DAY28 Aidea专案实作-AOI瑕疵检测(3/4)
接续上一章的资料前处理後,今天要进入训练模型的流程,让我们继续看下去~
载入相关套件
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import categorical_crossentropy
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Model
from tensorflow.keras.applications import imagenet_utils
from tensorflow.keras import layers,callbacks
from sklearn.metrics import confusion_matrix
资料增强(Data Augmentation)
首先我们要先把资料汇整起来,顺便做一些增强处理,这边小提一下,在做资料增强时一定要根据图片的特性选择适当的处理,否则会导致训练不良,举个例子:我们在做手写数字辨识时,若做了水平翻转的增强,那麽6跟9的资料就会搞混。
#Data_Augmentation & Data_Normalization
train_datagen = ImageDataGenerator(
rotation_range=0,
horizontal_flip=False,
vertical_flip=False,
width_shift_range=0.05,
height_shift_range=0.05,
preprocessing_function=tf.keras.applications.mobilenet.preprocess_input
)
valid_datagen = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input)
因此我们这边的增强只做简单的水平、垂直平移,以及我们即将使用的MobileNets模型所提供的preprocessing_function,它会将所有值压缩到[-1,1],验证资料就不需要做增强,尽量让资料保持原状态即可。
将图片套进来
这边我们使用的是flow_from_dataframe的方法(DAY21有介绍),img_shape要根据模型的输入限制去设定,batch_size则是根据自身设备去设定,最後用shuffle打乱资料。
img_shape = (224, 224)
batch_size = 16
train_generator = train_datagen.flow_from_dataframe(
dataframe=train,
directory=data_path,
x_col="ID",
y_col="Label",
target_size=img_shape,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
valid_generator = valid_datagen.flow_from_dataframe(
dataframe=valid,
directory=data_path,
x_col="ID",
y_col="Label",
target_size=img_shape,
batch_size=batch_size,
class_mode='categorical',
shuffle=True)
设定一下每次训练的图片张数
def num_steps_per_epoch(data_generator, batch_size):
if data_generator.n % batch_size==0:
return data_generator.n//batch_size
else:
return data_generator.n//batch_size + 1
train_steps = num_steps_per_epoch(train_generator, batch_size)
valid_steps = num_steps_per_epoch(valid_generator, batch_size)
载入预训练模型MobileNets
套用imagenet的权重
model=tf.keras.applications.MobileNet(weights='imagenet',input_shape=(img_shape[0], img_shape[1], 3), include_top=False)
接着我们要更新输出的类别数量
num_classes=6 #共六种类别
x = layers.GlobalAveragePooling2D()(model.output)
outputs = layers.Dense(num_classes, activation="softmax")(x)
model=Model(inputs=model.inputs,outputs=outputs)
Compile一些参数
lr=1e-4
model.compile(
loss="categorical_crossentropy",
metrics=["accuracy"],
optimizer = tf.keras.optimizers.Adam(lr)
)
设定模型训练机制
这边用到的套件功能是callbacks,它可以在模型训练的过程中帮我们实现一些操作,这边我们增加的功能有:
- model_mckp:用来储存训练过程中,准确率最高的模型
- earlystop:假如模型一段时间内都没有进步,那就提前终止模型训练
model_dir = './model-logs'
if not os.path.exists(model_dir):
os.makedirs(model_dir)
modelfiles = model_dir + '/{}-best-model.h5'.format('B0')
model_mckp = callbacks.ModelCheckpoint(modelfiles,
monitor='val_accuracy',
save_best_only=True)
earlystop = callbacks.EarlyStopping(monitor='val_loss',
patience=10,
verbose=1)
callbacks_list = [model_mckp, earlystop]
增加资料不平衡的惩罚权重(上一章提到的)
class_weights = {i:value for i, value in enumerate(class_weights)}
记得开启GPU训练-变更执行阶段类型
tf.config.list_physical_devices('GPU')
开始训练
history=model.fit_generator(train_generator,steps_per_epoch=train_steps,
epochs=100,
validation_data=valid_generator,
validation_steps=valid_steps,
class_weight=class_weights,
callbacks=callbacks_list)
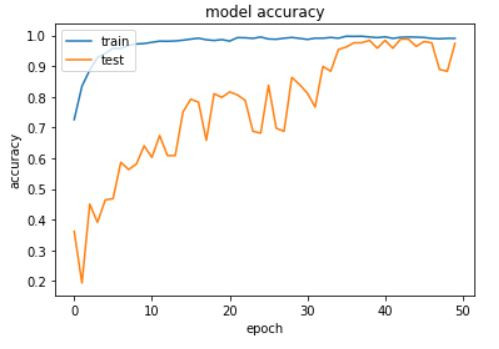
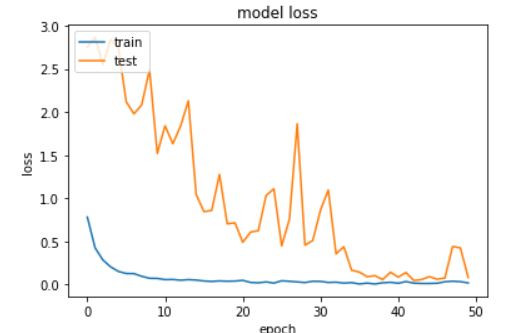
训练完毕後我们可以用图表来看一下训练的状况,分别画出Accuracy以及Loss的图,确定没有过度拟合或欠拟和的状况发生。
import matplotlib.pyplot as plt
#print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
接着做测试
我们自己挑了100张图片出来放到一个资料夹,一样要先将资料进行汇整。
data_path = "/content/drive/MyDrive/AOI"
test_list = pd.read_csv(os.path.join(data_path, "test.csv"), index_col=False)
data_path = "/content/drive/MyDrive/AOI/test_images"
test_datagen = ImageDataGenerator(preprocessing_function=tf.keras.applications.mobilenet.preprocess_input)
test_generator = test_datagen.flow_from_dataframe(
dataframe=test_list,
directory=data_path,
x_col="ID",
y_col="Label",
target_size=img_shape,
batch_size=batch_size,
class_mode='categorical',
shuffle=False)
test_steps = num_steps_per_epoch(test_generator, batch_size)
预测结果
#预测出来会是机率,因此要经过转换
y_test_predprob = model.predict(test_generator, steps=test_steps)
y_test_pred = y_test_predprob.argmax(-1)

混淆矩阵
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
print(f"accuracy_score: {accuracy_score(y_test, y_test_pred):.3f}")
confusion = confusion_matrix(y_test, y_test_pred)
plt.figure(figsize=(5, 5))
sns.heatmap(confusion_matrix(y_test, y_test_pred),
cmap="Blues", annot=True, fmt="d", cbar=False,
xticklabels=[0, 1], yticklabels=[0, 1])
plt.title("Confusion Matrix")
plt.show()
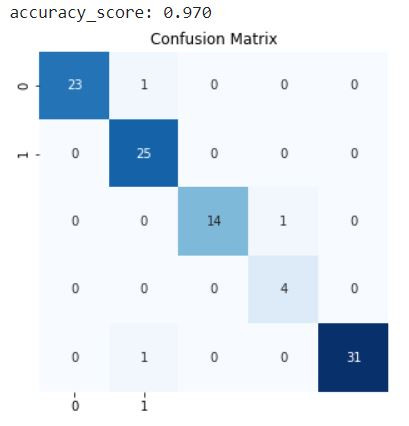
可以看到模型的表现还是挺不错的,准确率高达0.97,这边解释一下为什麽混淆矩阵的大小是55,因为小编在抓图片到测试资料集的时候漏抓了2类瑕疵(horizontal defect)的资料,实在是不好意思~
那麽模型的训练就到这边告一段落罗,我们将结果上传到竞赛平台後就可以得到系统计算的成绩了,Accuracy可能会有些许的差距那是正常的,明天就是这个专案的最後一个章节了!我们会使用一些模型优化技巧来加强模型,大家尽请期待吧。
<<: DAY27 Aidea专案实作-AOI瑕疵检测(2/4)
Day 29 - Baseball Game
大家好,我是毛毛。ヾ(´∀ ˋ)ノ 废话不多说开始今天的解题Day~ 682. Baseball G...
第二十九日-MYSQL预存程序 STORED PROCEDURE:来写一个BMI小程序(2)
昨天已经认识分隔符号 DELIMITER和STORED PROCEDURE建立语法, 建立出BMI小...
[Day1] JavaScript Drum Kit
关於 Javascript 30天 课程介绍 Javascript30,是由加拿大全端工程师 Wes...
误用/滥用测试(Misuse/Abuse testing)
-HTTP请求(来源:Chua Hock-Chuan) 测试人员在HTTP请求中操纵URL的查询字...
Day 27 Spark local mode
Spark local mode Environment Ubuntu HP Z230 数量: 1 ...