AI ninja project [day 19] 音讯辨识
是这样的,我曾经在新闻上看到说罗东的农夫有种植的西瓜被偷,
我在想除了监视器以外,还有没有甚麽方法可以防止农作物被偷。
後来也有在tensorflow的开发日志上看到,
一些环保人士在雨林中放置一些旧型的手机,
在里面运行了音讯辨识的模型,只要听到了筏木机的声音,
就会进行通知,防止雨林被偷筏木。
现在可以来看看tensorflow官网的攻略,
采用已经训练好的YAMNet模型:
https://www.tensorflow.org/tutorials/audio/transfer_learning_audio?hl=zh_tw
那我们可以看一下,已经训练好的模型可以辨识那些声音:
https://github.com/tensorflow/models/blob/master/research/audioset/yamnet/yamnet_class_map.csv
安装音讯资讯处理套件:
pip install tensorflow_io
载入套件:
import os
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from IPython import display
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_io as tfio
利用tf_hub载入YAMNet模型:
yamnet_model_handle = 'https://tfhub.dev/google/yamnet/1'
yamnet_model = hub.load(yamnet_model_handle)
下载测试音讯:
testing_wav_file_name = tf.keras.utils.get_file('miaow_16k.wav','https://storage.googleapis.com/audioset/miaow_16k.wav',
cache_dir='./',
cache_subdir='test_data')
print('***********')
print(testing_wav_file_name)
print('***********')
将测试的wav档案转换成tensor格式,让模型可以辨别。
@tf.function
def load_wav_16k_mono(filename):
""" Load a WAV file, convert it to a float tensor, resample to 16 kHz single-channel audio. """
file_contents = tf.io.read_file(filename)
wav, sample_rate = tf.audio.decode_wav(
file_contents,
desired_channels=1)
wav = tf.squeeze(wav, axis=-1)
sample_rate = tf.cast(sample_rate, dtype=tf.int64)
wav = tfio.audio.resample(wav, rate_in=sample_rate, rate_out=16000)
return wav
testing_wav_data = load_wav_16k_mono(testing_wav_file_name)
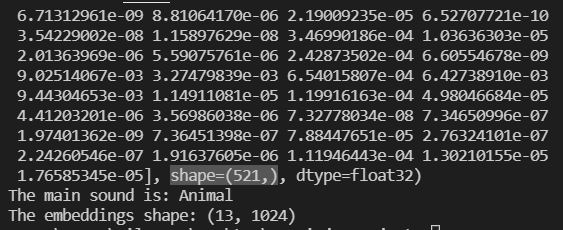
我们先将模型跑出的结果(521种特徵,一维的阵列,shape=(521,)),以list对应label的名称。
class_map_path = yamnet_model.class_map_path().numpy().decode('utf-8')
class_names =list(pd.read_csv(class_map_path)['display_name'])
for name in class_names[:20]:
print(name)
print('...')
我们可以查看,最有可能的声音类别:
scores, embeddings, spectrogram = yamnet_model(testing_wav_data)
class_scores = tf.reduce_mean(scores, axis=0)
print(class_scores)
top_class = tf.argmax(class_scores)
inferred_class = class_names[top_class]
print(f'The main sound is: {inferred_class}')
print(f'The embeddings shape: {embeddings.shape}')
那我们也可以用numpy的argpartition来看class_scores最有可能的声音类别
参考:
https://stackoverflow.com/questions/6910641/how-do-i-get-indices-of-n-maximum-values-in-a-numpy-array
我们可以使用in来查看,小偷应该是开卡车或是车子来偷农作物的吧:
alert_detect_sound = ['Car' , 'Car alarm' ,'Car passing by' ,'Truck']
if inferred_class in alert_detect_sound:
print('进行通知 有小偷')
假设你遇到下面的错误:

可以把tf_hub底下的资料夹砍了,再重新执行一次程序。
是由於tf_hub载入模型时发生错误。
Day2 用python写UI-聊聊tkinter的基本操作~
今天要介绍视窗设定,会分成三个部份来讲,建立视窗、设定视窗大小跟视窗的其他基本设定,那我们不多说就直...
Spring Framework X Kotlin Day 26 Test Driven Development
GitHub Repo https://github.com/b2etw/Spring-Kotlin...
[第30天]30天搞懂Python-spark
前言 使用pyspark函式库实作 word count程序。 程序实作 安装 pyspark函式库...
C# SqlCommand和SqlDataAdapter的区别
SqlCommand对应DateReader SqlDataAdapter对应DataSet Sq...
[DAY7]将范例上传(1)
上传LINE提供的范例回声机器人 第一步:先至LINE提供的GITHUB位置下载其资料夹,此处我们用...