DAY17 机器学习专案实作-员工离职预测(中)
ㄧ、资料前处理
1. 补值、删值
前面我们透过视觉化的方式找到资料有缺值,因此我们要将资料进行补值。要记得训练资料怎麽补,测试资料也要使用同样的方法。
补值:在这边我选择补-1。一方面是不想和其他资料搞混,补一个大家都没有的数字。举例来说有个特徵是工作经验,你补0就可能与工作经验0年的搞混。当然补值这种是每个人都有不同想法,所以可以自己去试看看别种方法。
删值:前面我们有看到有些特徵已经缺值缺了一半以上,那这边我考虑将他直接删除,但也可以试试看留下他的特徵将他补值,也许会有不同的效果。
X=df_train.drop(["最高学历","毕业学校类别","PerStatus"],axis=1)
y=df_train["PerStatus"]
X=X.fillna(-1)
df_test=df_test.fillna(-1)

-
用Smote
from imblearn.over_sampling import SMOTE oversample = SMOTE() X, y = oversample.fit_resample(X_train, y_train)
二、特徵工程
1.将资料做编码
我们分别对厂区代码以及归属部门进行onehot encoding处理
-
归属部门(因为归属部门众多,只截出部分结果来示范)
temp_department=pd.get_dummies(df_X["归属部门"],prefix="归属部门") #%% df_X=df_X.drop("归属部门",1) #%% df_X=pd.concat([df_X,temp_department],axis=1)

- 厂区代码(因为厂区代码众多,只截出部分结果来示范)
temp_department=pd.get_dummies(df_X["厂区代码"],prefix="厂区代码") #%% df_X=df_X.drop("厂区代码",1) #%% df_X=pd.concat([df_X,temp_department],axis=1)

2. 筛选特徵
- 用卡分分配筛选特徵
我将**?**设为0.01,然後去观察各个特徵对离职有没有显着的影响,然後算出各个特徵值之间的p值,最後有18个特徵符合个特徵符合显着水准内的0.01from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 best_features = SelectKBest(score_func=chi2, k=10) fit = best_features.fit(X, y) #%% df_scores = pd.DataFrame(fit.scores_) df_columns = pd.DataFrame(X.columns) #合并 df_feature_scores = pd.concat([df_columns, df_scores], axis=1) #定义列名 df_feature_scores.columns = ['Feature', 'Score'] #按照score排序 df_feature_scores=df_feature_scores.sort_values(by='Score', ascending=False) #验证k要用几个P_value>0.01 chi_values,pvalues_chi = chi2(X,y) K_value = chi_values.shape[0] - (pvalues_chi < 0.01).sum()
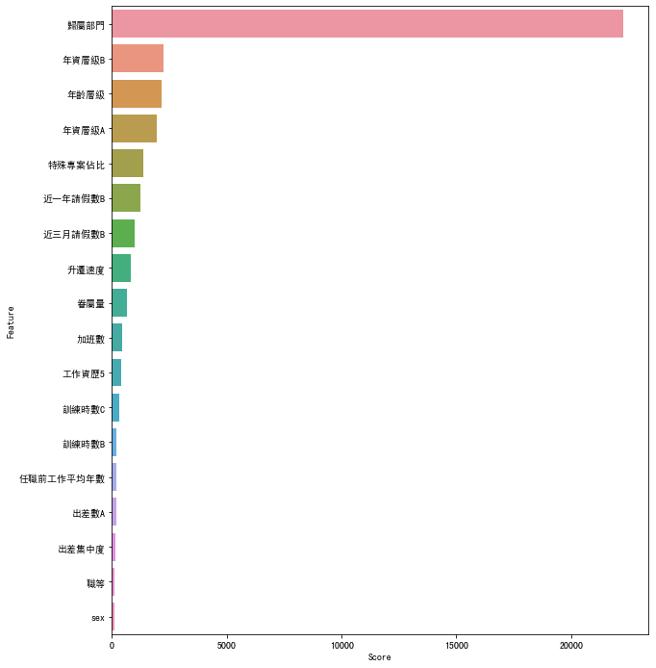
有21个特徵平均分数高於平均
#%%
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
rfc=RandomForestClassifier(n_estimators=100,n_jobs = -1,random_state =50, min_samples_leaf = 10)
rfc.fit(X_train, y_train)
df_scores = pd.DataFrame(rfc.feature_importances_)
df_columns = pd.DataFra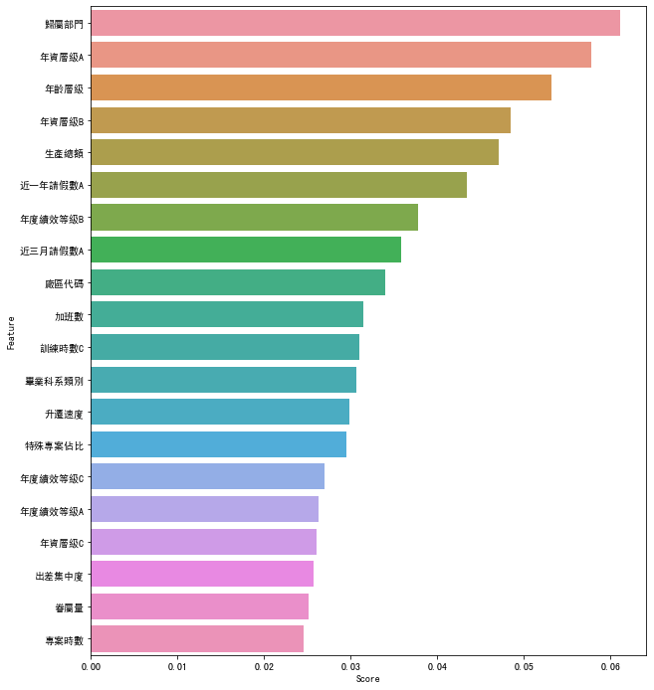me(X.columns)
#合并
df_feature_scores = pd.concat([df_columns, df_scores], axis=1)
#定义列名
df_feature_scores.columns = ['Feature', 'Score']
#按照score排序
df_feature_scores=df_feature_scores.sort_values(by='Score', ascending=False)
#找出有几个特徵高於平均
num=0
for i in range(0,49):
if df_scores.iloc[i,0] >= a:
num=num+1
else:
num=num
#画图
fig = plt.figure(figsize=(10,12))
#plt.tick_params(axis='x', labelsize=8)
sns.barplot(df_feature_scores['Score'].head(21),df_feature_scores['Feature'].head(21))
3. 使用PCA进行降维
当然我也有将资料转成2维去试看看,但可以看到PCA无法有效地将离职与非离职之间分开,因此在这笔资料集中这不是一个好的方法。不过就如我们前面所提到的,初期你在做资料分析你一定会试很多方法,到最後你累积经积越多经验,你就可以看资料来去判断该用什麽方法。
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
X_std = StandardScaler().fit_transform(x)
X_train_std = StandardScaler().fit_transform(X_train)
X_test_std = StandardScaler().fit_transform(X_test)
pca = PCA(0.85)
pca.fit(X_std)
X_train_pca = pca.transform(X_train_std)
X_test_pca = pca.transform(X_test_std)
#%%画图
principalDf = pd.DataFrame(data = X_train_pca
, columns = ['principal component 1', 'principal component 2'])
finalDf = pd.concat([principalDf, up_sample_y], axis = 1)
#%%
cmap = plt.get_cmap('Set3')
#%%
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
ax.set_title('2 component PCA', fontsize = 20)
targets = [0,1]
colors = cmap(np.linspace(0, 1, len(targets)))
for target, color in zip(targets,colors):
indicesToKeep = finalDf['PerStatus'] == target
ax.scatter(finalDf.loc[indicesToKeep, 'principal component 1']
, finalDf.loc[indicesToKeep, 'principal component 2']
, c = color
, s = 50)
ax.legend(targets)
ax.grid()
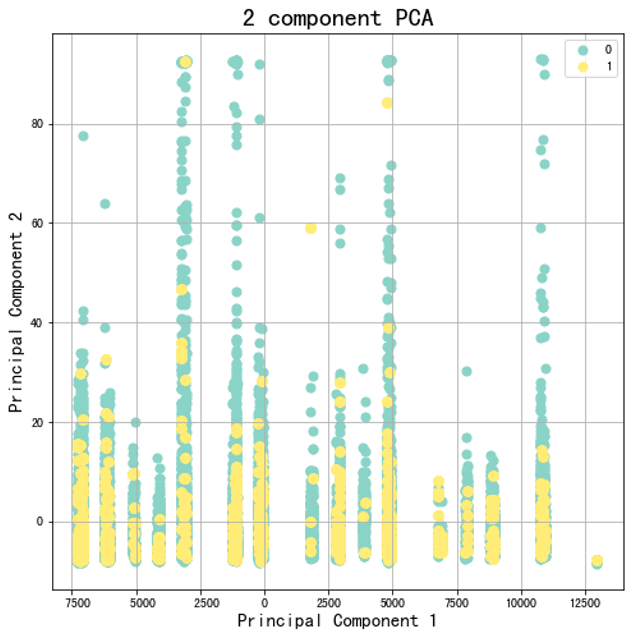
三、结论
有没有发现当要把资料丢进模型做训练前,需要花费大量的时间在整理资料,这也是为什麽我们会在前面花这麽多时间介绍这麽多的处理方法,後面我们将丢入模型去做评估结果罗~
<<: 第17天 - 来试着做一个简易购物系统(1)、补充昨天的登入程序码
>>: IT 铁人赛 k8s 入门30天 -- day3 k8s 架构:k8s Node Compoents
【DAY 4】 Power Automate 简介 + 订便当系统
哈罗大家好~ 今天要简单说明 “ Power Automate “ 这个强大的流程引擎以及示范一个用...
突破封锁线的勇气与思维
一直以来,与欧美敌对的国家,绝对没有好下场,最严重的就是经济的制裁,这样的做法,目的是要让敌对国的内...
Day29 实作todoList(四)产生事项列表
确定资料的建立後,接下来要在List元件中使用回圈渲染的事件的方式将每个新增的样式呈现在列表之中。 ...
Day16 - 铁人付外挂前置作业 (ㄧ) - 串接文件
不管是哪一家软件公司或是金物流厂商,只要他们有提供 API 介面来服务外部网站,通常一定会有串接文件...
【没钱买ps,PyQt自己写】Day 16 - 在 PyQt5 中取得图片座标 (滑鼠位置) mousePressEvent,观察图片在 Qt 中产生的方式,对原图进行座标换算处理
看完这篇文章你会得到的成果图 前言 这一篇我们会继续拿现有的 day 15 成品来改, 接下来我们要...