DAY27 Aidea专案实作-AOI瑕疵检测(2/4)
那我们要开始着手处理我们的资料集了,今天会先做资料前处理的部分,其实不管是机器学习或是深度学习,只要是资料分析,我们的处理步骤都大同小异,都是先了解资料的特性,进行一些前处理,再去选择模型来训练,那我们就开始吧!
挂载到云端硬碟并更新环境路径
# 云端执行须执行这行,取得权限
from google.colab import drive
drive.mount('/content/drive')
# 云端执行须执行这行,变更环境路径
os.chdir("//content/drive/MyDrive/AOI")
os.getcwd()
读取资料
我们要读取的资料有两个,一个是train.csv,里面包含了图片的ID及Label,另一个是图片档。
data_path = "/content/drive/MyDrive/AOI"
train_list = pd.read_csv(os.path.join(data_path, "train.csv"), index_col=False)
data_path = "/content/drive/MyDrive/AOI/train_images" #路径挂载到存放图片的资料夹路径
img = cv2.imread(os.path.join(data_path, train_list.loc[0, "ID"]))
看一下图片的资讯
print(f"image shape: {img.shape}")
print(f"data type: {img.dtype}")
print(f"min: {img.min()}, max: {img.max()}")
plt.imshow(img)
plt.show()
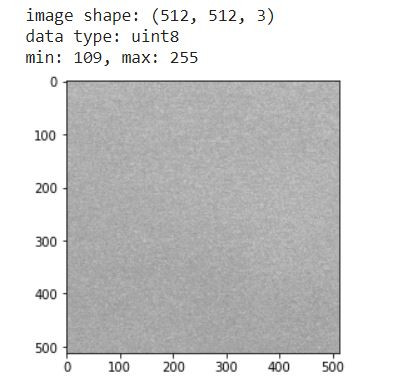
把同类别的图片放到一个list
normal_list = train_list[train_list["Label"]==0]["ID"].values
void_list = train_list[train_list["Label"]==1]["ID"].values
horizontal_defect_list = train_list[train_list["Label"]==2]["ID"].values
vertical_defect_list = train_list[train_list["Label"]==3]["ID"].values
edge_defect_list = train_list[train_list["Label"]==4]["ID"].values
particle_list = train_list[train_list["Label"]==5]["ID"].values
label=[normal_list,void_list,horizontal_defect_list,vertical_defect_list,edge_defect_list,particle_list]
查看每种类别的图片
plt.figure(figsize=(12, 6))
for i in range(6):
plt.subplot(2, 3, i+1)
img = cv2.imread(os.path.join(data_path, label[i][i]),0)
plt.imshow(img,cmap='gray')
plt.axis("off")
plt.title(f"img shape: {img.shape}")
plt.suptitle(f"Variety of samples", fontsize=12)
plt.show()
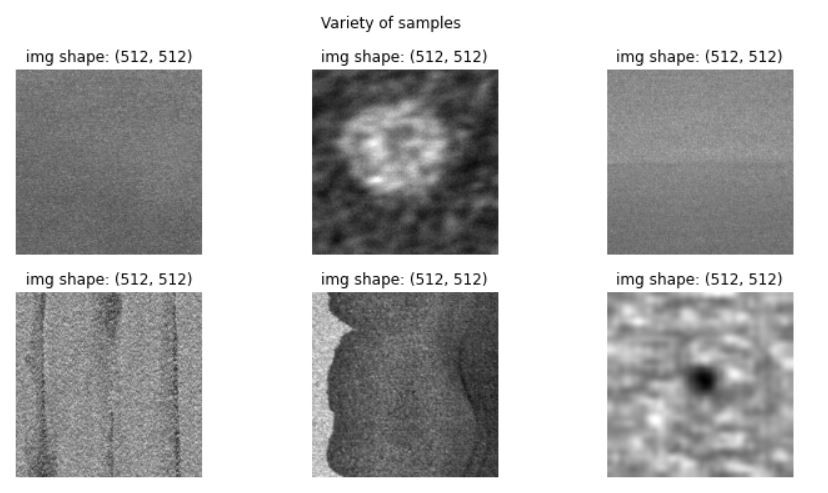
我们也可以利用直方图来查看像素的分布状况
plt.figure(figsize=(12, 6))
for i in range(6):
plt.subplot(2, 3, i+1)
img = cv2.imread(os.path.join(data_path, label[i][i]),0)
plt.hist(img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=7)
plt.ylabel("Frequency", fontsize=7)
plt.suptitle(f"Variety of samples", fontsize=12)
plt.show()
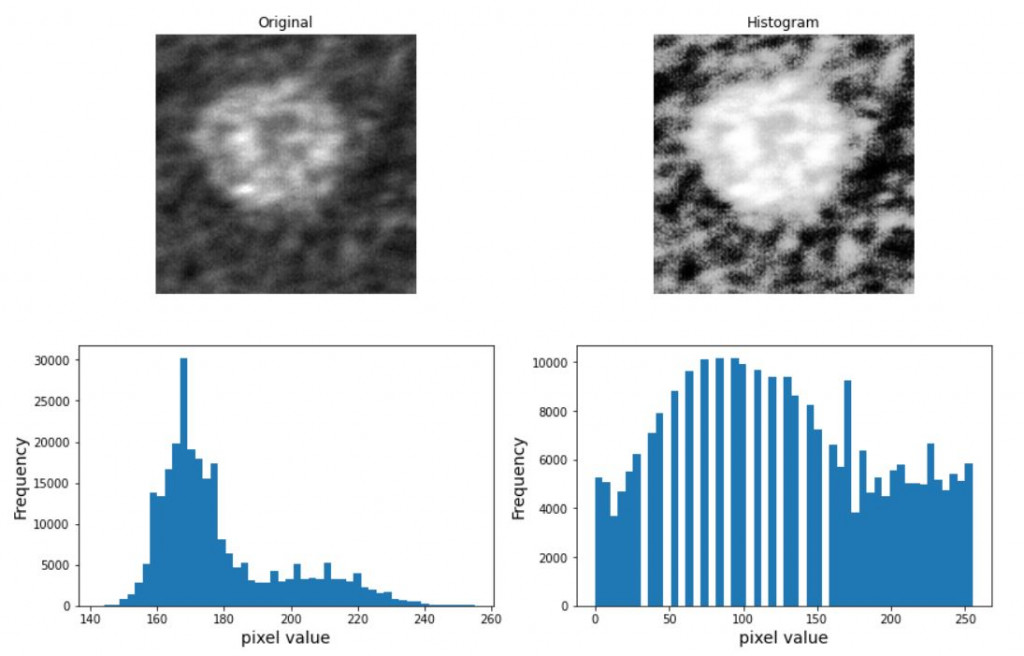
还记得我们前面提过的值方图均衡化(Histogram Equalization)和局部均衡化(createCLAHE)吗?我们来试试效果在这边如何。
#Histogram Equalization
equalize_img = cv2.equalizeHist(img)
plt.figure(figsize=(14, 9))
plt.subplot(2, 2, 1)
plt.imshow(img, cmap="gray")
plt.axis("off")
plt.title(f"Original")
plt.subplot(2, 2, 2)
plt.imshow(equalize_img, cmap="gray")
plt.axis("off")
plt.title(f"Histogram")
plt.subplot(2, 2, 3)
plt.hist(img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.subplot(2, 2, 4)
plt.hist(equalize_img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.show()
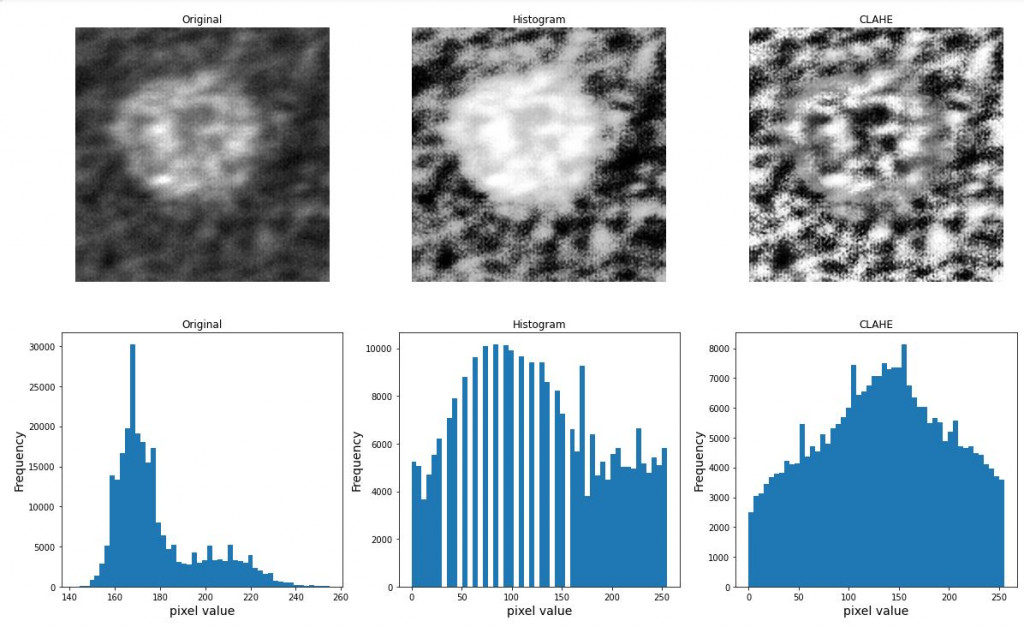
#CreateCLAHE-局部均衡化
clahe = cv2.createCLAHE()
clahe_img = clahe.apply(img)
plt.figure(figsize=(20, 12))
plt.subplot(2, 3, 1)
plt.imshow(img, cmap="gray")
plt.axis("off")
plt.title(f"Original")
plt.subplot(2, 3, 2)
plt.imshow(equalize_img, cmap="gray")
plt.axis("off")
plt.title(f"Histogram")
plt.subplot(2, 3, 3)
plt.imshow(clahe_img, cmap="gray")
plt.axis("off")
plt.title(f"CLAHE")
plt.subplot(2, 3, 4)
plt.hist(img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.title(f"Original")
plt.subplot(2, 3, 5)
plt.hist(equalize_img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.title(f"Histogram")
plt.subplot(2, 3, 6)
plt.hist(clahe_img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.title(f"CLAHE")
plt.show()
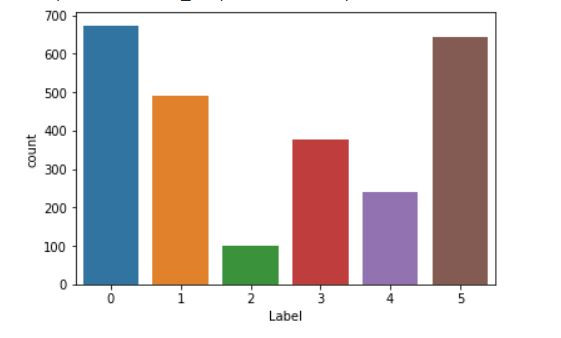
切分资料
再切割资料前我们也顺便看一下资料的分布状况
train_list["Label"].value_counts()
sns.countplot('Label', data=train_list)
#切分资料
from sklearn.model_selection import train_test_split
train,valid= train_test_split(train_list,test_size=0.2,random_state=666)
#重制index
train.reset_index(drop=True,inplace=True)
valid.reset_index(drop=True,inplace=True)
#改变Label型态
train["Label"]=train["Label"].astype("str")
valid["Label"]=valid["Label"].astype("str")
处理资料不平衡
上图我们发现资料分布好像不是很平均,2类跟4类的样本数有点偏少,这边我使用的方法是增加较重惩罚职权重给样本数少的类别,让训练的时候模型会更加注重这些样本,藉此来达到平衡的目的。
unique, counts = np.unique(y_train.values, return_counts=True)
print("unique ", unique)
print("counts: ", counts)
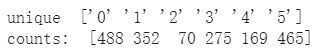
#adjust weight
from sklearn.utils.class_weight import compute_class_weight
class_weights = compute_class_weight('balanced',unique,y_train)
print(class_weights)
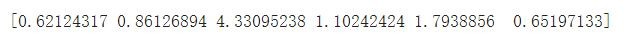 .
.
前处理的部分我们就到这边告一段落,稍微了解了一下图片的特性,下一章节我们就要开始做资料增强以及训练模型了,加油,我们已经完成一半了!
<<: DAY26 Aidea专案实作-AOI瑕疵检测(1/4)
>>: DAY28 Aidea专案实作-AOI瑕疵检测(3/4)
Day 28: 拯救失足专案,在现有专案内引入KMM
Keyword: KMM in exist project KMM这麽好,但是我们专案已经开发了五年...
Day 7. 算了,假装我成功假装我有VR头盔好了
其实我有头盔的,只是你们看不见而已。 我HMD Mock, vive input utility, ...
(急)毕业问卷填写
https://docs.google.com/forms/d/1YL9riLzCASVo7hkaO...
【C++】Bubble Sort
气泡排序是一种简单的排序演算法,它有两个回圈走访,一个在前(i),一个在後(i+1)。 如果前後的顺...
.NET Core第19天_SelectTagHelper的使用
SelectTagHelper : 是对HTML原生 tag的封装 预设下拉选单会透过asp-for...