[Day 17] 资料产品生命周期管理-辅助决策
如同前面所说,资料模型需要运用到实际环境中才会发挥价值
Initiation
延续之前模型的初始条件,如果想使用资料来辅助决策,最重要的就是要厘清想解决的问题是什麽。
常见的问题像是:
「明天会不会下雨?」
「使用者会不会点击?」
「使用者是不是本人?」
面对这些问题,其实在技术上都有不只一种方式来回答。这时候就是要根据目前持有的前三层的资料品来决定可行的解决方案。
Design
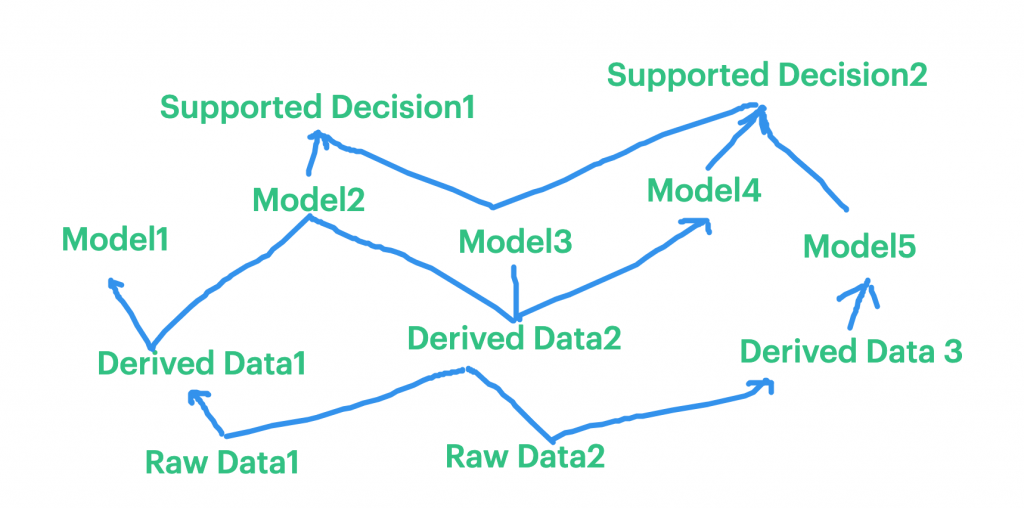
设计上来说需要依序盘点是不是有足够的资料来支撑解决方案。在这个过程会把前几个资料产品的设计流程从头顺过一次,确保资料在每个阶段都有可能搭得起来。
- 原始资料:手上有哪些原始资料跟这问题有关?如果是想知道会不会下雨,就看看有没有过去的降雨、湿度、温度、气压等资料。如果是要及时的预测,那有没有办法即时的拿到最新的资料
- 加工资料:处理资料的方式有没有办法应付决策需求?如果是要及时的预测,那有没有办法即时的处理这些原始资料;以及思考资料可以怎样被加工利用。
- 资料模型:要用哪种模型、演算法才能解释资料甚至做到预测?做好之後要如何做到模型可以持续的维持效果?
将以上事情搞定之後,需要思考如何用合适的方式将结果呈现给需求端来「辅助决策」。
以下雨的例子来说的话:
- 如果是 BI 报表,除了呈现过去的资料之外,也可以加入几个门槛值(threshold)来提醒使用者,像是当湿度超过 80 的时候图表会呈现红色、或是寄送 email。
- 如果做的是机率模型,也可以透过门槛值(例如机率超过 70%)的时候发送 email。
- 如果是要做报告,那可以根据门槛值切换不同的标题,让使用者可以掌握现在的状况以便做出决策。
Implement
实作时基本上就是把设计阶段时盘点的资料产品依序实作。各自资料产品实作要点可以参考前面几篇。
针对辅助决策在实作上不外乎就是:
- BI Dashboard
- APIs
让使用者可以用简单的方式取用最後结果。
Deployment
部署阶段一样除了考量前几层的资料产品外呢,需要特别注意整个辅助决策产品的 SLA(Service Level Aggrement)。单一产品要做到 99.9% 的 uptime 都不是简单的事,何况资料产品层层叠叠,从原始资料一路叠到 Model 和 API,每个单一产品都需要有极高的稳定程度,才有办法让最终的辅助决策系统达到 99.9% 的稳定度。
Evaluation
评估阶段基本上就在处理两个层面问题:
-
信度(Validaty):结果的准确率是否足够?
不同的问题可以被接受的准确率(或错误率)是不同的。像是 Iphone 人脸辨识解锁你绝对不希望有任何错误可能;但是像台风路径预测,就可以接受相对较大的误差。 -
效度(reliability):结果是否稳定、能够重复实现?就像之前谈到的,模型不能只有上线那天好,而是希望能够稳定发挥效果;系统面的稳定也是一样,我们会希望每天资料都可以顺利处理、不会因为突然的过量使用者造成系统停机或当掉。
Iteration
越上层的资料产品迭代起来也就越麻烦,下层产品的任何迭代都会影响到上层产品。可以很简单的想像这个情境:当原始资料更新格式,却没有被妥当处理时,就会连带影响後续的加工资料、模型、以及辅助决策。更麻烦的事情,每个下层资料产品都可能会被多个上层资料产品使用,当有需求会改动到下层资料产品时,都需要特别小心意想不到的 side effect。
References
https://www.atlassian.com/incident-management/kpis/sla-vs-slo-vs-sli
http://www2.nkust.edu.tw/~tsungo/Publish/15%20Validity%20and%20reliability.pdf
>>: Day 12: 前往未知秘境!在iOS上展示Ktor资料!
Day17|【Git】存在 .git 目录里的东西 - Blob 物件与 Tree 物件(上)
Git 有四种 type (类型) 的物件:blob、tree、commit 和 tag。 本篇主要...
IT 铁人赛 k8s 入门30天 -- day29 Adding entries to Pod /etc/hosts with HostAliases
参考文件 https://kubernetes.io/docs/tasks/network/cust...
day25_如何采购 ARM 版本的 Windows 电脑呢
ARM 版本的 Windows 该怎麽买呢? 主要的产品为 Surface Pro X ,这是一款微...
使用 Python 实作网路爬虫 part 2
Beautiful Soup 当我们成功获取网页後,该如何「分析这个网页」才是更重要的一点。 HTM...
不要被电影被骗了,工程师的日常很平淡
You're not an a**hole, Mark. You're just trying s...