Day 6 - 从 foot-printing 开始
出於书本 Chapter 4. Hacking Methodology
看看别人能看见什麽 - foot-printing
一个从外部收集各式各样关於组织内部资讯的过程,有两种方式
- 搜寻引擎
- 执行网路扫描 (network scans),探测通讯埠 (port) 以及透过存取漏洞 (vulnerabilities) 来查找出系统中的特定资讯。
起手式 - 网路搜寻
作者与许多骇客喜欢的还是 google 搜寻引擎。有几种使用方式
- 使用关键字搜寻
- 使用进阶搜寻,这个方式通常可以找到其他更多资讯,如供应商、客户 (client) 以及其他企业夥伴 (affiliations) 等。
- 使用 switch search,以下面语法搭配敝司官网为例:
# site:domain_name <关键字>
site:kkstream.com encoding
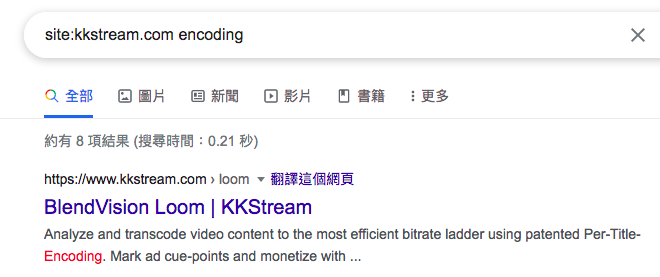
不是在打广告啦(羞)
也可以针对档案格式搜寻,以下面语法搭配搜寻敝司为例
#filetype:档案格式 <关键字>
filetype:pdf kkstream
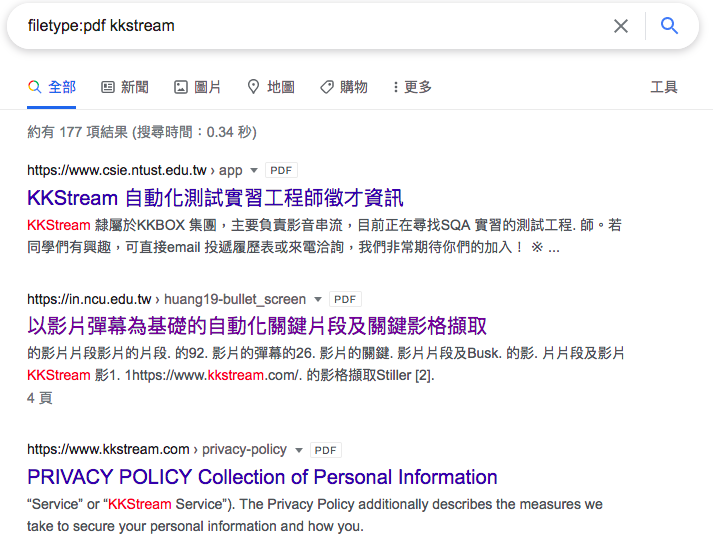
有没用的招募资讯,也有论文,到第三个才出现官网的隐私权政策。
网路爬虫
不外乎可以挖掘
- 网页排版以及参数
- 网页的 HTML 与 Script 原始码
- HTML 注解 (HTML Comment)
注解栏位通常夹带许多有用的资讯,比如个资、服务器名称、版号甚至是程序码怎麽运作
特殊网站
- 透过如 https://finance.yahoo.com 可查到公开的公司资讯
- 使用 USSearch 或是 ZabaSearch 查找个人资讯。自己玩了一下,搜寻结果都是在美国或北美洲比较多。
Whois
对骇客来说,whois 是展开社交工程攻击与网路扫描不错的起点
- 网域注册的资讯,像是联络人的电话、电子邮件地址等
- whois365 或是 whois godaddy 都可以查找出网域名称的可用性以及相关的注册资讯
明天来看看其他的扫描方式
<<: 卡夫卡的藏书阁【Book7】- Kafka 实作新增 Topic
前端工程学习日记第三天
小技巧:ul>li*3 打出来 可以用emmet快速做出 昨日疑问:我的HTML为何没有快速工...
番外篇(1)一起来做计算机!
距离完赛已经过了一阵子,前天想自己刻刻看计算机,拆解任务、实际执行後才发现知识量不足,导致无法顺利完...
自动化 End-End 测试 Nightwatch.js 之踩雷笔记:iframe
<iframe> <iframe> 是在 HTML 用来内嵌另外一个 HTM...
网格交易机器人第一天测试纪录
感觉还是有bug,他会一直买停不下来,可能要再找一两天请假来盯着机器人,然後上线前下单的金钱限制要设...
第廿八天:旅游结束的周二
今天要出发回台北了。 早上去附近早餐店吃个东西,咸豆浆蛋饼煎包都是常见的选择,不过咸豆浆加了...香...