[Day12] Face Detection - 使用OpenCV & Dlib:Dlib MMOD
好酒沉瓮底,精彩在最後;只是要付出一点点代价。
本文开始
前面提到过,使用OpenCV & Dlib来做人脸侦测,大概可以分为四种方式:
- OpenCV Haar cascades
- OpenCV deep neural networks (DNNs)
- Dlib HOG + Linear SVM
- Dlib max-margin object detector (MMOD) <--
今天说这个
今天要介绍第四种方式。
Dlib MMOD
习惯上我喜欢称呼这个方法叫Dlib神经网路检测,
同样对应昨天提到的OpenCV神经网路检测方法,这个方法实际上也是使用已训练的模型来做预测。虽然运算花费时间最长,但准确率是这四个方法中最高的。
那会很难使用吗?
跟着一起实作你就知道了!
- 在Day9的专案下,同样在
face_detection目录下新增一个Python档案dlib_mmod.py
- 在新增的Python档案内输入以下内容 (相关程序码说明在注解内):
# 汇入必要套件 import time from bz2 import decompress from os import remove from os.path import exists from urllib.request import urlretrieve import cv2 import dlib import imutils import numpy as np from imutils.face_utils import rect_to_bb from imutils.video import WebcamVideoStream def main(): # 下载模型档案(.bz2)与解压缩 model_name = "mmod_human_face_detector.dat" if not exists(model_name): urlretrieve(f"https://github.com/davisking/dlib-models/raw/master/mmod_human_face_detector.dat.bz2", model_name + ".bz2") with open(model_name, "wb") as new_file, open(model_name + ".bz2", "rb") as file: data = decompress(file.read()) new_file.write(data) remove(model_name + ".bz2") # 初始化模型 detector = dlib.cnn_face_detection_model_v1(model_name) # 启动WebCam vs = WebcamVideoStream().start() time.sleep(2.0) start = time.time() fps = vs.stream.get(cv2.CAP_PROP_FPS) print("Frames per second using cv2.CAP_PROP_FPS : {0}".format(fps)) while True: # 取得当前的frame,变更比例为宽300,并且转成RGB图片 frame = vs.read() img = frame.copy() img = imutils.resize(img, width=300) rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 取得frame的大小(高,宽) ratio = frame.shape[1] / img.shape[1] # 侦测人脸,将辨识结果转为(x, y, w, h)的bounding box results = detector(rgb, 0) boxes = [rect_to_bb(r.rect) for r in results] # loop所有预测结果 for box in boxes: # 计算bounding box(边界框)与准确率 - 取得(左上X,左上Y,右下X,右下Y)的值 (记得转换回原始frame的大小) box = np.array(box) * ratio (x, y, w, h) = box.astype("int") # 画出边界框 cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2) # 标示FPS end = time.time() cv2.putText(frame, f"FPS: {str(int(1 / (end - start)))}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2) start = end # 显示影像 cv2.imshow("Frame", frame) # 判断是否案下"q";跳离回圈 key = cv2.waitKey(1) & 0xff if key == ord('q'): break if __name__ == '__main__': main() - 在terminal输入
python face_detection/dlib_mmod.py,跑出来的范例结果会是这样:
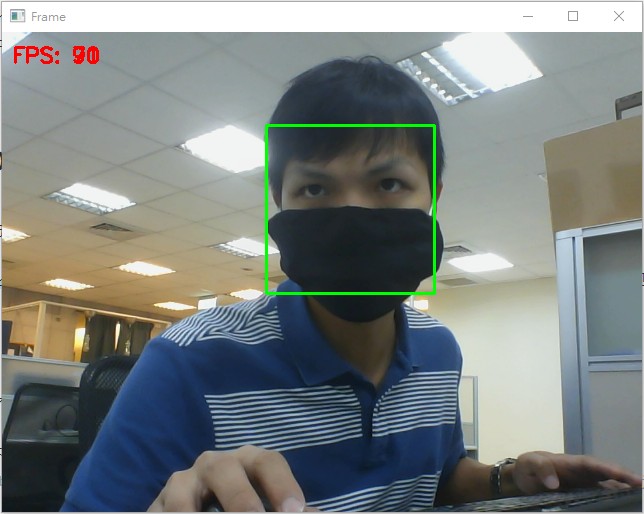
如何,程序码不难吧?
结论
-
可以看到,dlib中人脸侦测的两种方式
Dlib特徵检测与Dlib神经网路检测的做法除了在载入模型的函数不同以外,几乎一模一样。 -
如果你还记得Day3最後面提到的:
辨识准确率越高通常会需要花费更多运算时间 (指相同的硬体设备下);如果你会用显示卡(GPU)资源来做ML请直接选第四个 (Dlib max-margin object detector (MMOD))
如果你安装Dlib是按照Day9的作法透过PyCharm的Install Packages安装的,实际跑上面的范例你会发现:画面延迟非常的严重,fps几乎是0。这个原因是因为Dlib神经网路检测作法需要花费较长的时间,只有在GPU支援的情况下才有可能跑出类似我上面范例结果的情况 (预设安装的版本是不支援GPU运算的)。
那要如何做?
简单描述一下:- 在你的环境准备CUDA、C++ Compiler (cmake)、Python (with pip, wheel, and twine package installed)
- 下载Dlib Souce code
- 透过
python setup.py install编译与安装支援GPU的Dlib
详细的做法有兴趣的邦友可以参考这篇,或是有问题也可以留言,我会尽可能帮上你的忙。
-
使用Dlib神经网路检测也同样可以直侦测出戴口罩的人脸;到这里你应该要有一个直觉:使用神经网路模型做的人脸侦测,通常都不需要完整的人脸或是脸部不需要面对镜头就可以辨识
-
这里辨识结果的fps仅供参考 (我是在有GPU资源下才能跑出这样的结果,使用的是GTX 1660),但也说明了使用神经网路模型通常都会需要GPU的资源才有办法顺畅运行
参考程序码在这
关於这四个方法,明天我会再做一个总结。
保持一篇文章只有一个重点。
See you next day!
[13th-铁人赛]Day 1:Modern CSS 超详细新手攻略 - 简介
嗨大家,我是 Ronnie! 这是我第一次参加iT铁人赛,在开始前先帮我自己订一个小小目标,就是希望...
[Day 2] 什麽是 Qwiklabs?课程资源与授课方式介绍
《30天带你上完 Google Data Analytics Certificate 课程》系列将...
JavaScript 语言和你 SAY HELLO!!
第十三天 各位点进来的朋友,你们好阿 小的不才只能做这个系列的文章,但还是希望分享给点进来的朋友,知...
[Day 25] 杂记 - GL_TRIANGLE_STRIP与GL_TRIANGLE_FAN
各位读者抱歉,今天是很水的一回,因为今天加班,很晚才到家,单纯分享一个之前看到的问题。之前因为时间直...
Day30:The end is not the end
不知不觉过了三十天,在这三十天中,我们学习了 Coroutine 的每一个面向,我们知道 Corou...