Day08 - [丰收款] 十六进位格式的後续探讨,字串传输容量倍增了!
延续昨天的十六进位转换,还有件重要的事。
隐藏的问题,容量变大了
若是某个需求,资料传送过程中不允许传送中文,仅能以英数字传送,那麽我们有机会将原本的中文透过上述方式转换成十六进位格式的字串进行传送,如此一来可以解决传送方式的限制或者是未知编码错误的乱码问题。
但是这里有一个隐藏的容量成本需要考量一下。
print(len(ch_01_ba_encoded)) # ch_01_ba_encoded为:b'\xe6\xb0\xb8\xe8\xb1\x90API'
# 长度为 9 bytes
print(len(ch_hex_01_str_encoded)) # ch_hex_01_str_encoded为:'e6b0b8e8b190415049'
# 长度为 18 bytes
程序说明
以上面为例,「永丰API」这几个中英文夹杂的utf-8,刚刚有说过这串总共占了9 bytes。
但是转换成十六进位型态的字串,长度却变成了18 bytes,足足变大了1倍,这是怎麽回事呢?
原因是,原本的每一个ASCII都占1 byte,或者中文转成3 bytes後,1个Byte是8 bits,而8 bits其实可以拆成4 + 4 bits来看。
4个Bits指的是2的4次方,其可表示的数值范围为0~15,恰恰好就是十六进位的表示范围。
因此每一个byte,会拆成以2个十六进位方式显示。
我们若直接将「永丰API」这几个utf-8的字串转成真正bytearray的二进位,其实是长这个样子:
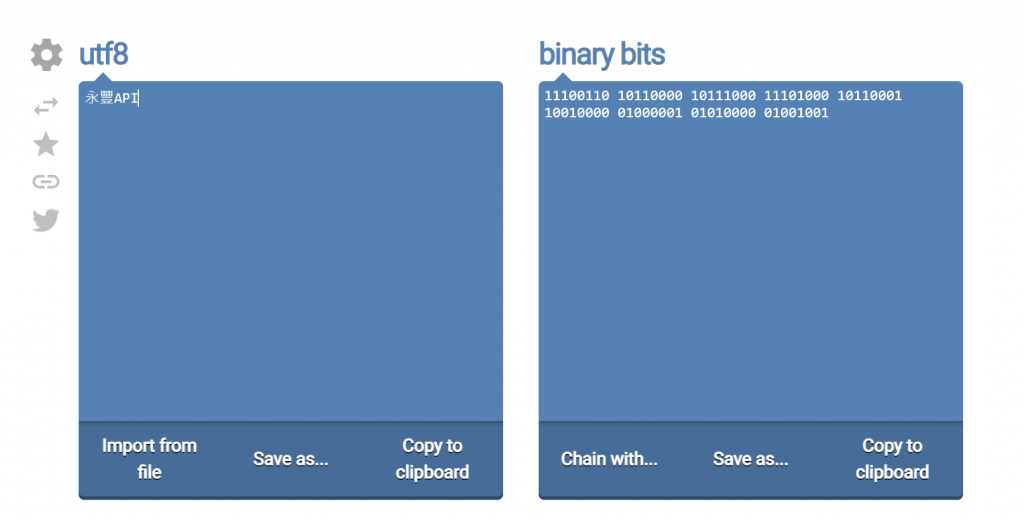
我们就拿第一个byte来看:11100110,这里其实就只有8 bits的空间。
但刚刚说到每4个bits就可解析一个完整的十六进位,因此上述可拆成1110与0110。
而1110以10进制来看,为14,而在十六进制就是"e"。
0110以10进制来看,为6,而在十六进制就是"6"。
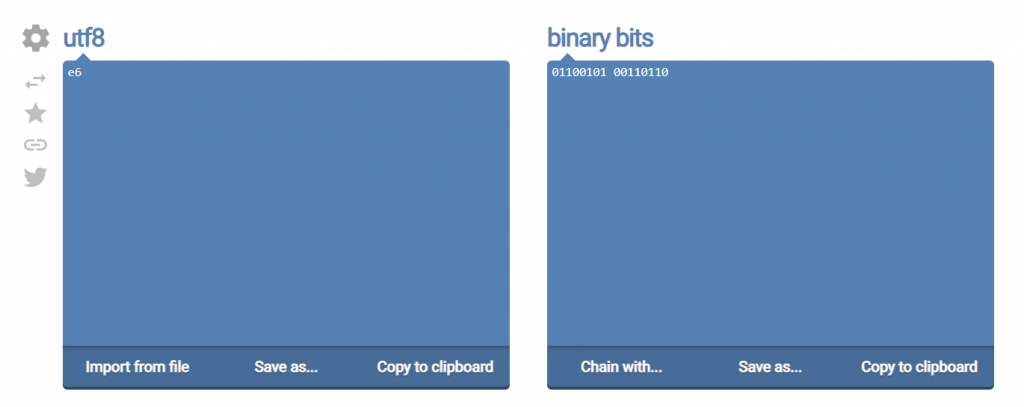
还记得我们前面将「永丰API」这几个字串转出来的十六进位吗? e6b0b8e8b190415049,前面两位就是e6。
那e6这个原本从8 bits拆解出来的值,若硬生生要将2个字元输出时,实际上占用空间是2 bytes (16 bits)。(输出为:01100101 00110110)因此使用这个方式,会造成传送量直接放大一倍,是成效较低的作法。
画个图来说明,应该会比较好懂。
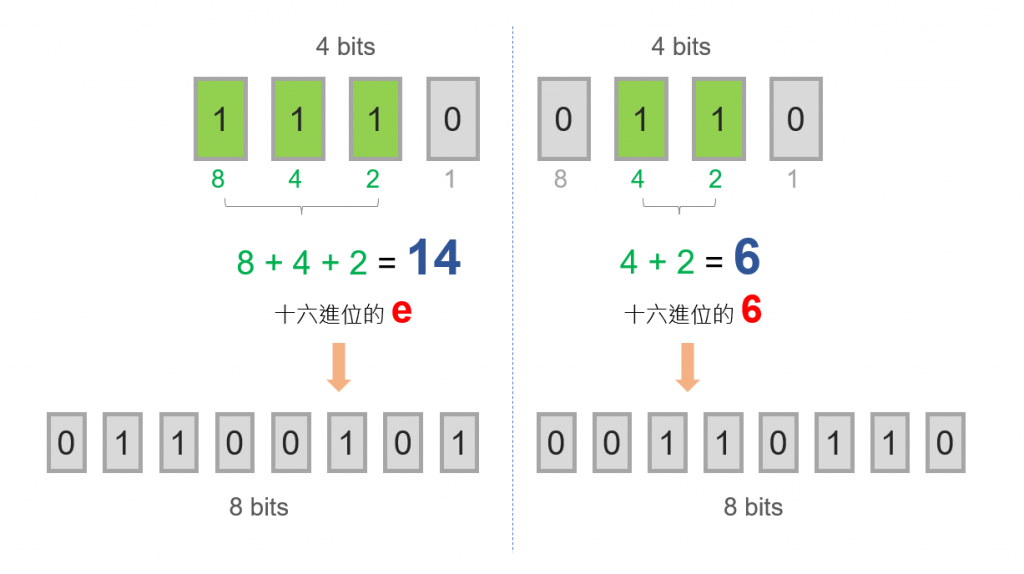
- 原本1 byte (8 bits),将左4右4 bits拆出2个十六进位表示
- 但若将这2个十六进位再以「字串」来转出,无论是ASCII或utf-8,纯英数字都是占1 byte (8 bits)
- 因此有2个十六进位,一共变成了2 bytes
- 从原本1 byte → 变成了2 bytes,占用容量变成2倍大小。
若使用Base64的编码方式,一样可取其均为可视字元,不会造成乱码之外,空间耗用也较十六进位节省的多。目前广泛被运用在许多网页传参数或API传送运用上,甚至可作为网页图片的运用。
Base64基础原理快速讲
既然都提到Base64了,就很快速的说明一下。先前提到十六进位,如果拿来做为传输用途,有一个好处是他使用了数字0~9以及英文A~F (先不管大小写)。总之,他若拿来当作字串传递使用,里面的每一个字元的字就只会在这16个范围内,当然他们都是可列印字元。不过缺点刚刚上面已说明,这样子容量会立刻变成2倍大。
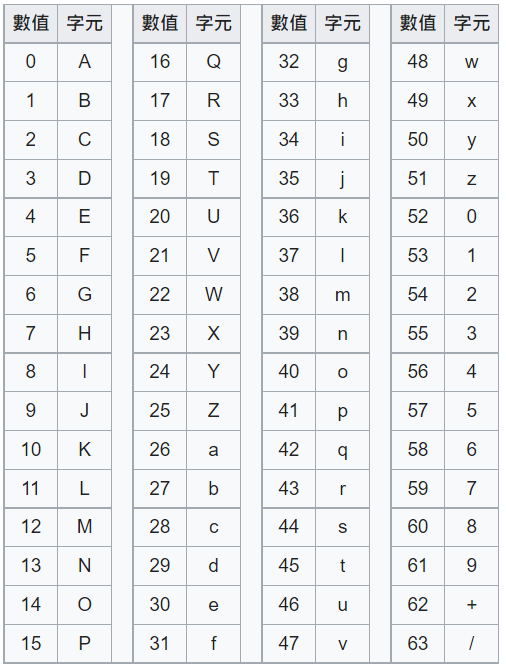
所谓16进位,就是使用了4-bit的二进位制 (2的4次方),可从里面表示出0~15的值域。而Base64则是使用了6-bit的方式(2的6次方),因此可表示出0~63范围内的64种值域。
这64个值域都会是可列印字元,好处先前已说过,是这样来的:
-
数字
0~9,10个 -
小写英文
a~z,26个 -
大写英文
A~Z,26个
上面加起来,一共是62个了 -
再加上两个可列印字元
+与/
总共就有64个值域可使用。
接下来实作说明一下,由於Base64采用了6-bit去切割元本的bytes,因此另外需要考虑的是若无法被刚好整除的话,最右侧尾码要补0并转出时带入=标示为padding用途。
附上一张Wikipedia的图表作解说:
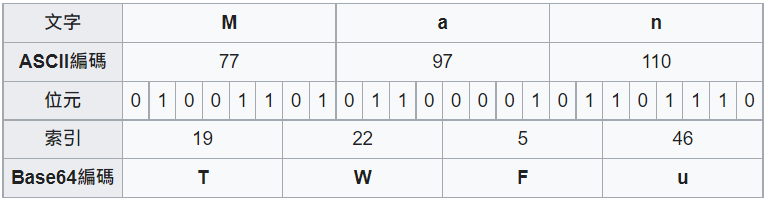
Wikipedia的Base64 索引表:
把十六进位与Base64作个比较
为了方便理解,我直接举一个可以被3 bytes整除的例子(因为6与8的最小公倍数是24 bits,即3 bytes)。
若原本有3 bytes (24 bits)的资料,若以十六进位的方式每4-bit切割法会产生6个十六进位值域的字元,再转换成纯字串时会占用6 bytes (48 bits)。
若使用了Base64来切割,每6-bit进行切割,仅会切出4个Based64值域的字元,因此一样的我们将这些可列印字元转成一般字串输出时,会占用4 bytes (32 bits)。
因此:
- 原本24 bits
- 转成十六进位表示的字串大小变为48 bits:增长率100%
- 转成Base64表示的字串大小变为32 bits:增长率33.33%
实例解说
再使用「永丰API」这个utf-8字串,先转成binary看一下他的原始bytes模样,之前也说过总共占了9 bytes。
11100110 10110000 10111000 11101000 10110001 10010000 01000001 01010000 01001001

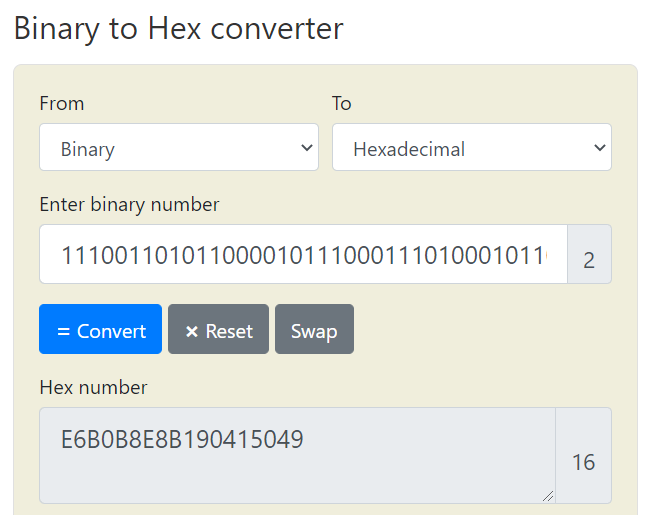
再来就是将这些binary转换成16进位表示,结果为E6B0B8E8B190415049:
若是我们将binary转成Base64的方式表示,结果为5rC46LGQQVBJ,光看字串就可以知道比上面十六进位短了。
接下来用Python实作一下,可以观察其中所占用的空间大小以及转成字串後的增量比例。
因为有使用Base64模组,记得import base64
ch_01_str = "永丰API"
ch_01_ba_encoded = ch_01_str.encode("utf-8")
print("ch_01_ba_encoded: {}".format(ch_01_ba_encoded))
# Output: ch_01_ba_encoded: b'\xe6\xb0\xb8\xe8\xb1\x90API'
len_ori_str = len(ch_01_ba_encoded)
print("Len of ch_01_ba_encoded: {}".format(len_ori_str))
# Output: Len of ch_01_ba_encoded: 9
ch_hex_01_str_encoded = ch_01_ba_encoded.hex()
print("ch_hex_01_str_encoded: {}".format(ch_hex_01_str_encoded))
# Output: ch_hex_01_str_encoded: e6b0b8e8b190415049
len_hex_str = len(ch_hex_01_str_encoded)
print("Len of Hex String: {}, 增量:{:.2%} ".format(len_hex_str, (len_hex_str-len_ori_str)/len_ori_str))
# Output: Len of Hex String: 18, 增量:100.00%
import base64
ch_hex_01_base64 = base64.b64encode(ch_01_ba_encoded).decode("utf-8")
print("ch_hex_01_base64: {}".format(ch_hex_01_base64))
# Output: ch_hex_01_base64: 5rC46LGQQVBJ
len_base64_str = len(ch_hex_01_base64)
print("Len of Base64 String: {}, 增量:{:.2%} ".format(len_base64_str, (len_base64_str-len_ori_str)/len_ori_str))
# Output: Len of Base64 String: 12, 增量:33.33%
额外补充
有关Base64最後在62个之外再加上的最後2个字元:+与/,这部份在某些情境上使用是会造成混淆的。侧如/用在URL网址列时,就会和原本网址的/造成使用上的冲突。因此针对不同的最後2个字元选用,依情境上又有发展出不一样的设计,例如那两个字元改成-与_。但有一好没两好,如果把Base64又改用在正规表示式(Regular Expression),又会有原符号在里面有特殊用途,因此又发展不同的适用版本。
若对此有兴趣的话,可以自行实作,虽然原本是想谈谈十六进位表示法的字串增长,顺便也把好用的Base64抓进来一起讲。
<<: Day 9:1046. Last Stone Weight
>>: Day08:【TypeScript 学起来】物件型别 Object Types : object
Golang快速入门(Day4)
在这边要介绍一下go的基本用法 而这些用法在A Tour of Go也都有介绍 在下面的程序码如果有...
[Day01] Flutter GetX 前言 x 建专案
Hi 大家好! 我是Clark, 2018年踏上了iOS App的学习与开发, 因缘际会接触了Flu...
[DAY 25] _STM32 看门狗简介_独立看门狗(1)
剩下这几天我都会看一些我比较不懂的东西,把我自己吸收进来的东西整理上来,我的重点都在20天前面,有兴...
[经典回顾]资讯服务异常公关用语「 骇客攻击」
资料来源: [HITCON年会] 亲爱的,问题不一定是骇客造成的 保密防谍、人人有责 骇客语录 ...
[Day18] Vite 出小蜜蜂~ 位置校正 Position Adjustment!
Day18 接下来再进到分数系统之前, 卡比要先进行位置的校正,使我们更接近原作。 Enemy 首先...