【4】实验 Batch size大小对训练模型的影响
相信每个人在学习ML时,都会遇到超参数 Batch size 应该要设置多少才好的问题,一般大家在教科书上学到的大部分是:当 Batch size 很小或甚至为1时,模型损失值下降方式会以比较小步且方向杂乱的方式向下,反之当 Bach size 较大时,因为每次 gradient 都会拿一批资料作为下降方式的参考,所以步伐较大且方向较一致。

而除了模型影响以外,还有硬体限制的问题,如果今天 GPU 记忆体不够大,而且又那麽刚好你也需要训练一个大型模型,你所能设定的最大 Batch size 也无法过高。
以下我们制定了四种 Batch size ,分别是16, 32, 64, 128来观察对模型的影响,按照Day1的训练经验,这个问题应该至少能够得到85%左右的准确度。
实验一:Batch_size=16
SHUFFLE_SIZE=1000
EPOCHS = 50
BATCH_SIZE=16
LR = 0.1
ds_train = train_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 0.0032 - sparse_categorical_accuracy: 1.0000 - val_loss: 2.3630 - val_sparse_categorical_accuracy: 0.4500
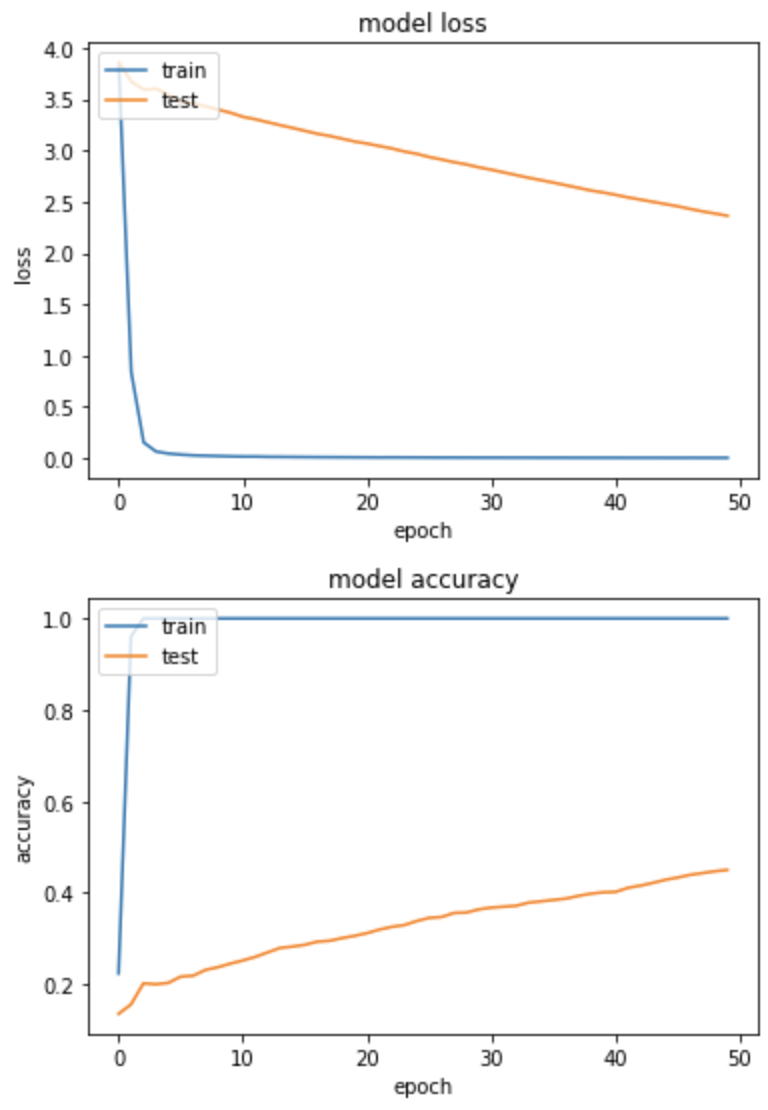
训练集loss急速下降,後期验证集没什麽起色,没有泛化。
实验二:Batch_size=32
loss: 1.9535 - sparse_categorical_accuracy: 0.8559 - val_loss: 3.7203 - val_sparse_categorical_accuracy: 0.2196
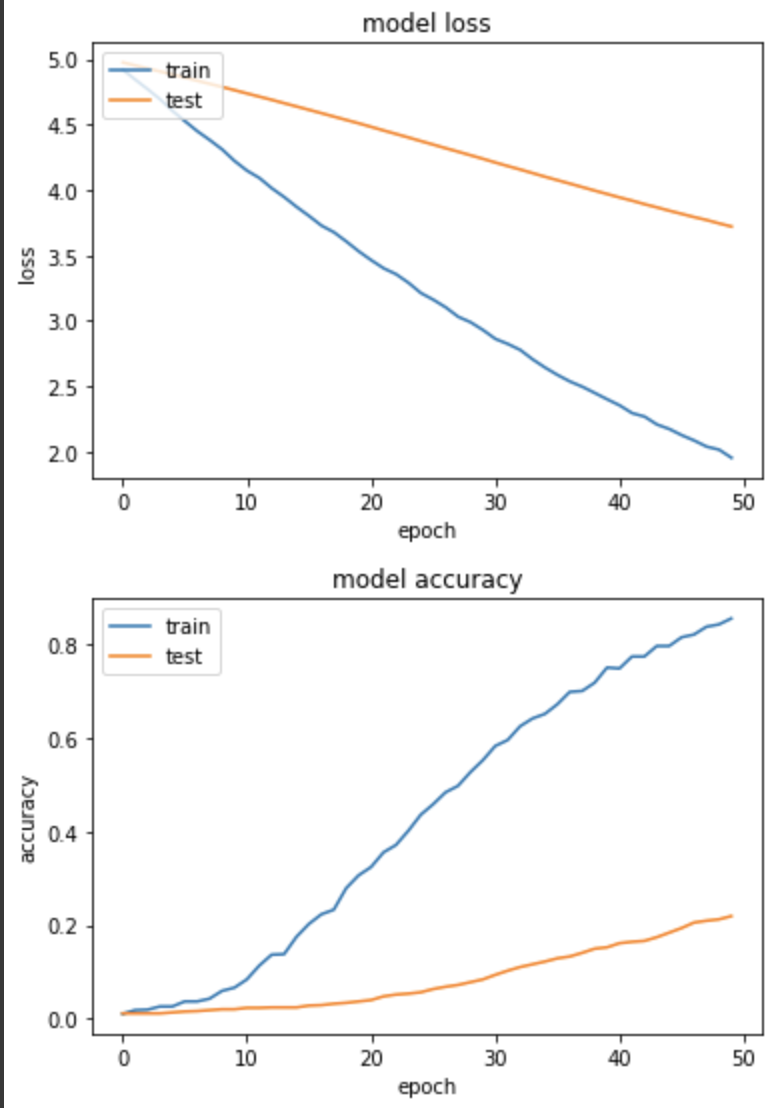
相较於实验一,训练集和验证集都有稳定下降,但看来需要更多 epoch 来运行。
实验三:Batch_size=64
loss: 8.4681e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.5873 - val_sparse_categorical_accuracy: 0.8382
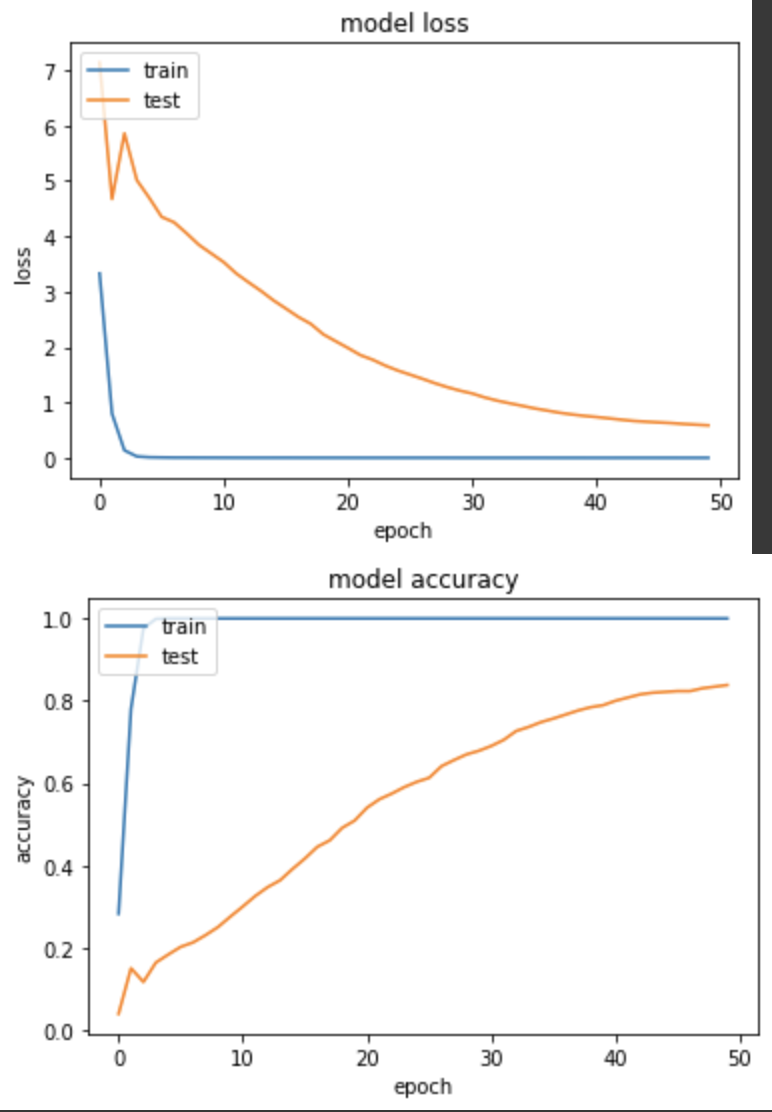
前五个 epoch 训练後,训练集准确度就几乎已达99.9%,但仍有学到特徵让後续的验证集准确度爬起来。
实验四:Batch_size=128
loss: 0.3136 - sparse_categorical_accuracy: 0.9990 - val_loss: 1.7577 - val_sparse_categorical_accuracy: 0.6902
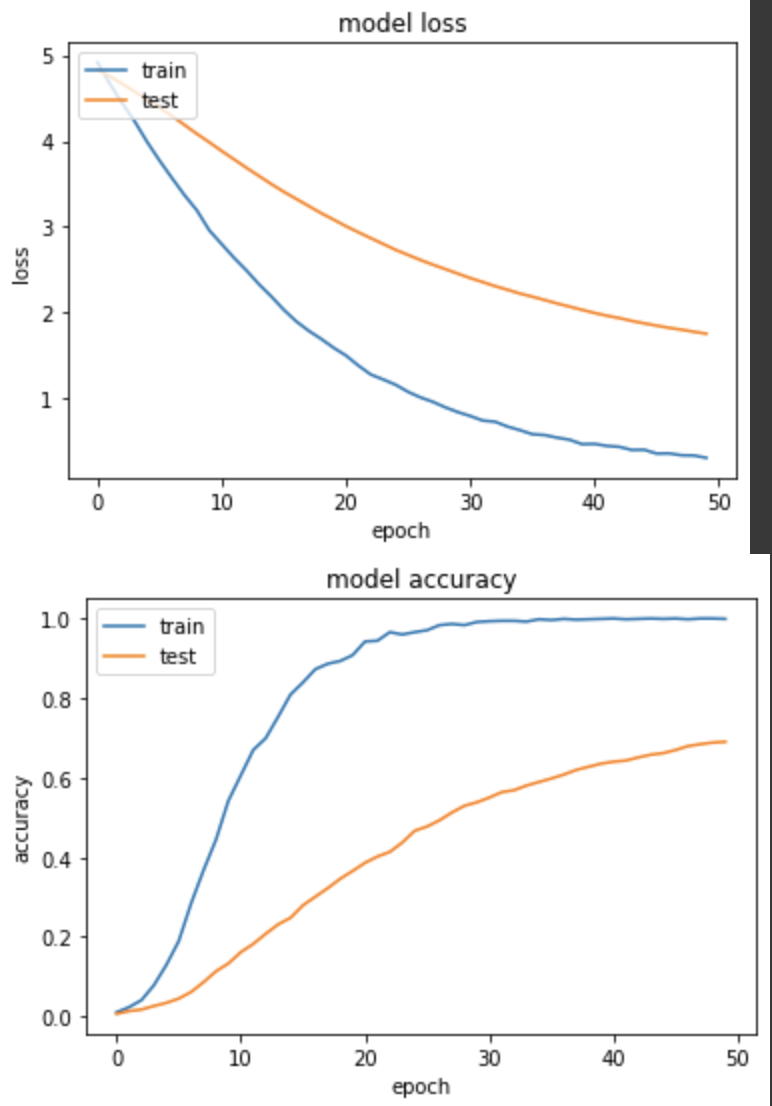
个人觉得线图最合理的实验,不像实验三的训练集暴冲,而是和验证集一起稳定进步,虽然最终的 loss 和 accuracy 没有实验三来得好,但线图很健康。
经过这四次的实验之後,我们分别拿到 loss 值是[2.36, 3.72, 0.58, 1.75], 准确度是[45%, 21.9%, 83.8%, 69%],Batch size为64时,效果最好,这部分仍无法下定论,因为其他 Batch size 若在经过更多的 epochs ,说不定也能取得不错的准确度,而我自己的实务经验来说,我基本上都是能把 Batch size 撑高就撑高,一方面训练较为有效率,另一方面较高的 Batch size 也有助於 Batch Normalization Layer 学习。
<<: Day03-资料加工与逻辑整合(methods v.s. computed)
>>: [DAY 5] _stm32f103c8t6开发板暂存器开发_控制MCU的GPIO High、Low范例
[Day15]ISO 27001 标准:内稽管审
是菜稽还是老稽,大部份可以看他们稽核的顺序来辨别, 有一阵子观察五年以上的资深前辈,会从内稽、管审开...
[Git] Intro
Version Control System (VCS) Centralized Version C...
【第二十九天 - 系统分析 题目分析】
先简单回顾一下,今天预计分析的题目: 题目连结:https://leetcode.com/prob...
DAY05随机森林演算法(续2)
昨天,我们把bagging算法算完,那今天,我打算建立分类函数: 在建立分类节点之前,得先把文字讯号...
Day08 - 试用 material color tool 哦
之前就一直觉得网页配色好难,今天试用了 material color tool,觉得之後设计网页可以...