在模型建立与训练的部分,使用的是 python+tensorflow+keras ,程序码以 FCDAE(5h) 为范例如下:
# FCDAE(5h) model
from keras.layers import *
from keras.models import *
import keras.optimizers
leakyrelu = keras.layers.LeakyReLU(alpha=0.3)
# optimizer
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=1e-5)
# instantiate model
model = Sequential()
model.add(Dense(500, input_dim=429))
model.add(leakyrelu)
model.add(Dense(500))
model.add(leakyrelu)
model.add(Dense(273))
model.add(leakyrelu)
model.add(Dense(300))
model.add(leakyrelu)
model.add(Dense(300))
model.add(leakyrelu)
model.add(Dense(39))
model.compile(loss='mse', optimizer=adam)
>>: Day8-TypeScript(TS)的介面型别(Interface)Part 1
[Day26] 用 Rocket 做一个图书馆门禁後端 (Part 3)
今天就要打疫苗了 然後我现在还没睡 掰了 明天没看到我的文就代表真的掰了 QQ 好 今天准备的内容比...
30天学会 Python-Day28: 选择档案
tkinter tkinter 是 Python 中用於制作 GUI 的套件 可以用 tkinter...
[Day 10] 第一主餐 pt.3-Djgnao与网页间的连结
在上一篇我们成功建立了django专案 今天我们就要来加上一些东西,并且让我们的django跑起来啦...
[Day18] 抽象类别
抽象类别 PHP也支援抽象类的和抽象方法,被定义为抽象类的方法不能被实体化,在任何一个类别中, 如果...
26.Computed vs Methods
比较下面两个用法: <!-- computed --> <div>{{ re...