[DAY07] 开始用 Designer 在 Azure Machine Learning 做 AI
DAY07 开始用 Designer 在 Azure Machine Learning 做 AI
我们建立好了自己的 dataset,也建立好了运算资源,今天我们开始进入 Author 三剑客之一的 Designer。
什麽是 Designer
大家还记得我们在第一天时讨论的:Classic 版和新版 AML 的分别吗?Classic 版最厉害的功能是完整的图形化介面,让你用拖拉的方式就可以做 Machine Learning 了。在现在新版的 AML 里,也依然保留这项功能,就是在 Designer 里面可以做到。
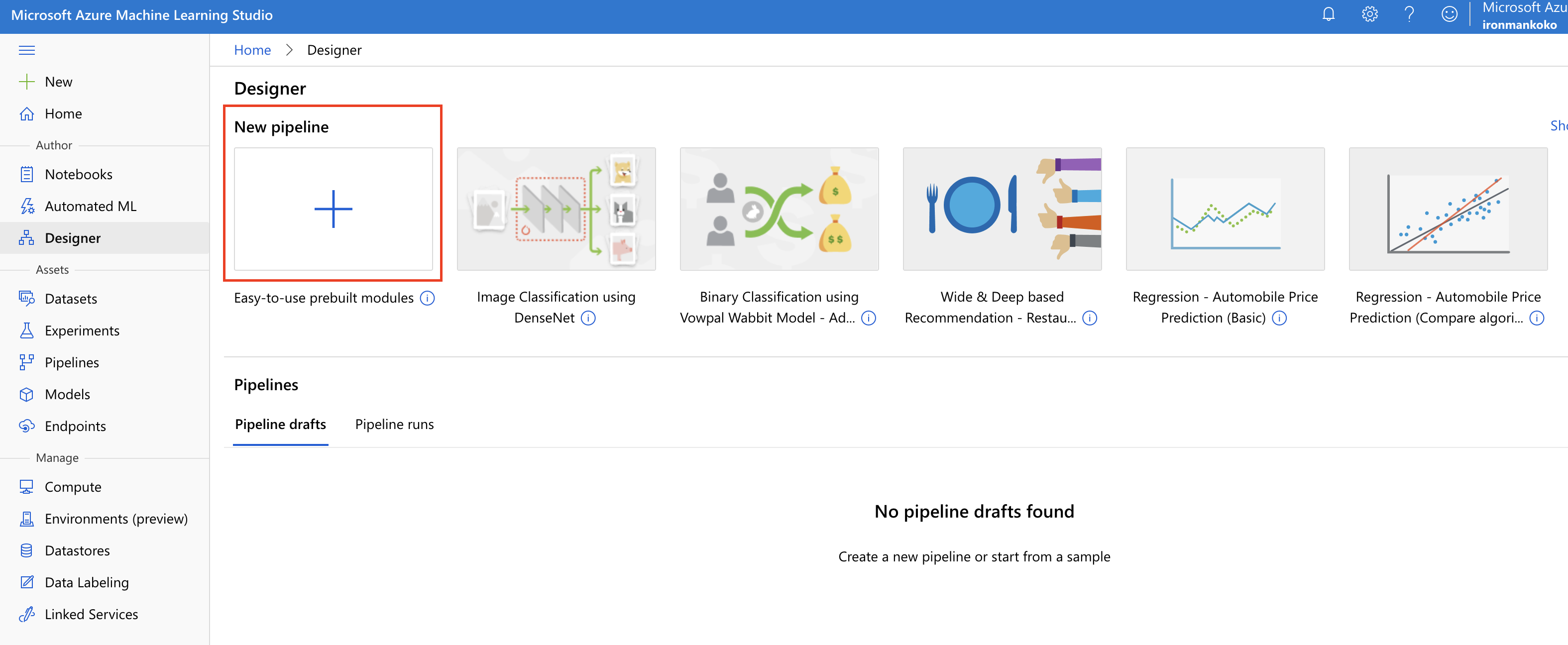
建立自己的 Designer
我们先点击进去 Designer 可以看到已经有很多内建好的模组了。我们可以点进去打开这些内建的模组做学习。举例来说,我们今天要做的是铁达尼号的存活预测,这是一个二元分类的题目,不是死就是活,那麽我们就可以找二元分类相关的 Design 来做学习。不过我们还是要 hardcore 一些,就从头开始来建立一个
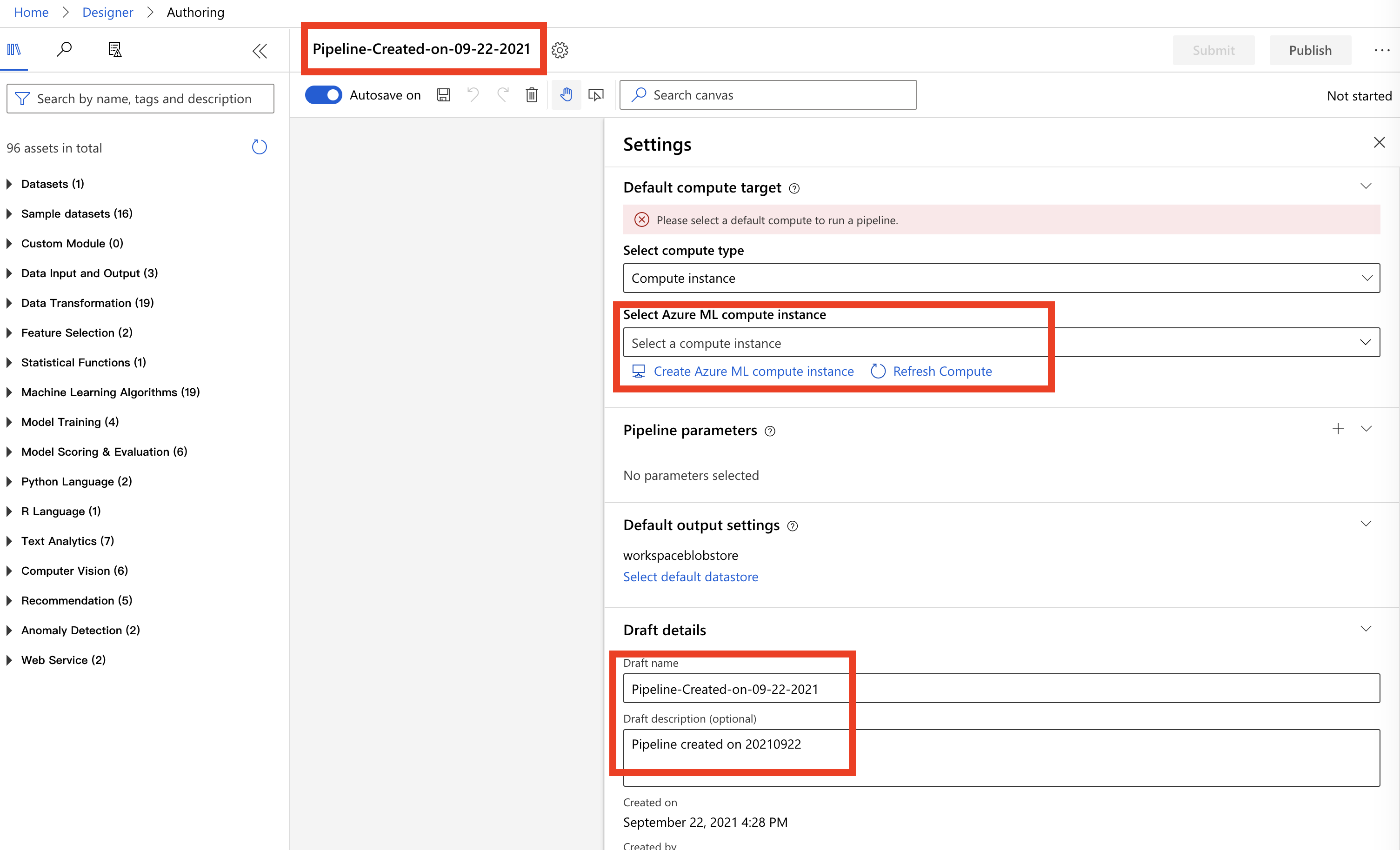
- 我们点击左上的加号。
- 这时候会跳出下列画面,可以更改名称,还有选择你的 compute instance。
-
接着我们可以看到左边的选单,称为 asset library,这里有很多微软已经内建好的模组给你使用。你只要点击并拖曳到中间的 canvas,就可以开始建立你的流程。
-
我们首先先选 Dataset,把我们前几天建立好的铁达尼号拉进来,我们可以看到 canvas 就出现了我们 titanic 的方框。
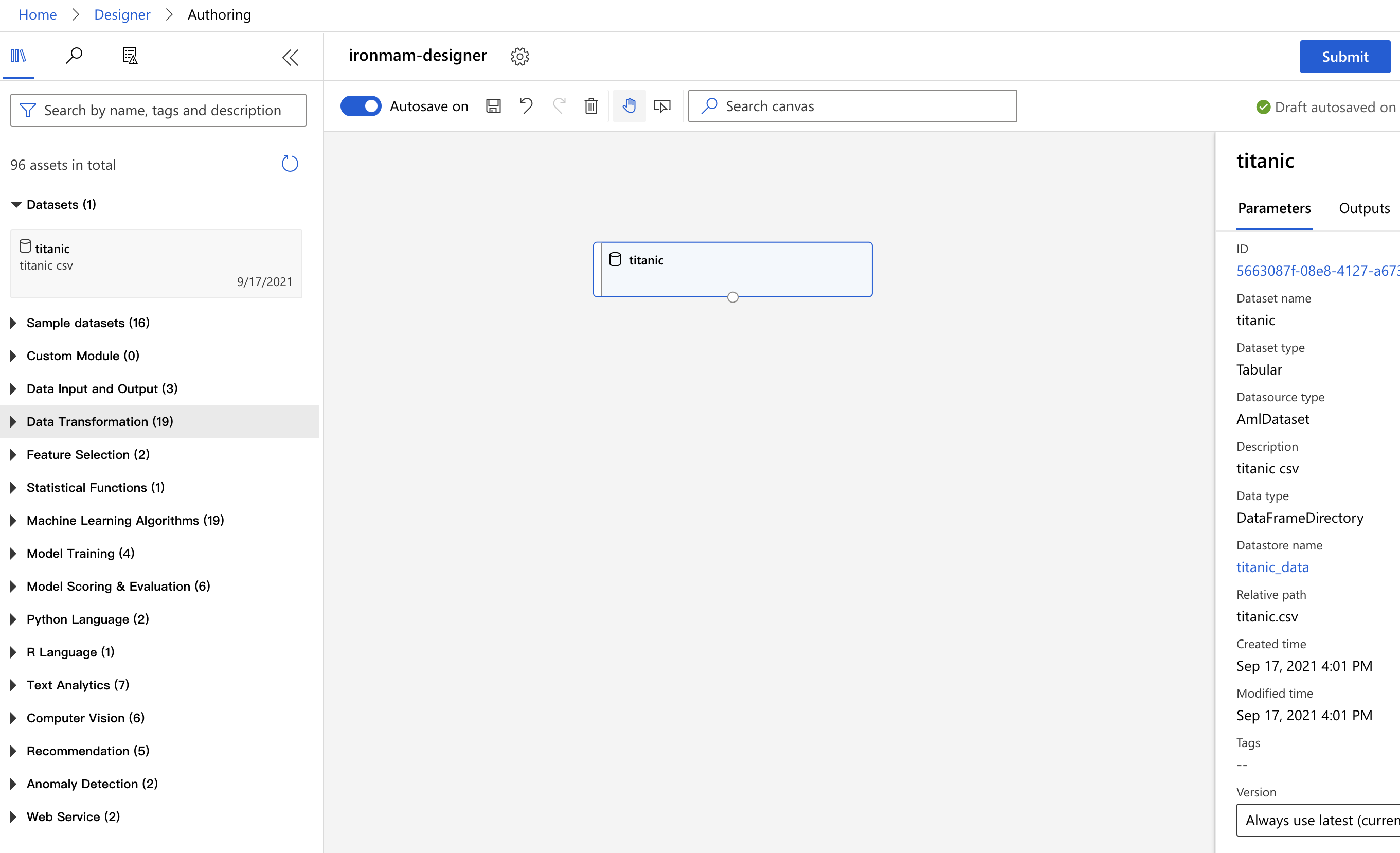
资料清理
-
资料拉进来後,我们要来选特定的栏位,踢掉不想要的栏位。这时候我们在 asset library 输入
Select Columns,就会出现 Select Columns in Dataset 的选项,我们把它拉进 Canvas。然後把上面的 titanic dataset 拉个箭头到 Select Columns in Dataset 的方框。
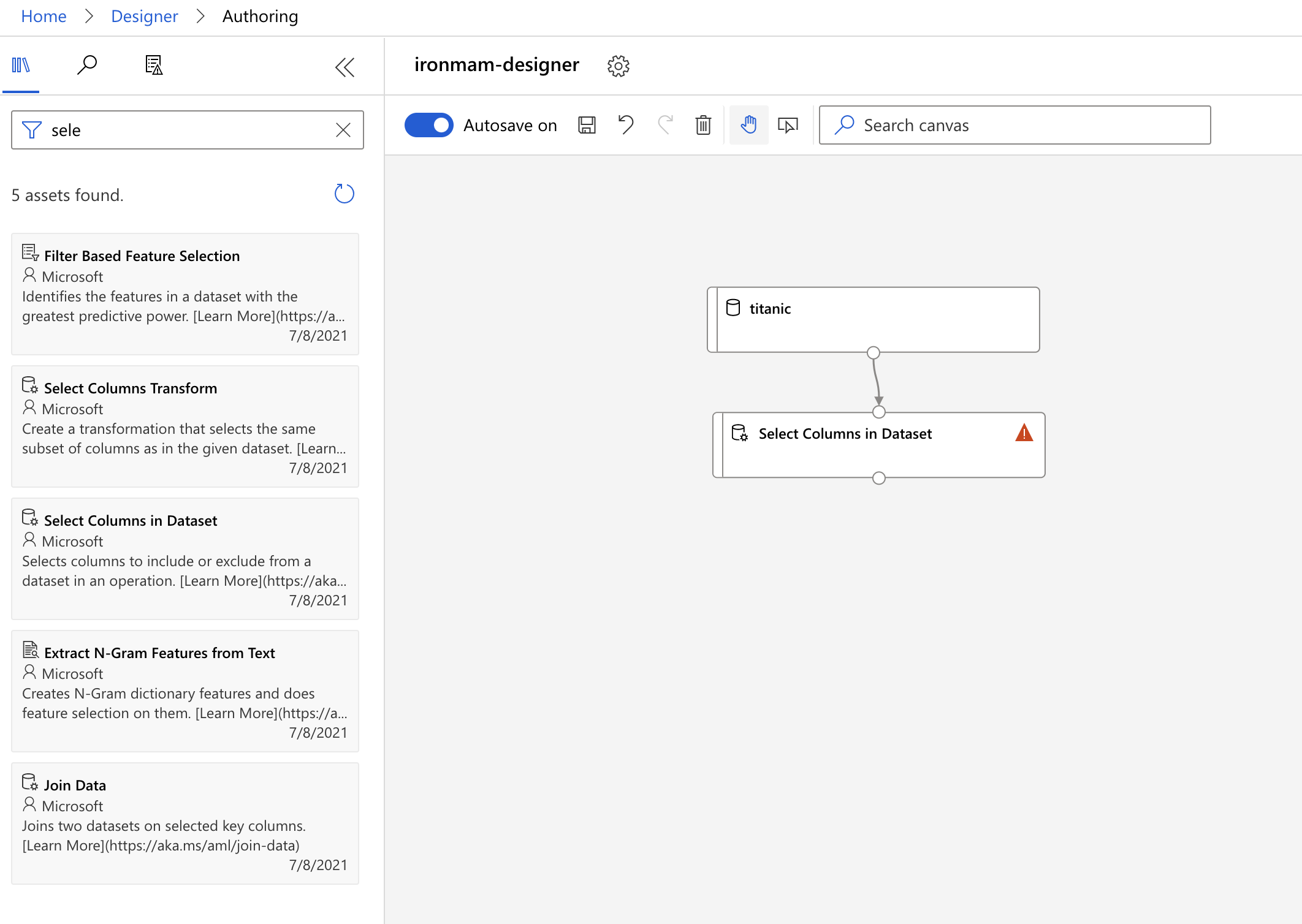
-
接着我们选择想要的 columns,点击方框後右边会跳出选单,选 select columns。一般来说都需要 Survived 这个必选,因为我们是要预测这个人是否还存活。剩下我选 Pclass, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked 这些栏位。
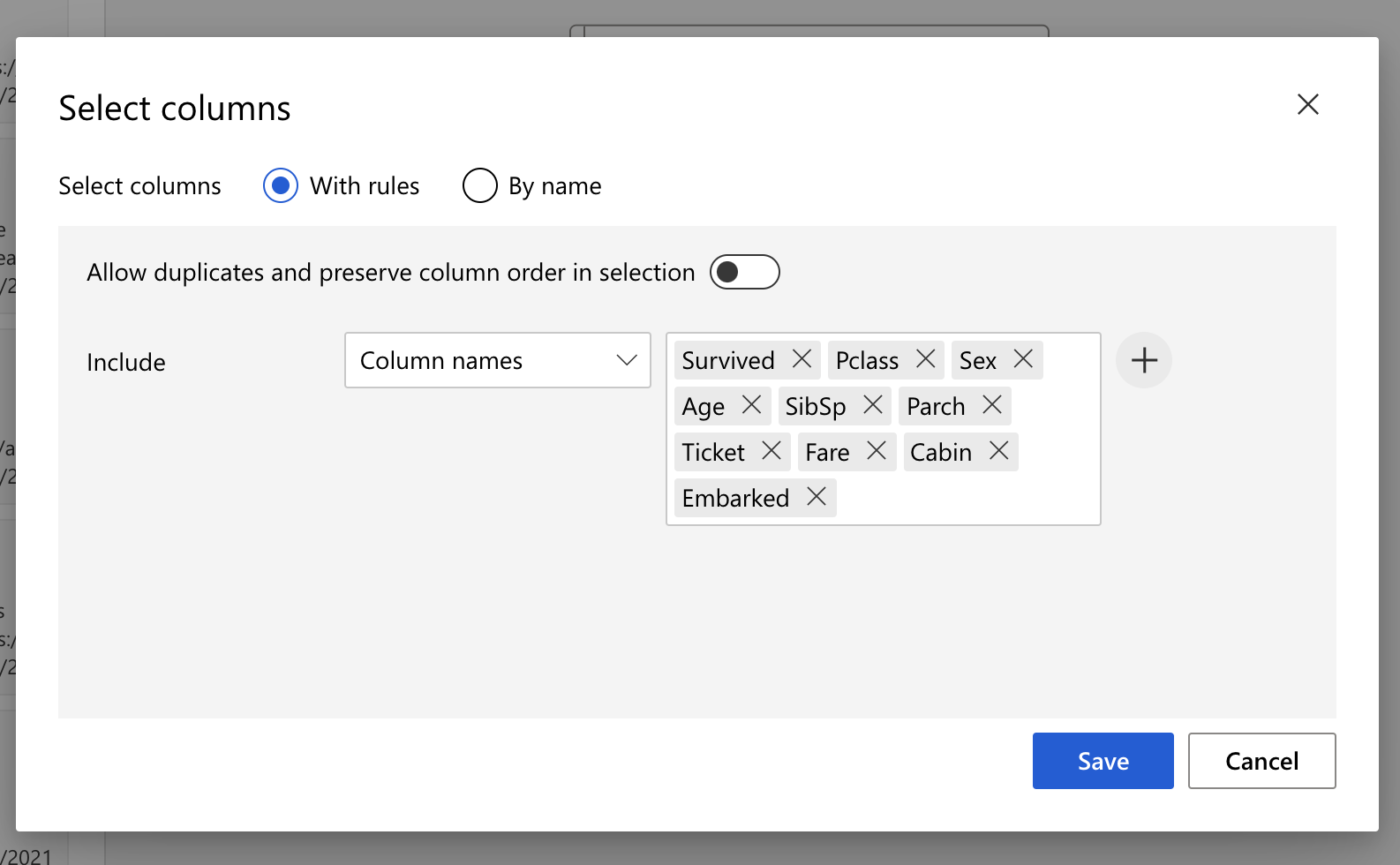
-
接着我们在 asset library 输入
Clean Missing Data,用它来清理资料。一样把上一个方框拉箭头到下一个方框。
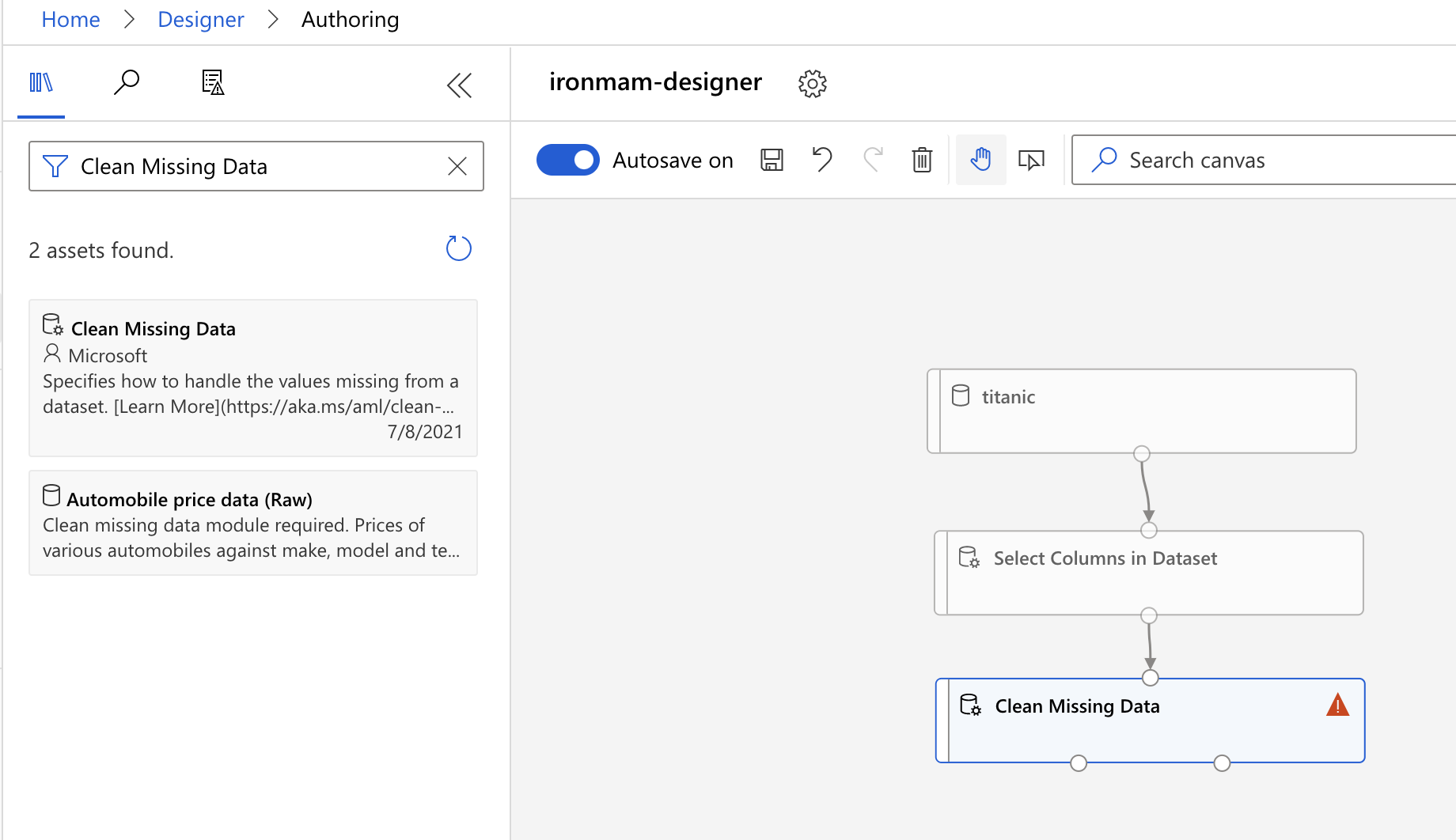
-
接着在右边的选单,点击 Columns to be cleaned,这里我选了 Age, Cabin, Embarked。
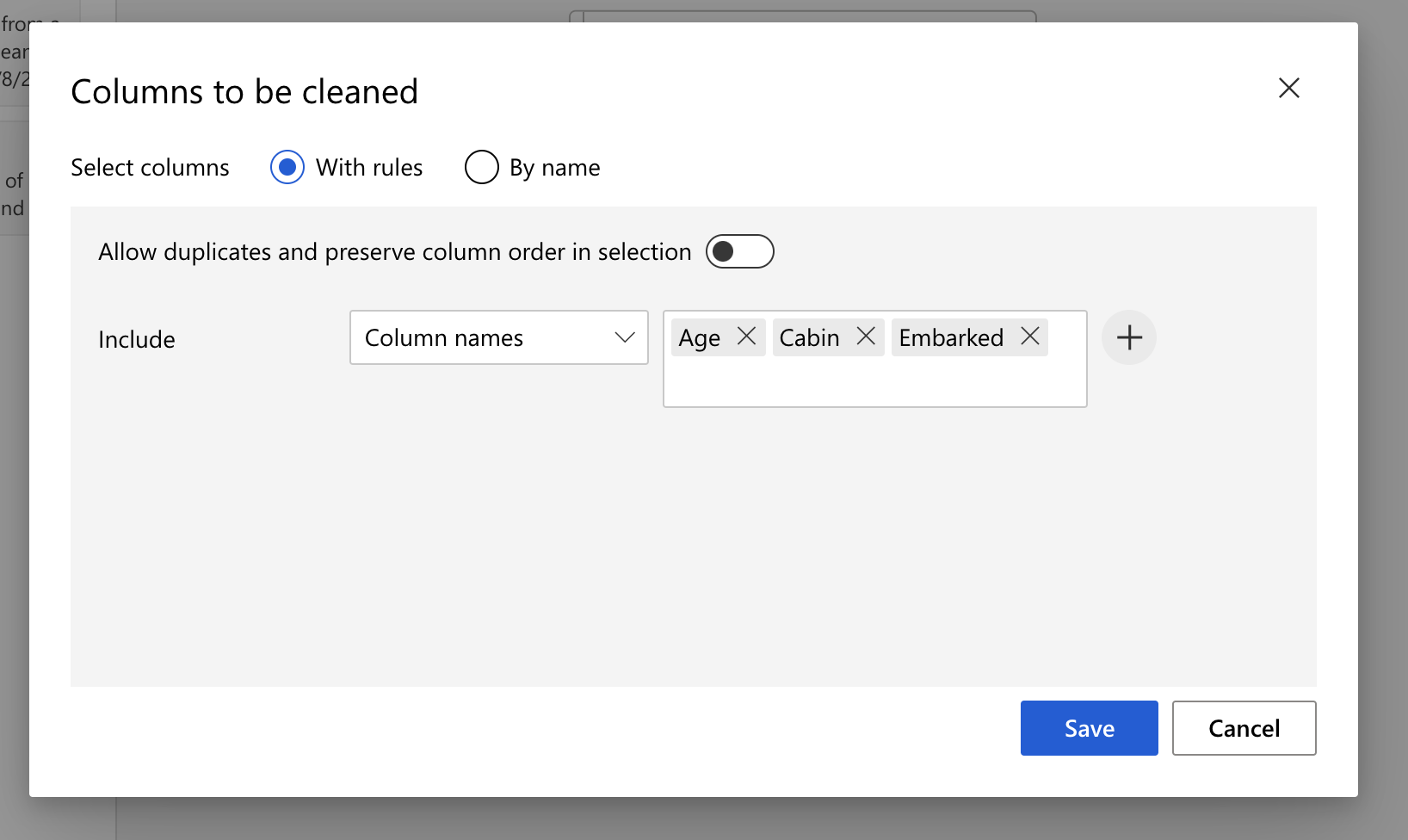
-
有一些遗失值补值的栏位可以选填,不过我们就让他先维持原始值。
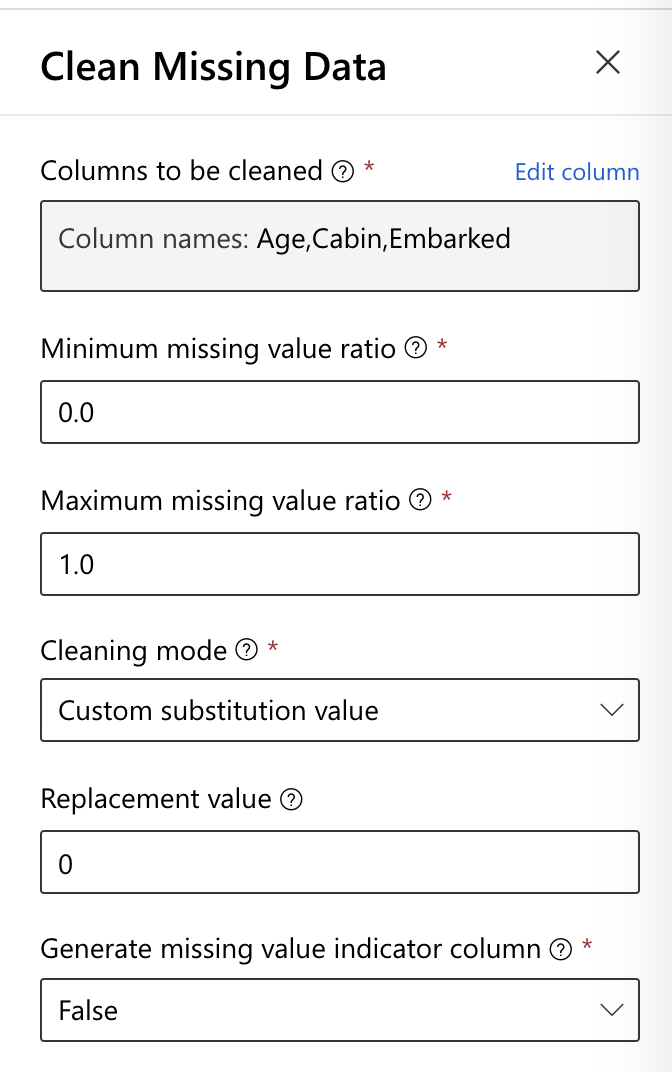
-
接着在右边 asset library 输入
Split Data,我们用它来切分训练和测试的资料。注意Clean Missing Data的方框,要用左边的点点连接到Split Data,左边的点点才是已经清理完的资料。
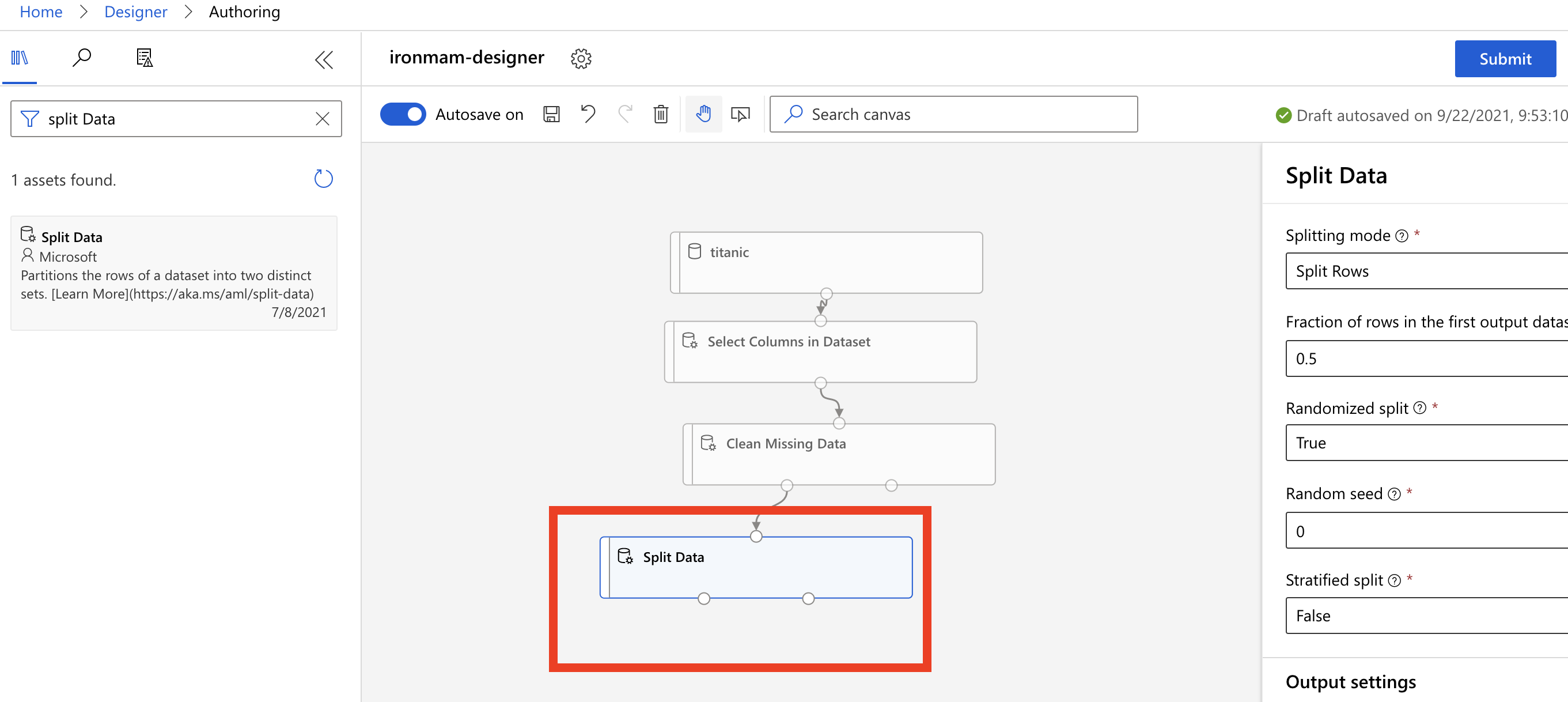
-
一样点击
Split Data的方框,会有一些数值可以设定,一般至少会去调整资料的比例,我们这边就先设预设值就好了。
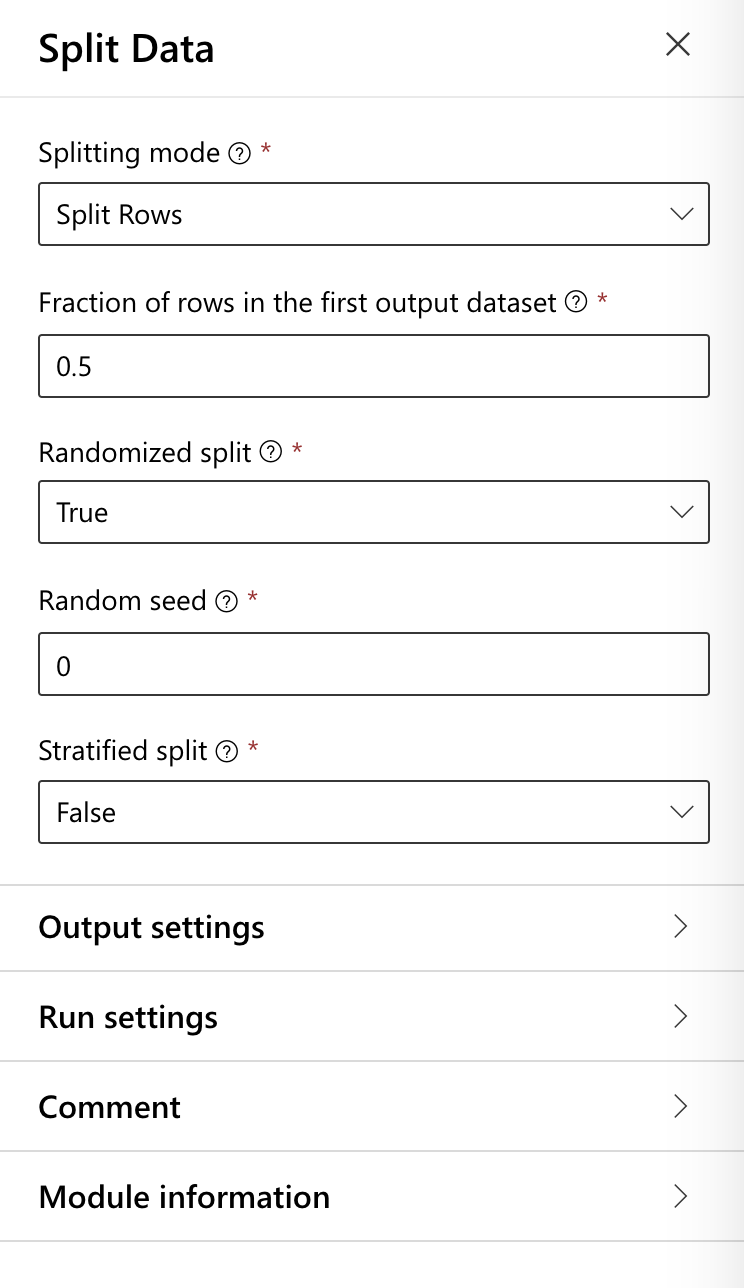
开始训练
-
在右边 asset library 输入
filter based feature selection,拖曳到 Canvas 中,用Split Data左边的点点连接到它。这个方框主要是告诉 AI 你要训练的是哪个栏位,我们今天要知道铁达尼号上谁活了下来,所以在 target column 里选 Survived 那个栏位。
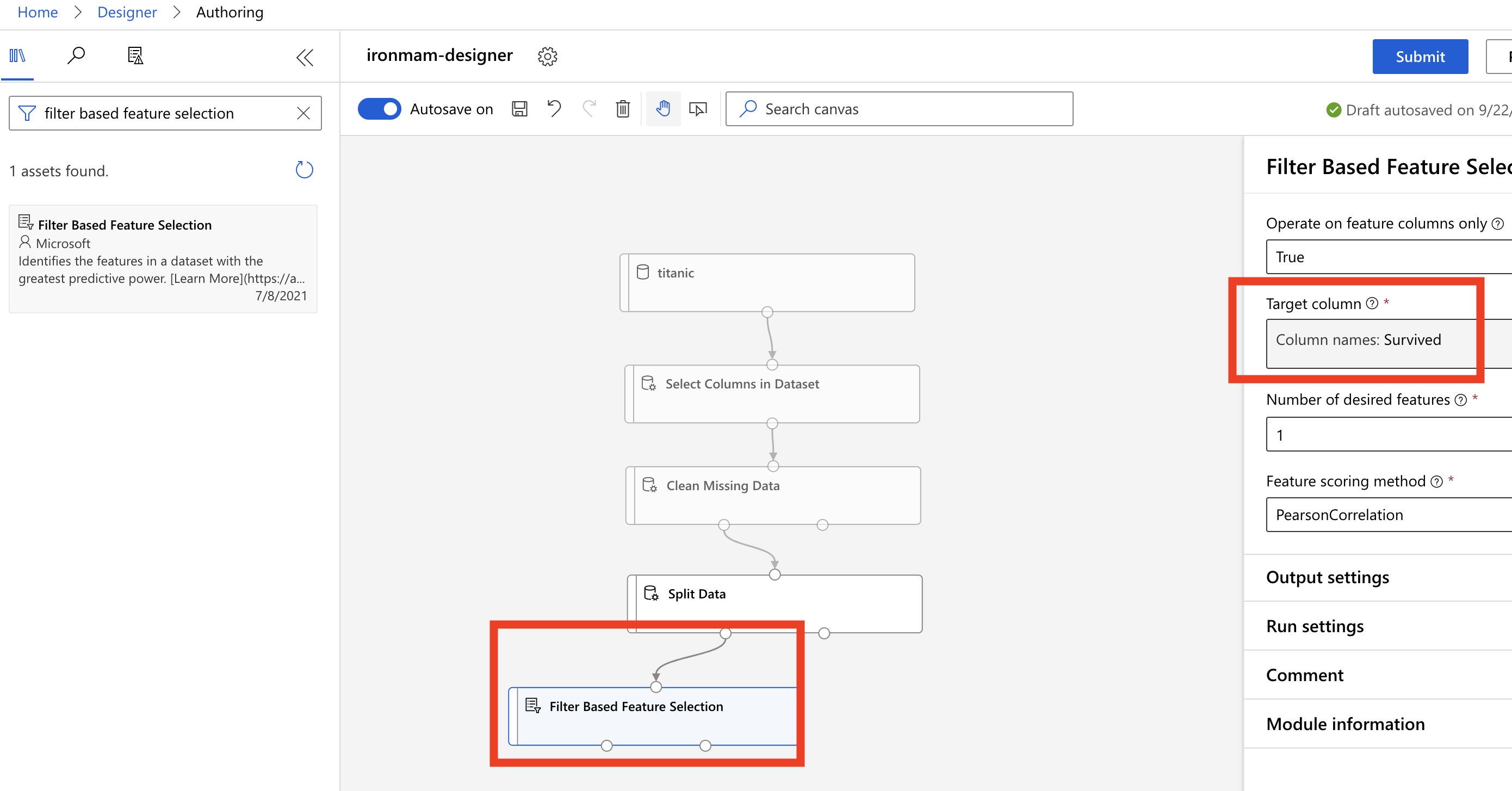
-
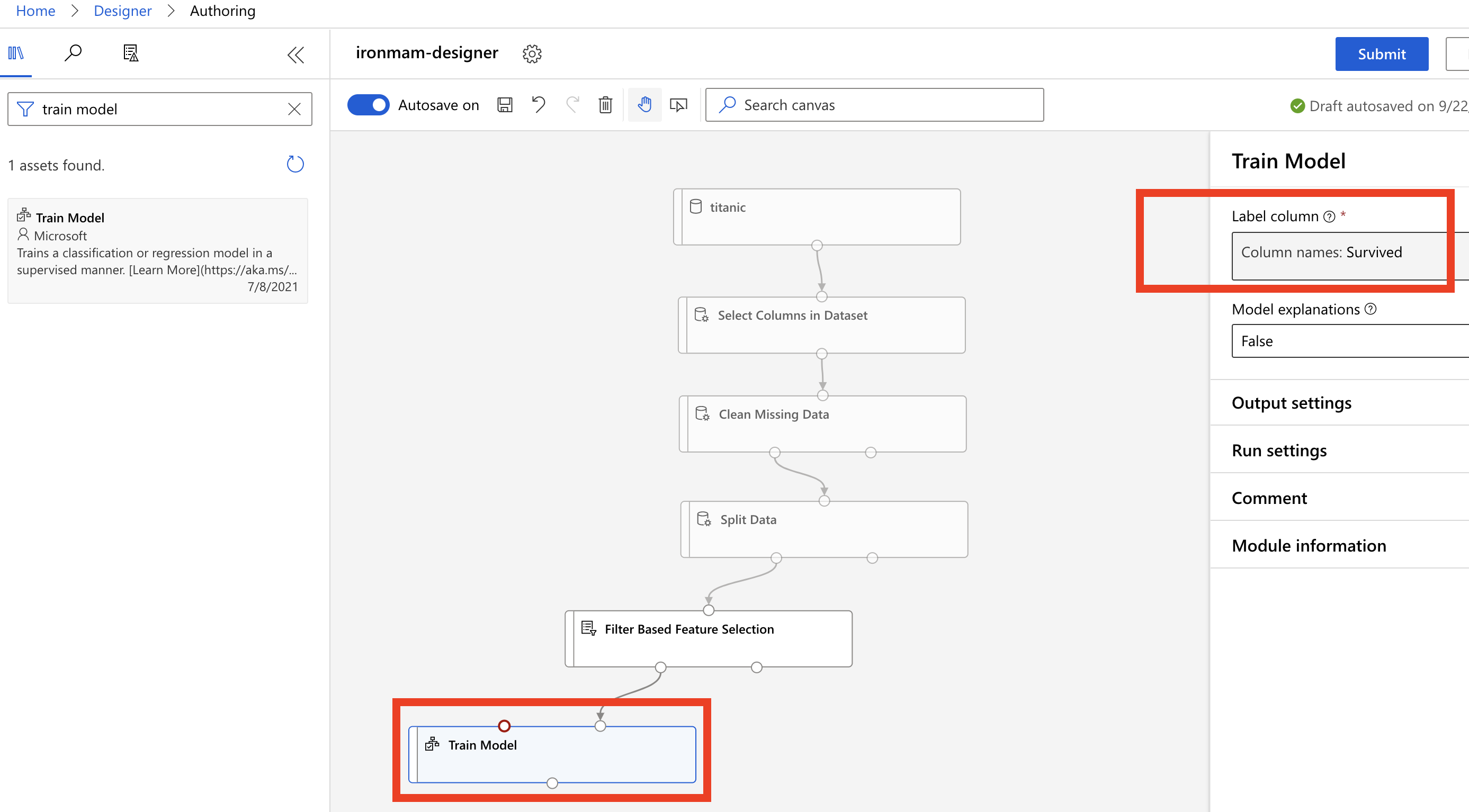
在右边 asset library 输入
train model,拖曳到 Canvas 中,用filter based feature selection左边的点点连接到它。 Train model 的右边方框,在 Label Column 选择 Survivde。
-
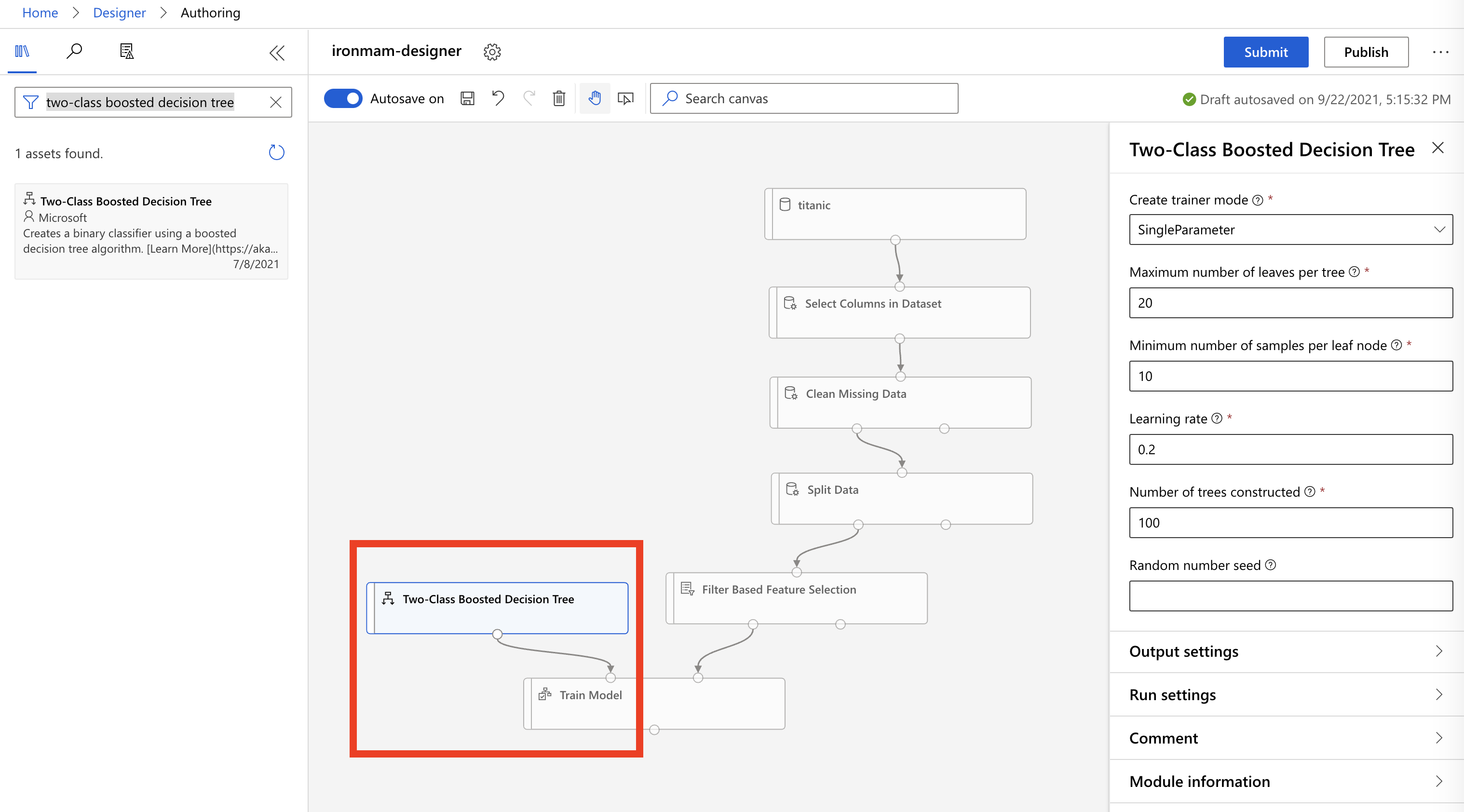
在右边 asset library 输入
two-class boosted decision tree,拖曳到 Canvas 中,并连接到train model上面的左边点点。我们决定用这个演算法是因为只有死和活两种结果,大家也可以看看 asset 里有什麽其他的算法可以使用。右边选单我们就选保持原始值。
-
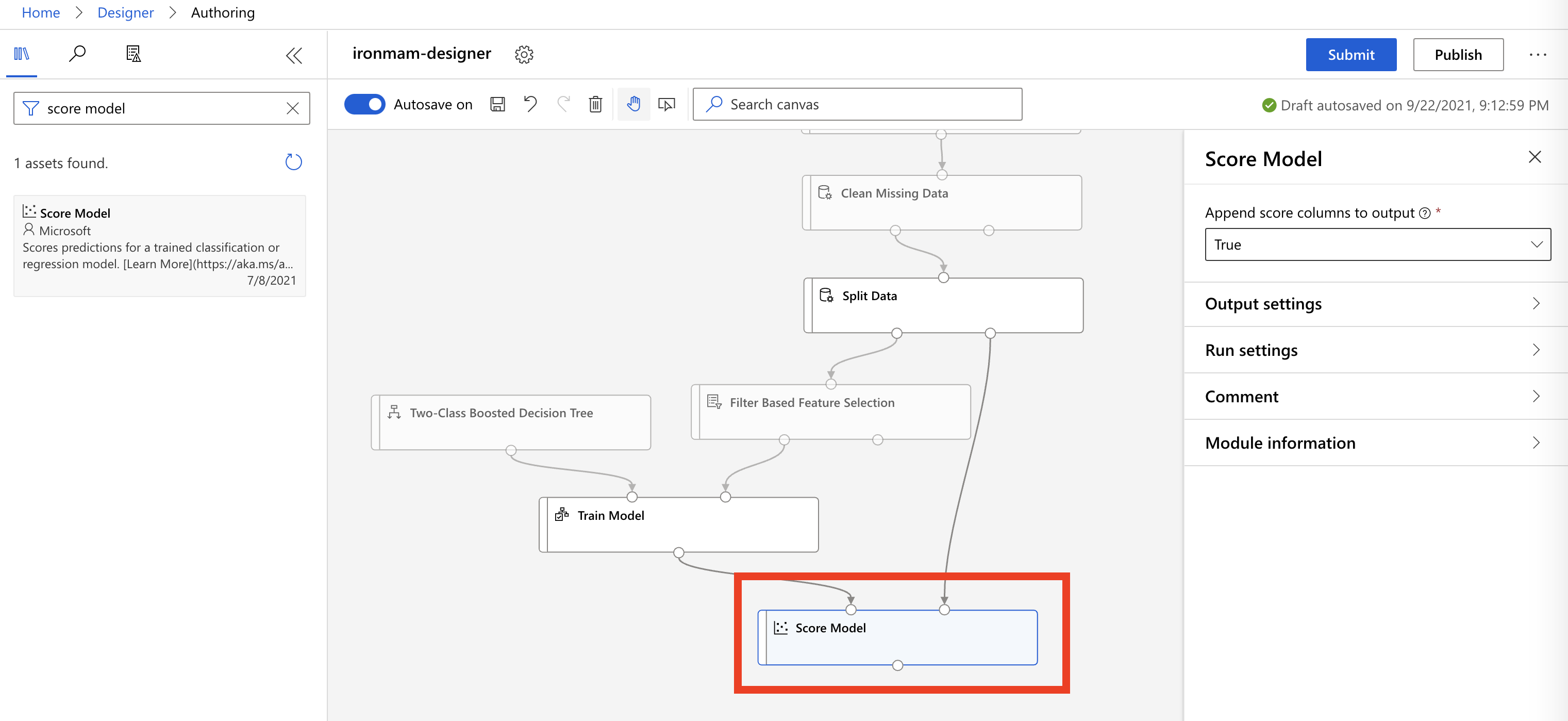
在右边 asset library 输入
score model,拖曳到 Canvas 中,train model连接到它左边的点,然後我们之前分割的另一组资料集,连接到它右边的点,用以为模型打分。
-
在右边 asset library 输入
evaluate model,拖曳到 Canvas 中,score model连接到它左边的点。
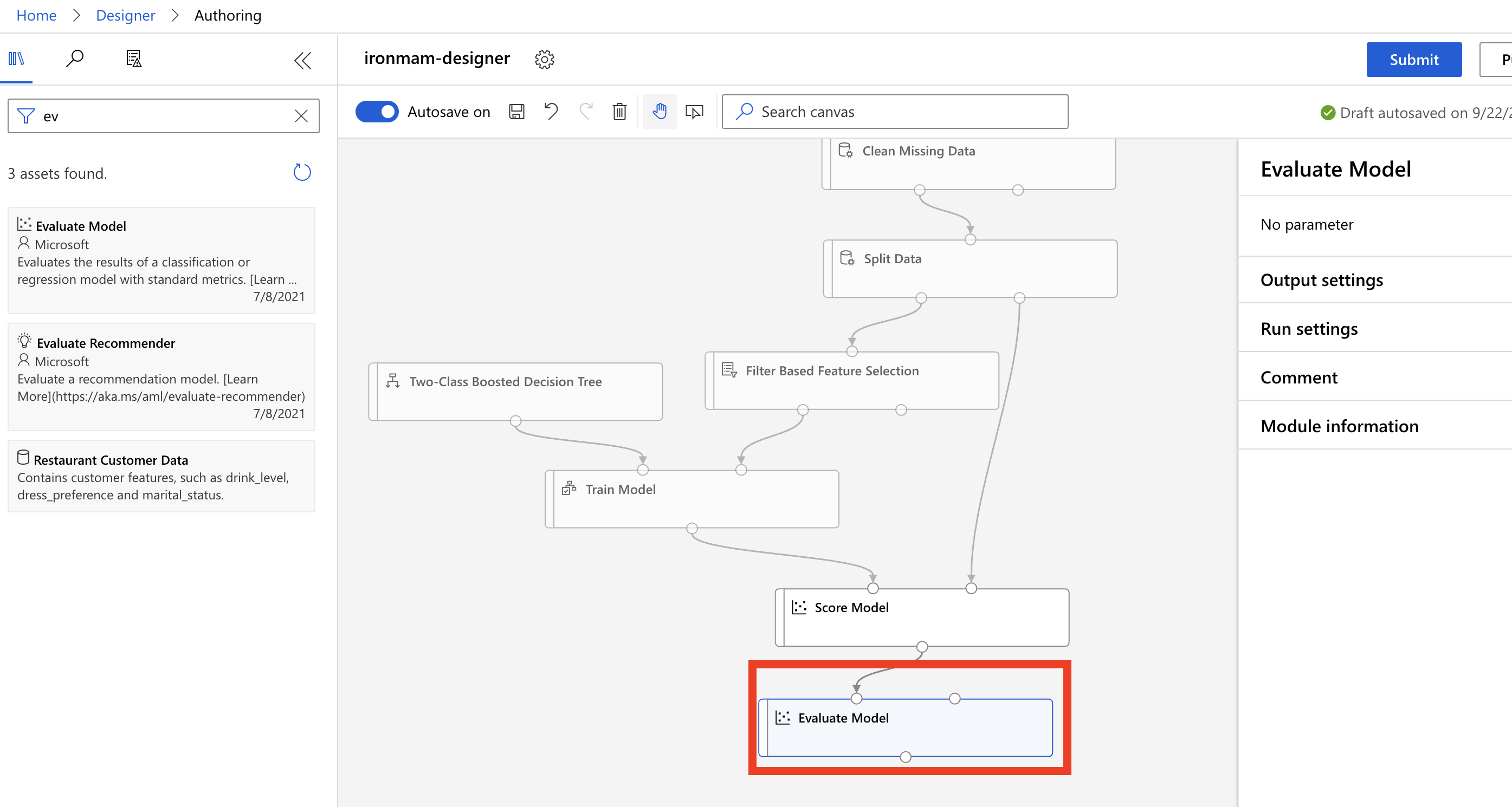
-
从资料汇入到资料清洗到训练模型再到评估模型,这下子我们就完成了一个简单的训练啦!现在图中就是我们一个完整的 pipeline,按下右上角的 submit 吧!
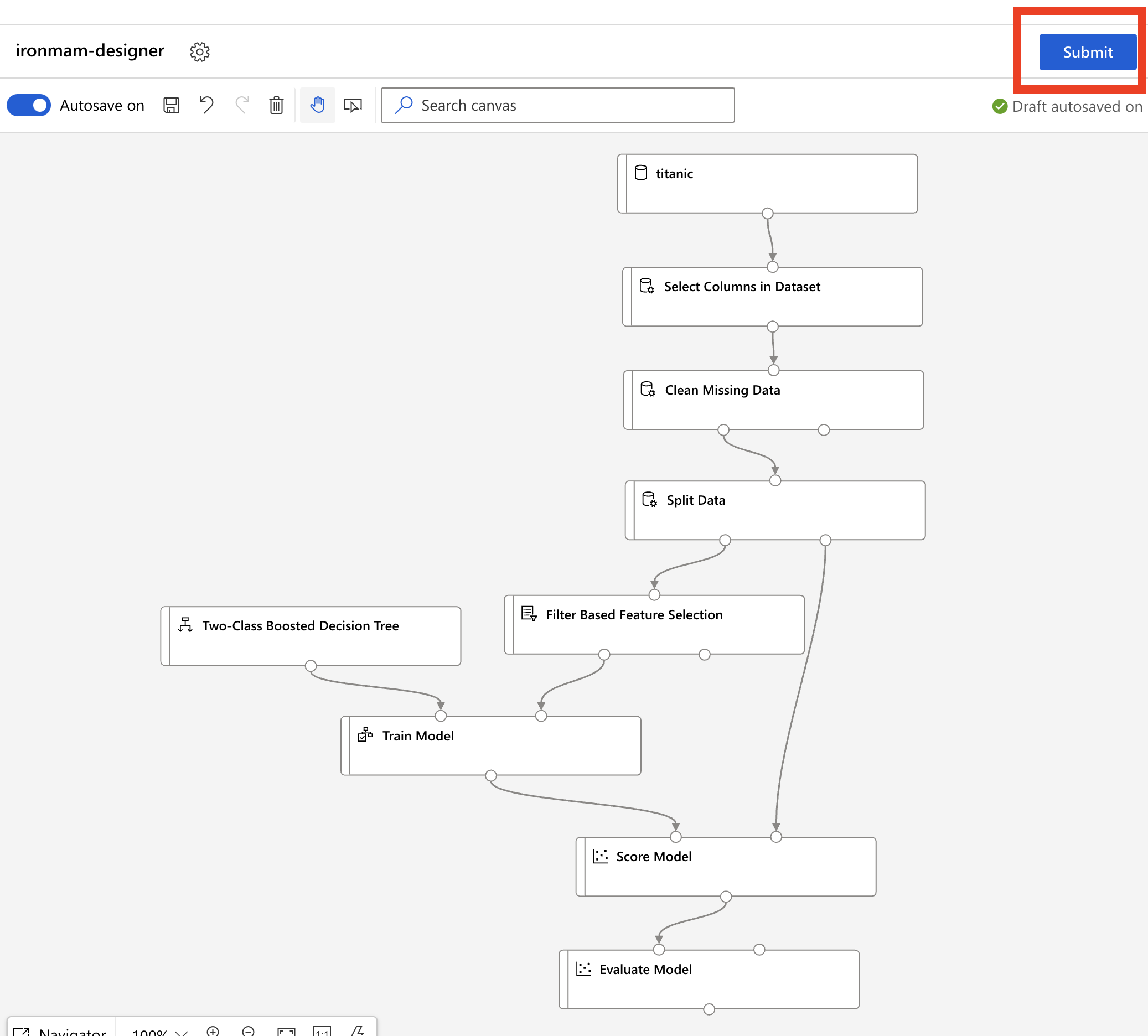
-
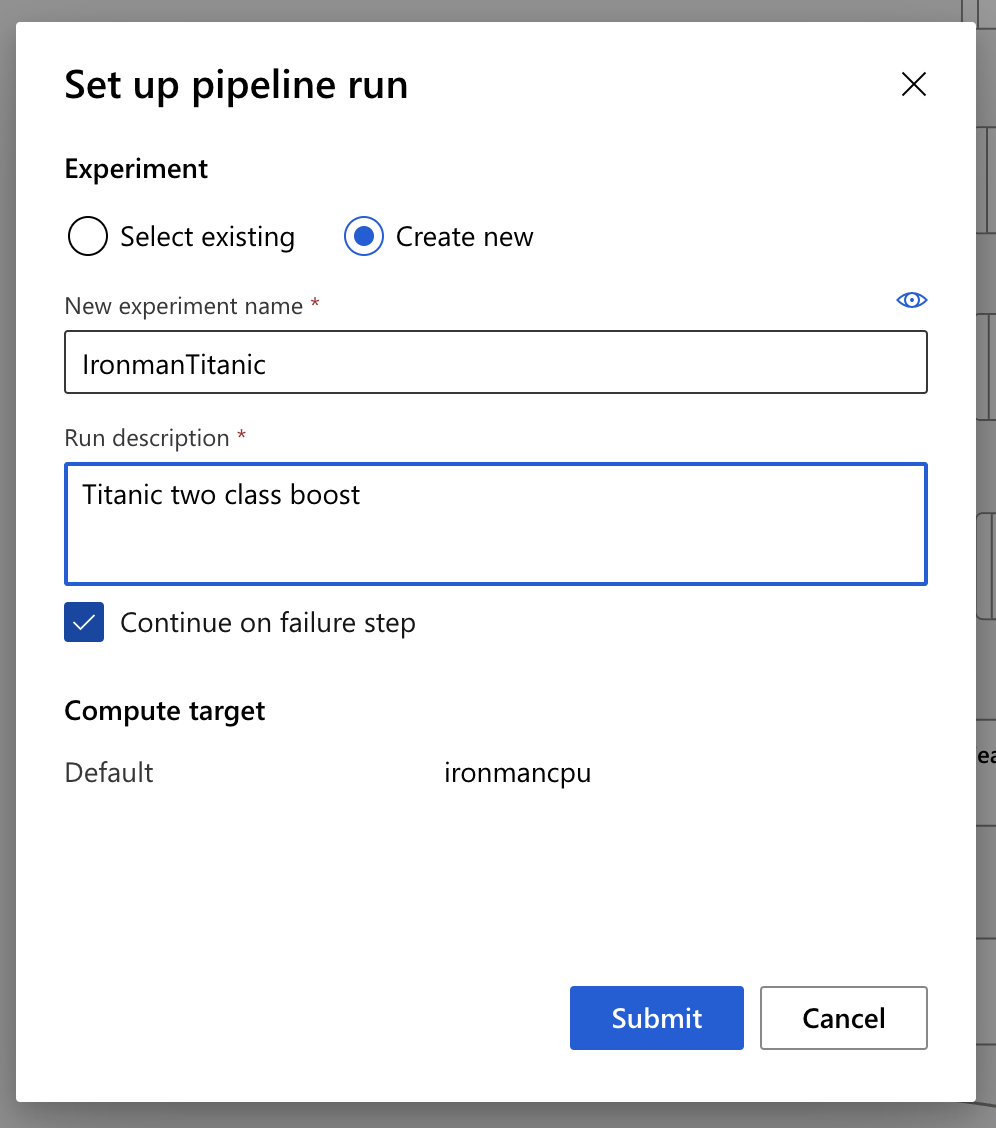
接着我们选择 Create New,建立一个新的 Experiment 并取名字,然後在 Run description 里输入这一次要跑的资讯。这里我们先有个观念,Experiment 是 Run 的集合。然後按下 Submit,就开始训练模型罗!这时候先去泡杯茶休息一下,需要等待一段时间。
-
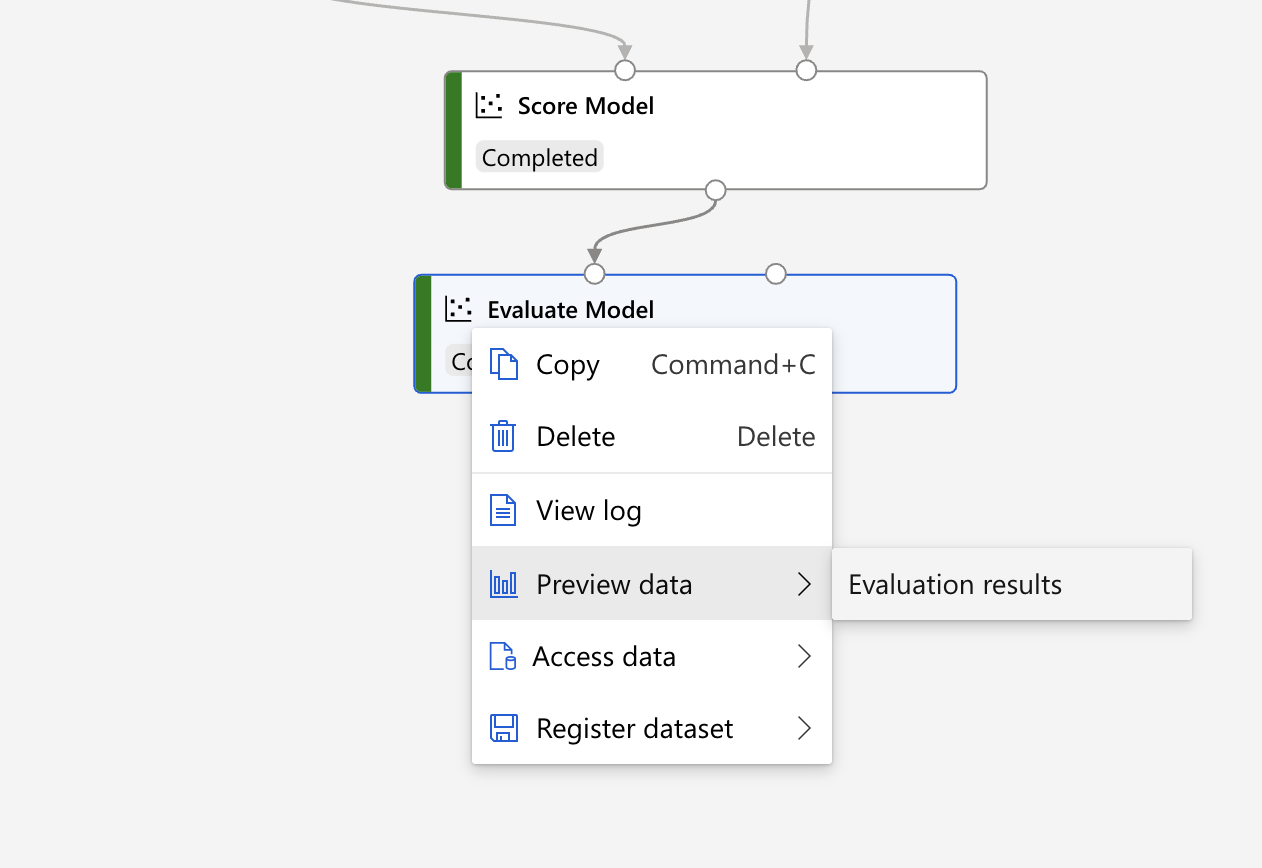
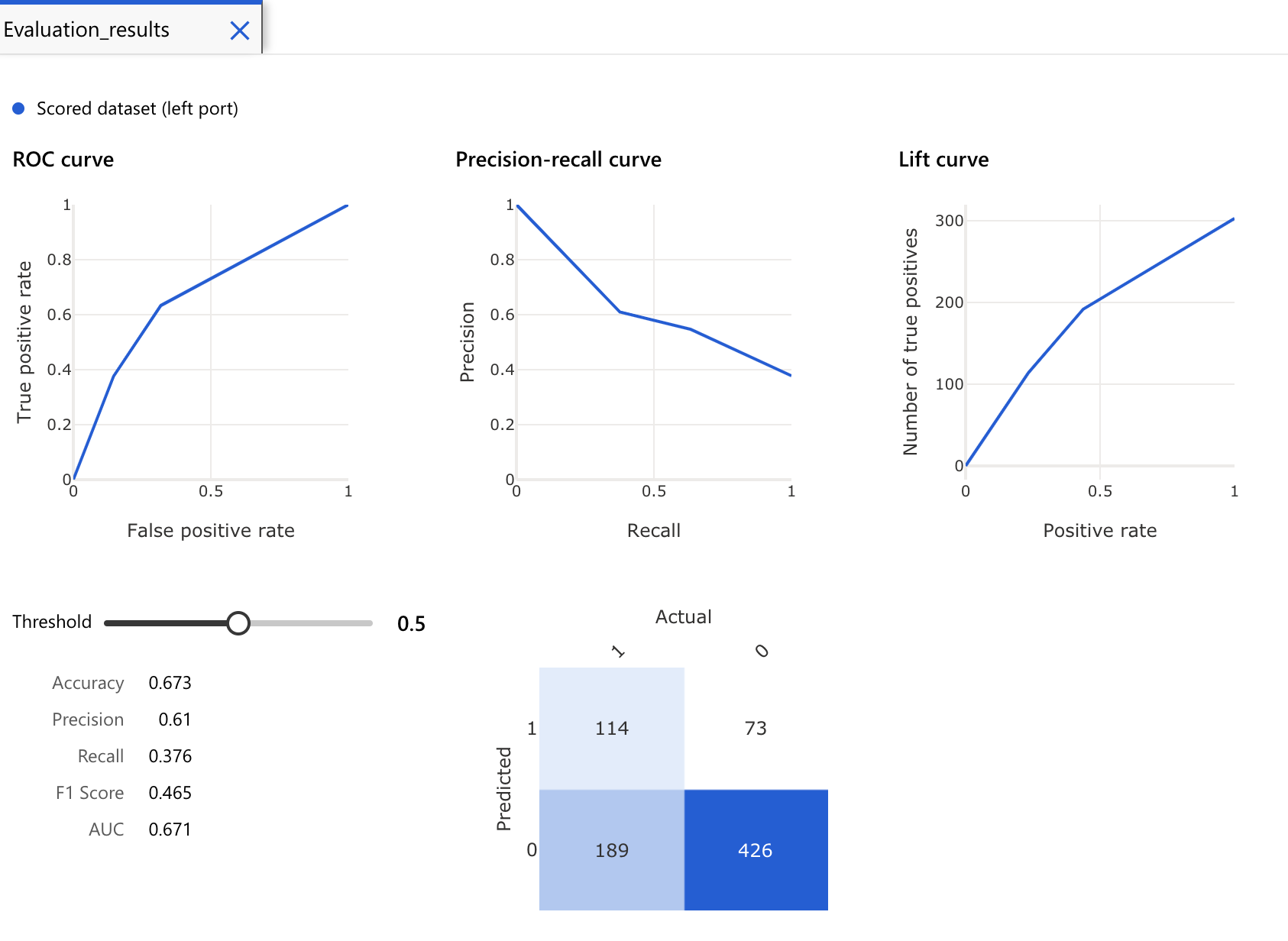
等到全部都出现绿字的 complete 之後,可以在
Evaluate model方框按右键,看 Evaluate result。
-
它连 Confusion Matrix 的相关资料都帮你画好了,真的很贴心。果然没有用力调整模型,训练出来的结果就是会比较差 XDD。
不知不觉今天又破千字了,明天我们再来谈谈怎麽用 Designer 部署训练好的模型。
>>: [Day7] 用 Python 实作 VAR 多变量时间序列预测
day 10 - 千万不要放过error
在Go的世界里面, 如果error没接好, 服务就会直接panic了。panic发生在k8s环境中,...
Day 22 bert 文字情感分类
BERT (Bidirectional Encoder Representations from T...
Day19 iPhone捷径-电池健康度
Hello 大家, 我今天看到疯先生有分享一个电池寿命的捷径, 今年13跟去年的12差别不大, 我一...
【Day29】iOS相关分享
其实在github上面找 awesome 啥的可能就很容易找到相关的资料整理 另外,知乎上面的问题&...
[Golang]单向channel介绍
1. channel有分,单向、双向,通常情况下,只说channel,就是指双向channel。 那...