[Day 7] 非监督式学习-降维
非监督式学习-降维
今日学习目标
- 降维观念
- 何谓降维? 降维有什麽优点?
- 常见两种降维方法
- PCA & t-SNE
降维 (Dimension Reduction)
一般资料常见的表示方法有一维(数线)、二维(XY平面)和三维(XYZ立体)。当大於三维的资料就难以视觉化呈现,那麽我们该如何表示高维度的资料同时又不能压缩原本资料间彼此的关连性呢?这时降维就能帮助你了!降维顾名思义,就是原本的资料处於在一个比较高的维度作标上,我们希望找到一个低维度的作标来描述它,但又不能失去资料本身的特质。
为什麽要降维?
想想看如果我们能够把一些资料做压缩,同时又能够保持资料原来的特性。因此我们可以用比较少的空间,或是计算时用比较少的资源就可以得到跟没有做资料压缩之前得到相似的结果。此外资料降维可以帮助我们进行资料视觉化,二维可以用平面图表示、三维可以用立体图作表示,而大於三维的空间难以视觉化做呈现。
降维演算法
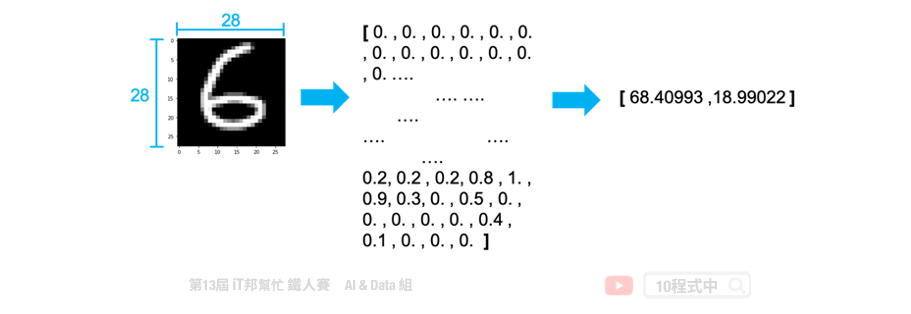
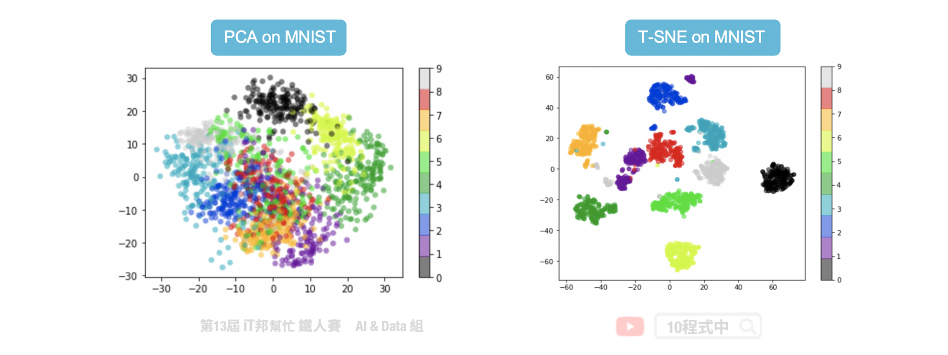
常见的降维方法有两种分别有线性方法的主成分分析(PCA)以及非线性的 t-随机邻近嵌入法(t-SNE)。下图例子是将 28*28 大小的手写数字照片,分别透过上述两种降维方法将一张 784 个像素的影像降成 2 维并投射在平面座标上。我们可以发现 PCA 降为後可以大致将 0~9 的手写数字照片在平面上分成十群,不过彼此间的界线还是很模糊。而我们透过 t-SNE 方法降为後可以看到平面上很清楚的将这十个数字分成十群。因此我们可以得知手写数字的影像在非线性的降维转换效果是比较好的。
- Principal component analysis (PCA)
- T-Distributed Stochastic Neighbor Embedding (t-SNE)
因为 t-SNE 允许非线性的转换,此外 t-SNE 使用了更复杂的公式来表达高维与低维之间的关系。因此在这种 0~9 有十个分类的情况下可以确保彼此间的距离会被区隔该而不会重叠。
Principal component analysis (PCA)
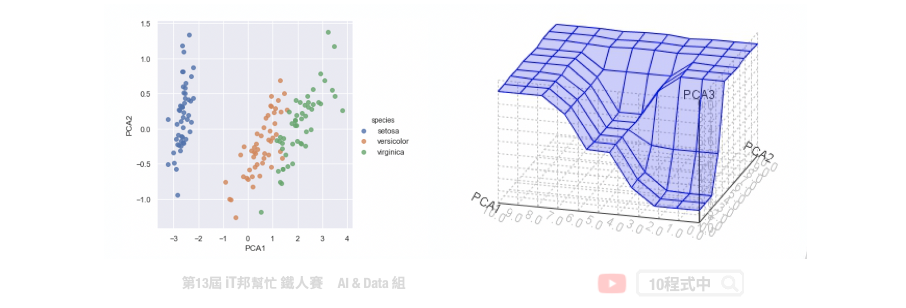
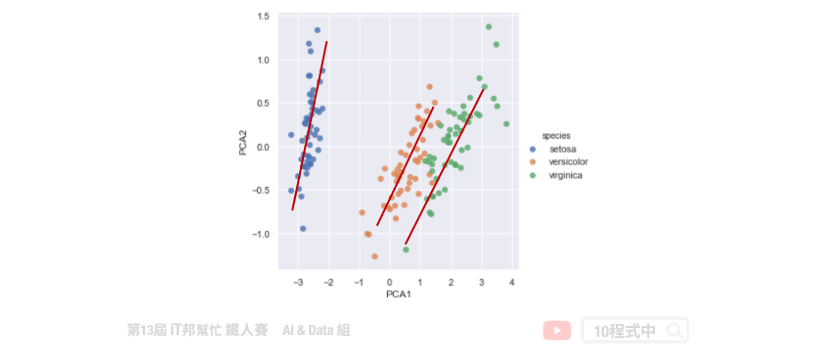
主成份分析(Principal component analysis, PCA)。其主要目的是把高维的点头影到低维的空间上,并且低维度的空间保有高维空间中大部分的性质。透过将一个具有 n 个特徵空间的样本,转换为具有 k 个特徵空间的样本,其中 k 必定要小於 n。此外 PCA 只允许线性的转换。如下图所示,我们将捐尾花朵资料集进行 PCA 降维。将原有四个特徵分别有花瓣与花萼的长与宽,透过线性转换成两维并投射在平面上。我们可以发现三种花的类别在平面上各自都有线性的趋势,也就是图中红色的线条。
PCA的主要步骤
首先一开始先求出所有资料点中心 µ,也就是将每一个资料点的平均。接着将每一个资料点减去 µ,也就是做资料点的平移,平移後原点是所有点的中心。第三步计算特徵协方差矩阵,其中矩阵对角线上分别是每个特徵的方差,而非对角线上的数值是不同特徵间彼此的协方差。协方差是衡量两个变数同时变化的变化程度,协方差绝对值越大两者对彼此的影响越大。第四步骤对矩阵进行特徵值分解,计算协方差矩阵的特徵向量和特徵值并选取特徵向量。第五步骤将特徵值由小到大排序,并选取其中最大的 k 个特徵。然後将这些 k 个特徵向量作为特徵向量矩阵。最後对资料集中的每一个特徵转换为新的特徵。
- 先求出所有资料点中心 µ
- 将每一个资料点减去 µ
- 计算特徵的协方差矩阵
- 对矩阵进行特徵值分解
- 取出最大的 k 个特徵值对应的特徵向量
- 将资料点投影到选取的特徵向量上
T-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE 目标跟 PCA 是一样的,它们都希望把高维的资料投影到低维中,并且保留高维中的点与点之间的关系与特性。两者不同的点在於 t-SNE 允许非线性的转换。因为 t-SNE 使用了更复杂的公式来表达高维与低维之间的关系。主要是将高维的数据用高斯分布的机率密度函数近似,而低维数据的部分使用 t 分布的方式来近似。
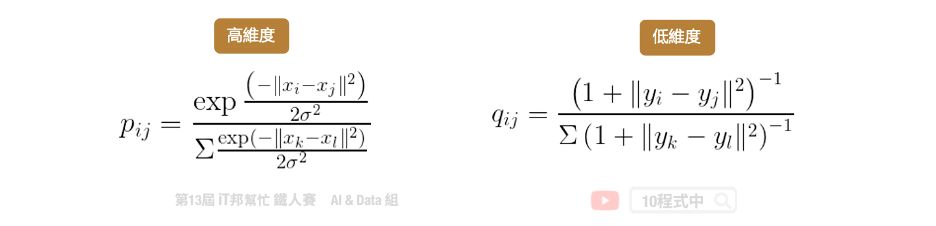
PCA & t-SNE 整理
PCA和t-SNE是两个不同降维的方法,PCA的优点在於简单若新的点要映射时直接代入公式即可得出降维後的点。若t-SNE有新的点近来时我们没有去计算新的点和旧的点之间的关系因此 我们无法将新的点投影下去。t-SNE的优点是可以保留原本高维距离较远的点降维後依然保持 远的距离,因此这些群降维後依然保持群的特性。
- PCA允许线性的转换
- t-SNE允许非线性的转换
[程序实作]
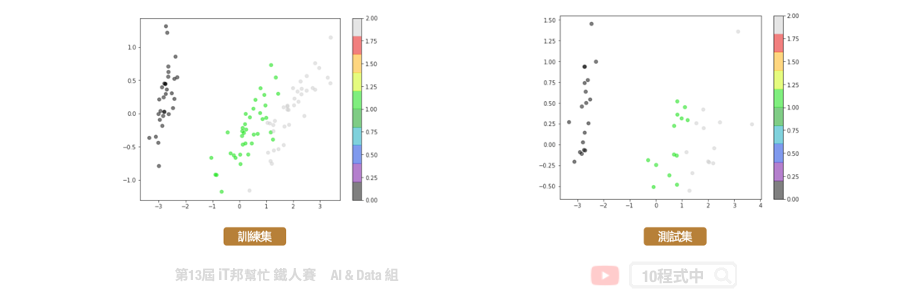
PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=2, iterated_power=1)
train_reduced = pca.fit_transform(X_train)
print('PCA方差比: ',pca.explained_variance_ratio_)
print('PCA方差值:',pca.explained_variance_)
t-SNE
from sklearn.manifold import TSNE
tsneModel = TSNE(n_components=2, random_state=42,n_iter=1000)
train_reduced = tsneModel.fit_transform(X_train)
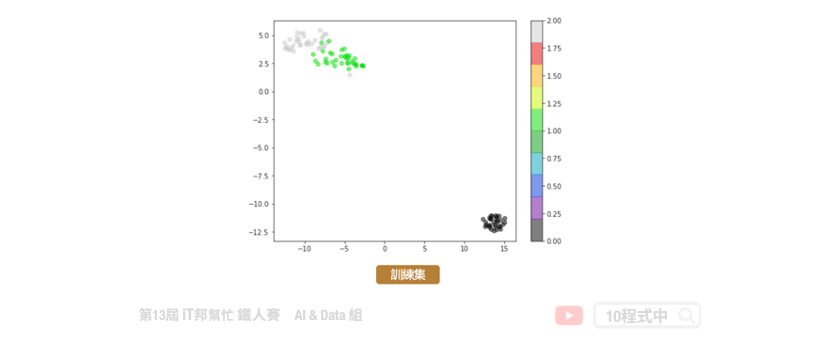
t-SNE 不适用於新资料。PCA 降维可以适用新资料,可呼叫transform() 函式即可。而 t-SNE 则不行。因为演算法的关系在 scikit-learn 套件中的 t-SNE 演算法并没有transform() 函式可以呼叫。
Reference
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: D19 - 如何用 Apps Script 自动化地创造与客制 Google Docs?(六)更改特定内容格式的 Attribute 操作技巧
>>: 30天打造品牌特色电商网站 Day.5 Figma快速上手
[Day24] Flutter with GetX Shimmer
Shimmer iOS Swift的话是类似SkeletonView 一般用在等待的时候 像是API...
DAY12 - 档案类的物件关系厘清(1) - File, FileList, Blob
前端网页若要取得一个档案,大家可能第一个画面就是下面这个UI吧!是利用<input type=...
Day 13:vim 设定档
+++ title = "Day 13:vim 设定档" date = &quo...
渗透测试-枚举(Enumeration)
-渗透侧试方法 设计该问题的目的是指出存在多种渗透测试方法,渗透测试人员可能会不一致地使用这些术语...
滥用案例(misuse cases)
-用例和滥用案例(来源:https://en.wikipedia.org/wiki/Misuse_...