【6】为什麽 Batch size 通常都是设成2的n次方
有没有人发现几乎每个在开源的专案上,Batch size 都是2的N次方,像32, 128, 256等,经过我在 stackoverflow 查询後,找到了 Intel 官方文件中提到:
In general, the performance of processors is better if the batch size is a power of 2.
原来是因为实体处理器通常也都是2的N次方,为了能让处理器妥善运用,所以这麽设定,但基於好奇,我想来测试一下是否在遇到 batch size 位2的N次方时,训练时间真能够缩短?
SHUFFLE_SIZE=1000
LR = 0.1
EPOCHS = 50
def train(batch_size):
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(batch_size)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
verbose=False)
cost_time = timeit.default_timer()-start
print(f'training done. bs: {batch_size} cost: {cost_time} sec')
return timeit.default_timer()-start
我们做写一个 train function,需要带入测试的 batch size,我们会计算 model.fit() 花多久时间,由於 colab 有使用时间限制,epoch 不宜设过大,batch size 的部分我取[14, 15, 16, 17, 18, 30, 31, 32, 33, 34] 这十种来测试,理想上,我们应该会发现在 batch_size=16和32时,训练所花时间应该会少一些。
测试结果:
training done. bs: 14 cost: 827.863105417 sec
training done. bs: 15 cost: 847.0526322110004 sec
training done. bs: 16 cost: 853.054406965 sec
training done. bs: 17 cost: 790.5390958839994 sec
training done. bs: 18 cost: 859.2583510040004 sec
training done. bs: 30 cost: 910.454973295 sec
training done. bs: 31 cost: 778.0074432720003 sec
training done. bs: 32 cost: 874.4872942829998 sec
training done. bs: 33 cost: 823.8228452820003 sec
training done. bs: 34 cost: 821.9243825859994 sec
结果16和32并没有其他相对来得低,於是我又在执行第二次
training done. bs: 14 cost: 876.093458483 sec
training done. bs: 15 cost: 828.8942355509998 sec
training done. bs: 16 cost: 895.477967417 sec
training done. bs: 17 cost: 807.7159141530001 sec
training done. bs: 18 cost: 784.7428535139998 sec
training done. bs: 30 cost: 708.2653999240001 sec
training done. bs: 31 cost: 686.826350065 sec
training done. bs: 32 cost: 817.7144867099996 sec
training done. bs: 33 cost: 733.212714794 sec
training done. bs: 34 cost: 707.462420588 sec
我们将两次的成果画成图
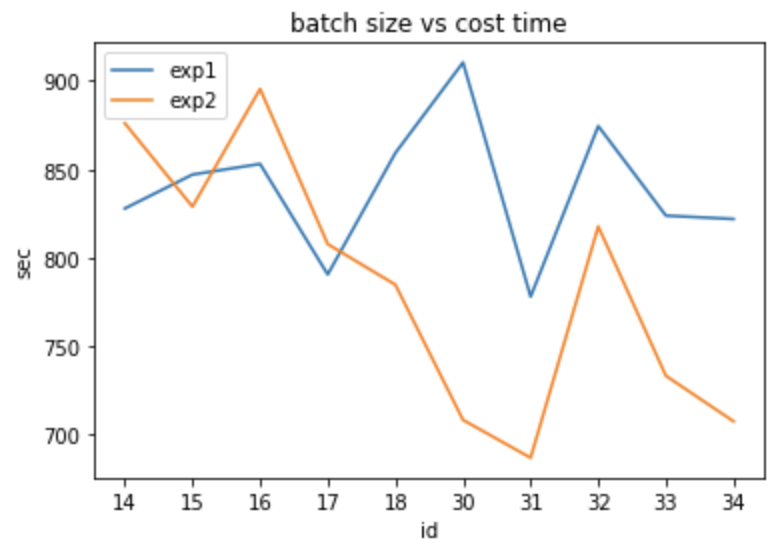
结果两次的测试当batch_size=16和32竟然都是相对花时间...当然,这有可能是 Colab 提供的 GPU 可能是共享的,所以在本次实验中失去参考性,也许在自己组装的 GPU 会有不一样的结果?
[Day - 18] - Spring SOA架构之领域驱动设计之旅
Abstract 在一个广大领域需求的市场,无论你身处哪种开发情境下,势必都会遇到需要开发API进行...
Day 30 敏捷开发最後的结果会是什麽?
敏捷开发最後的结果会是什麽? 最後我想跟大家分享一段小故事,故事大约是这样的: 男主角丹,因为车祸的...
Day27--Bootstrap&CSS文字排版&样式(5)
对元素设置.text-lowercase可将所有英文字母转为小写。 <p class=&qu...
Day 24 Azure machine learning: deploy service and inference- 模型训练完就是要拿来用啊
Azure machine learning: deploy service and inferen...
Day13 demand page 与 copy on write
前言 前面介绍了记忆体分页的管理机制,分页管理让记忆体管理不再以行程为管理的单位,而是以页为单位作为...