DAY05随机森林演算法(续2)
昨天,我们把bagging算法算完,那今天,我打算建立分类函数:
在建立分类节点之前,得先把文字讯号转成数字,可利用特徵工程中的label encoding或one hot encoding把文字讯息转化成数字,有了数值之後就可以划分节点
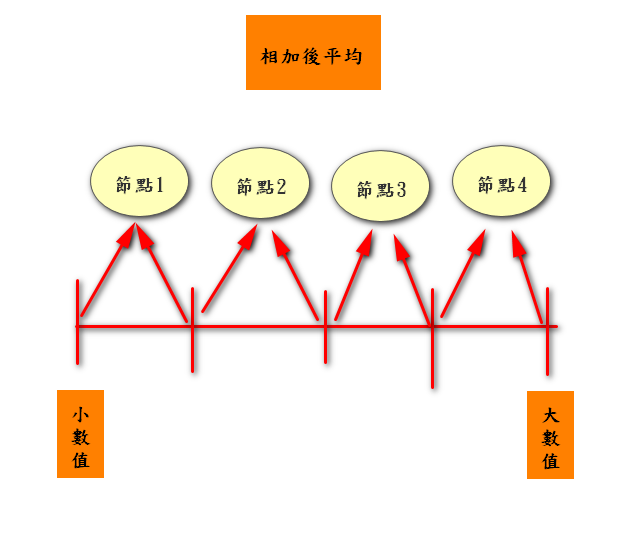
把特定特徵资料数值由小排到大後,再把前後相加的平均当成是节点
EX:资料为: [0.01,0.05,0.07,0.85,0.9]
那第一个节点就是(0.01+0.05)/2-->0.03
那第二个节点就是(0.05+0.07)/2-->0.06
…
最後一个节点就是(0.85+0.9)/2-->0.875
在依据之前说过的基尼系数就可以找出最佳的节点(而基尼系数要越小越好)
所以程序码如下:
import random as rd
import numpy as np
#一个5维资料,共5笔,data(第0维为y)
data=[[1,1.01,0.852,5,1.5],[2,2.01,0.31,8,8.1],[1,3.01,0.589,9,5.6],[1,3.01,0.01,8,2.3],[2,4.01,0.258,10,1.1]]
#划分方式
def split_Data_Set(data, index, value):
data1, data2 = [], []
for j in data:
#是否超过指定value
if j[index] <= value:
data1.append(j)
else:
data2.append(j)
return data1, data2
def Best_Feature(data):
#1为最大(效果最差)
best_Gini_cofe = 1
#位置最小为0,先设定-1
best_feature_col = -1
#因为数值有可能正或负,所以先设定None
best_split_value = None
#第i个特徵
for i in range(1,len(data[0]) - 1):
print("第",i,"个特徵")
feat_list = [k[i] for k in data]
sortfeats = sorted(list(set(feat_list)))
print("排序好特徵资料:",sortfeats)
split_list = []
for j in range(len(sortfeats) - 1):
split_list.append(np.round((sortfeats[j] + sortfeats[j + 1]) / 2,5))
print("节点:",split_list)
#每个划分点都测试
for split_value in split_list:
subdata1, subdata2 = split_Data_Set(data, i, split_value)
#使用前几天的Gini_cofe函数
new_Gini = Gini_cofe(subdata1, subdata2)
#如果基尼系数较小代表比较好
if new_Gini < best_Gini_cofe:
best_Gini_cofe = new_Gini
best_feature_col = i
best_split_value = split_value
return best_feature_col, best_split_value
best_feature_col, best_split_value=Best_Feature(data)
print("最佳分割特徵为: 第",best_feature_col,"特徵")
print("最佳分割特徵数值为:",best_split_value)
而结果如图:
第 1 个特徵
排序好特徵资料: [1.01, 2.01, 3.01, 4.01]
节点: [1.51, 2.51, 3.51]
第 2 个特徵
排序好特徵资料: [0.01, 0.258, 0.31, 0.589, 0.852]
节点: [0.134, 0.284, 0.4495, 0.7205]
第 3 个特徵
排序好特徵资料: [5, 8, 9, 10]
节点: [6.5, 8.5, 9.5]
最佳分割特徵为: 第 2 特徵
最佳分割特徵数值为: 0.4495
所以最佳分割数据方式:是用第二个特徵数值为0.4495
把data分割成两块
好,今天实作部分就到这,明天再开始做建立决策树的动作
此时男孩已走到森林前面,在入口处,有一个告示牌,上面写着:小心有人?,男孩歪着头想了一下,他以为是禁止进入意思,正在犹豫之际时,从森林深处传来了一阵歌声,那歌声美妙至极,那旋律吸引着男孩,於是男孩头也不回的,往森林里走去
--|倾听你的心跳,照着你的感觉走|-- MS.CM
>>: 【Day06】数据输入元件 - FormControl
EP09 - 建立 Django 专案和 EC2 环境 并手动部署到 EC2
前几天的打底, 把 Gitlab、Jenkins 建好, 但是仍然少了最重要的主角, 要部署的服务本...
Day 12 - Semigroup I
Definition of a Semigroup 一个集合(Set)或称型别(Type) 有 co...
[Day2] 安装python环境
夥伴们大家好,今天要说明的是如何安装python环境,python版本很多、套件很多,那这里我使用的...
Day03 - 我要写 Laravel !
前言 在混过了完全不知道要写什麽的两天之後,我就在思考我到底能在铁人赛中记录下甚麽或学习到甚麽,甚至...
Day29 :【TypeScript 学起来】React + TypeScript 实作简单 Todo App Part2
今天继续 todo app part2, 会纪录实作上遇到的问题。 若有错误,欢迎留言指教,感恩的...