Day17-sklearn(2)LabelEncoder、train_test_split
今天要介绍这两个sklearn的方法
也是资料前处理常用到的
LabelEncoder:
就如同字面上意思,会将标签做编码
当我们想把一笔资料拿去train时,必须将所有的值都转成数字,这样电脑才能看懂,因为像是字串此类型的资料是无法直接拿下去train,而有时因为资料众多将每个字串都转成数字的工作将会变得耗时又繁琐。
LabelEncoder就能快述的帮助我们做到快述的编码
import方式:

我先建立一个示范资料

使用方式:
将LabelEncoder方法指派给一个变数
之後使用fit_transform後方填入要encoder的值

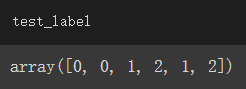
输出结果:
同为apple的字串被编为0、banana为1、orange为2
train_test_split:
快速的将资料分为训练集和验证集
import方式:

使用方式:
train_test_split後方参数第一个为特徵值、第二个target、第三个是要分成的比例
之後会回传四个值 顺序为训练集特徵值、验证集特徵值、训练集target、验证集traget

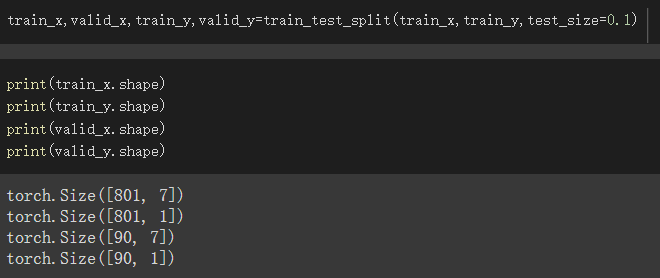
使用范例:
我使用在Titanic资料集,train_set总共有891笔资料 根据test_size=0.1
所以分成801笔与90笔
Day14 NiFi - NiFi Expression Language
今天要来介绍的是 NiFi Expression Language (以下简称NEL)。在前一篇我们...
[day-22] Python-基本认识回圈!(Part .1)
甚麽是回圈? 所谓的回圈就是重复执行某一段程序,当条件符合时,重复执行某一段程序,常见的有:计数...
Day12:Select Room(选择特定房间频道)
全文同步於个人 Docusaurus Blog 本章的需求,解决首页进入前,如果有特定频道可以选择...
[Day12] Face Detection - 使用OpenCV & Dlib:Dlib MMOD
好酒沉瓮底,精彩在最後;只是要付出一点点代价。 本文开始 前面提到过,使用OpenCV &...
Day-08 你对前端还是後端比较有兴趣?
这题我要直接破梗,因为这是一道陷阱题! 大家要小心也,不要真的去给他选下去啊! 很多人一看到这种二...