Day.15 Crash Recovery- InnoDB 架构 -> MYSQL 二阶段提交(2PC) _完
看完了前2天内容就为了今天的主题二阶段提交,相信在下面你就能更明白整个流程的走向。
二阶段提交(Two-phase Commit)
ps.2个参数sync_binlog/innodb_flush_log_at_trx_commit 都为预设1的状况下
-
作用: 保证(Server层)binlog与(引擎层)redo log的数据一致性。
-
二阶段提交在执行事务提交的过程把redo log写入分成2步骤
- prepare阶段: 写redolog标示为prepare状态。
- commit 阶段: 写binlog後将redolog标示更新成commit状态,事务提交更新成功。
详细流程看图~
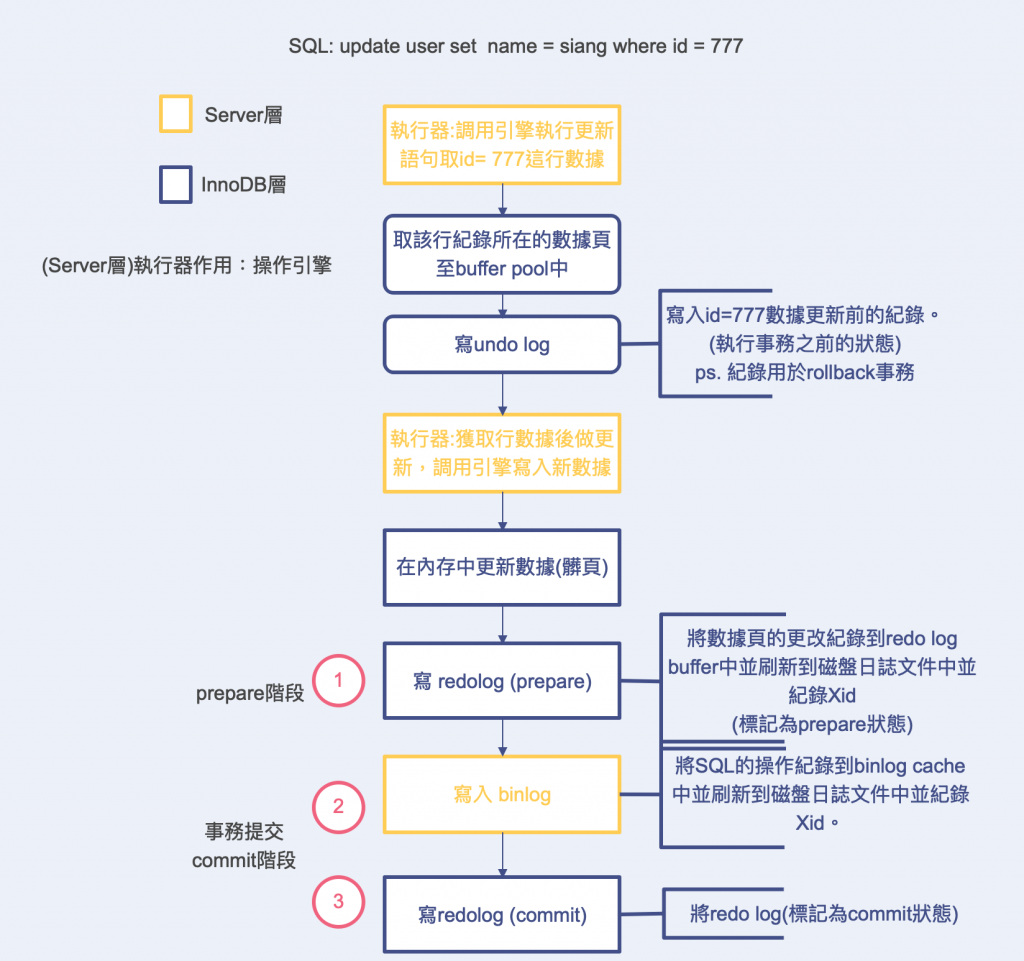
Q: 为何要保证2个日志的一致性?
首先我们知道在主从架构下从库的资料复制是靠binlog完成的,而redo log跟资料库数据恢复有关,undo log跟事务的回滚操作有关。
那当在图中(1),(2),(3)不同阶段发生资料库crash!,事务恢复的过程是如何进行的 ~
-
redo log prepare阶段
- redo log prepare -[NO]
恢复时: prepare阶段就crash了,binlog都没写入和提交,不用怀疑rollback事务~
-
写binlog 阶段异常 -> (rollback事务)
- redo log prepare -[YES]
- binlog -[NO]
恢复时: 在2个日志逻辑不一样的状况下,因为binlog写入阶段异常导致纪录缺少,当从库透过binlog更新资料时就会少了这次更新的内容,造成主从数据不一致,rollback事务。
-
在最後redo log 更新状态commit阶段
- redo log prepare -[YES]
- binlog -[YES]
- redo log commit -[NO]
注意上图中可以看到redo log在prepare阶段 & 写入binlog 都有纪录Xid的动作! 可以说是用来判断2个日志的是否达成一致。
恢复时: 会检查redo log中prepare状态的事务是否与对应的事务binlog Xid一致(白话文:2边事务纪录的xid存在且一致就OK啦~)。没有就rollback事务,有就commit事务。
- Xid纪录在哪儿?(撷取binlog内容:一个事务的提交纪录)
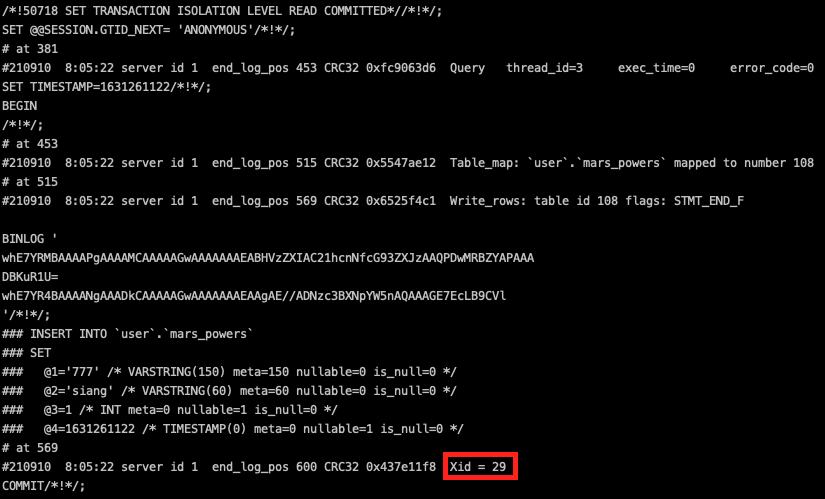
总结一下:
在崩溃恢复中,检查的就是2个日志内容是否状态一致,而透过二阶段提交机制确保2个日志的一致性,能在资料库crash时透过redo log将数据库内容恢复到crash之前状态,且透过binlog复制的主从关系在数据一致性上也没有问题~
本来只想说单纯二阶段提交就2个日志的一致性恢复应该写蛮快的XD,但看到最後不对喔!太表面根本看不懂整个流程到底怎麽跑..然後就越看越多嗯嗯这主题很棒~
其实学系统真的是常常会有知道这个流程怎麽跑但实际在干嘛真的不清楚的状况,真的去理解才发现整个内容一堆细节,看下去就是一大篇

下一篇来介绍个语法~透过应用学习更能知道如何在环境上使用SQL
<<: Day 23 Azure machine learning: training experiment and register model- 以 LSTM 模型为例
DAY6 建立Messaging API channel
各位可以把频道(Channel)想像是服务提供者(Provider)所建立的LINE帐号,藉此和使用...
Re: 新手让网页 act 起来: Day20 - React Hooks 之 useContext 与 createContext
前言 在之前 Lift state 的文章有提过,当我们有两个元件须共用到同一个 state 会将 ...
Day 19 随机森林
今天我们要介绍的是随机森林,所谓的随机森林就是指将多个决策树组合而成并且加入随机的分配去训练资料,而...
从中国恒大事件看停损的重要性
最近中国恒大负债事件愈滚愈大,许多媒体甚至以耸动的标题形容2008年的「雷曼兄弟金融海啸」重演。 个...
Day12 职训(机器学习与资料分析工程师培训班): Python程序设计
今天教学Numpy & Pandas & Matplotlib import pan...