Day7:K-means分析
K-means的中文有人称作集群分析,但是主要都还是讲英文,比较容易懂。
这分析方法跟KNN很像,但是不同在於KNN是监督式学习,K-means是非监督式学习。监督与非监督的差别,前者是已经给了一些基本架构,从这基本架构中去学习,後者则没有,要自己找出资料中的规则,再来判断未知的数据。举例来说,如果今天操场上聚集很多人,监督式学习则会先把男女区分开来,教你什麽是男性、女性,这时候如果有人突然加入群组,则可以透过基本规则去定义他是男是女。然而非监督式学习则都不会说,要你自己去判断,将男女分开来,但是能透过其他人一次次的加入,使得群组有更好的归类,但有缺点就是可能会在一开始的分类的就出错,比如长得很像男生的女生,可能会不小心归类为男性,而导致会有些规则上的问题。
K-meas采非监督式学习,给予机器资料之後,另外在定义有几个族群,这样就可以了。采取方式是,会先定义每个资料,根据有几个族群暂定几个中心点,计算每个点到中心点的距离再进行归类,接着调整中心点,再计算各点距离如何,直到中心点位置不变,则训练完毕。
举例来说,若以得知以下的资料:
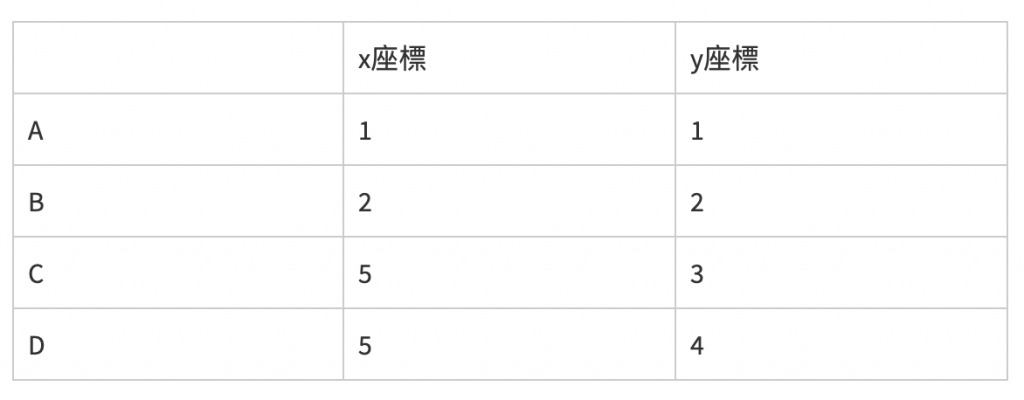
假设有两个族群,令这两个族群的中心点个别在c1(1,1)以及c2(1,2),经过计算中心点和各别点的距离後,结果如下:
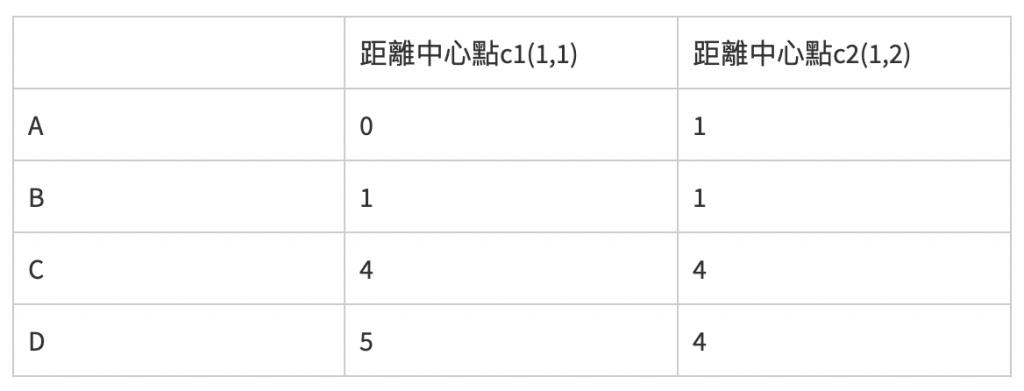
根据计算结果,归类在距离较小的那一类,若相同则随便,因此先将A归类为c1,BCD归类为c2。另外c1座标维持不变,c2座标更正为(4,3),接着再计算这点的距离:
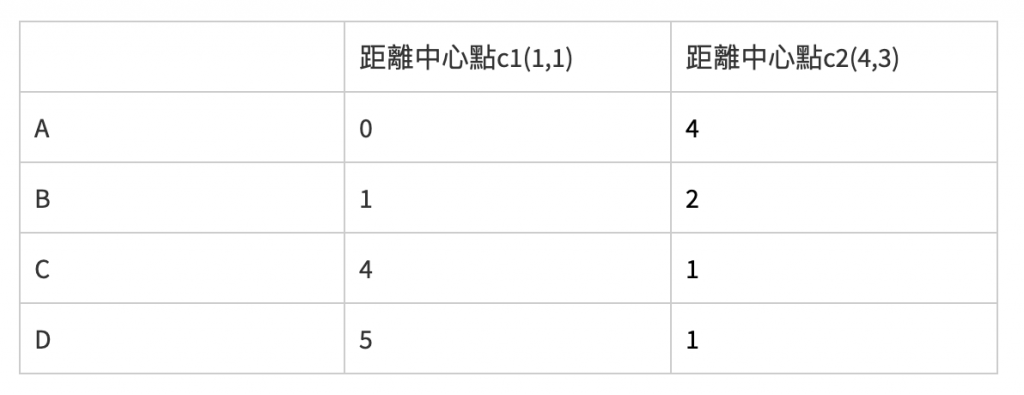
根据计算结果,B要归类在c1,其余不变。因此c1座标改为(1.5,1.5),c2座标改为(5,3.5),再次计算:
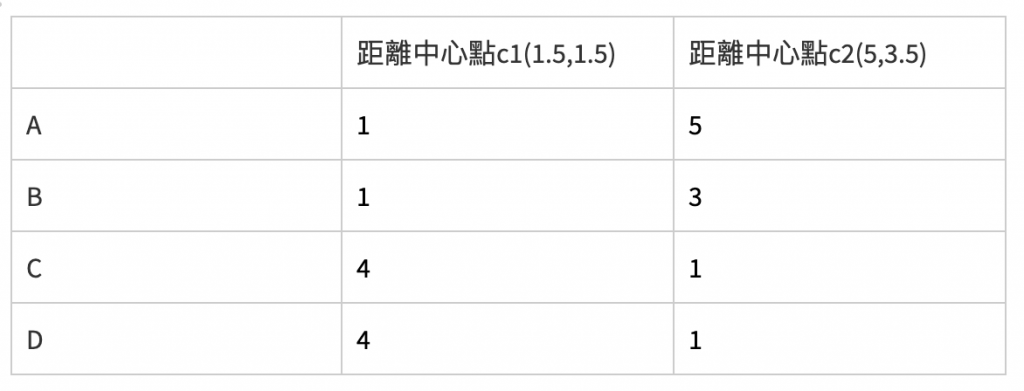
会发现结果不变,因此AB为一群,CD为一群。
>>: JavaScript 语法解析器&执行环境&词汇环境 笔记
Day26 - 【概念篇】Keycloak使用基本概念 - 第二部分: User & Group
本系列文之後也会置於个人网站 帐号(User) 基本讯息 接着来看看与帐号有关的设定。 在之前,已...
在 Fedora 34 上安装官方呒虾米的 iBus 表格档 (影片录制步骤)
Fedora 34 内建 iBus 平台,直接安装行易有限公司释出的呒虾米表格档,使用完整度最高。 ...
Day 13: Structural patterns - Composite
目的 将程序的组成转换成有上下阶级的结构(或称:树状结构),方便使用者不论从哪个节点、叶子使用,都可...
[Day 15] 小整理
整理一下目前做的东西: 目前关於敌人行动还没有实作 但在开始敌人动作之前,想补齐以下议题 技能动画 ...
[ Day 19 ] 表单中的 Controlled Component
在网站开发时有时候会使用到表单的元件,而表单内大多是采用 input 的栏位来搜集使用者的资料的。...