[Day 02] 在表情资料寻找邂逅是否搞错了甚麽 (Facial Expression Recognition)
表情资料集的介绍与下载
俗话说:「知己知彼,百战百胜」,这句话同样也适合用在资料科学上,
我们必须对资料的背景非常熟悉,才能够设计出适合的演算法。
今天,让我介绍这系列文用到的人脸表情资料集:Facial Expression Recognition 2013 (FER2013)。
来源
FER2013资料集来自一个西元2013年,
国际机器学习大会(International Conference on Machine Learning, ICML)举办的竞赛,
如今,ICML已成为国际顶级学术会议,ICML和NeurIPS以及ICLR三分天下,
掌握机器学习的前瞻技术。
准备资料须知
-
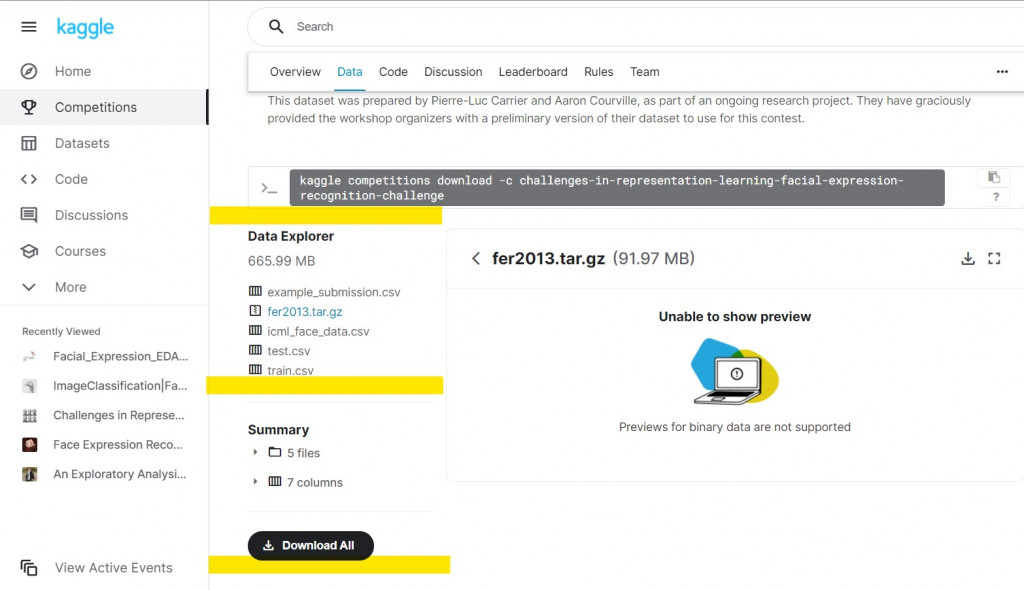
请大家先去Kaggle下载资料:(载点)
-
我们只需要下载fer2013.tar.gz就好。
-
将fer2013.tar.gz解压缩後,留下fer2013.csv就好。
-
资料中每张照片已经存成48x48的pixel,展开後储存在fer2013.csv中。
-
表情共有7类:0=Angry、1=Disgust、2=Fear、3=Happy、4=Sad、5=Surprise、6=Neutral。
-
图片范例来源

难易度
我相信在座各位都玩过MNIST或是CIFAR资料集,accuracy随随便便冲上0.9不是问题。
你们一定心想:不过就是一个影像分类的问题,随便叠出一个CNN模型不就解决了吗?
我将用下面一张表来说明(未来有机会再介绍各个模型架构:
| 模型 | 首发年分 | ImageNet test top-5 error |
|---|---|---|
| AlexNet | 2012 | 15.32% |
| VGG | 2014 | 6.8% |
| GoogleNet | 2014 | 6.67% |
| ResNet | 2015 | 3.57% |
| ResNeXt | 2016 | 3.03% |
| SENet | 2017 | 2.25% |
| MobileNet-224 | 2017 | 10.5% |
| EfficientNet-B7 | 2019 | 2.9% |
顺带一提,在2015年的ImageNet影像辨识大赛上,ResNet的top-5错误率仅有3.57%,优於人类的5%。
有人说这是机器打败人类的证明,
但我觉得这只能说明机器在1000个特定类别中打败了人类,
世界上还有数不清的类别是机器没办法辨识的。
不过,从此开始我们终於可以放心让机器在特定领域中帮助人类做影像辨识了。
回到正题,这个FER2013比赛时间点是2013年4月12日,
当时的模型发展到AlexNet,这是只有8层深度的网路。
并且笔记型电脑的GPU大概只有到GeForce GT 630M等级的。
更不用说Tensorflow在2015年才发布0.1版本。
在当时,这个FER2013的任务可一点都不简单!
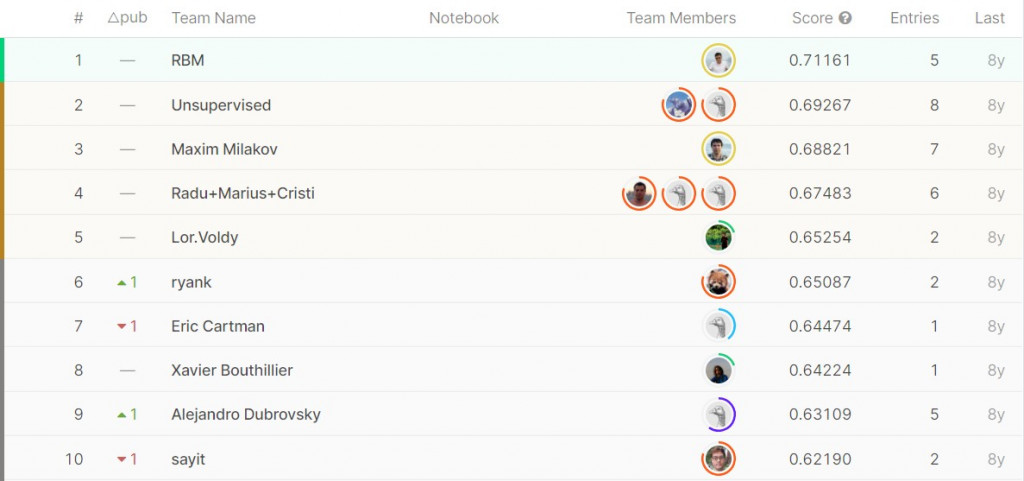
冠军的准确率也只有到71.16% (说不定我接下来做的更差)
下图为当年private test的准确率排行榜
结语
介绍完FER2013後,对於自己能做出来的信心大大的降低了。
希望我能打败当年的冠军XD
Day12 同步状态控制 Synchronizer
由於我们可藉由产生带重叠范围的配对请求,而这些配对请求将并发(Concurrently)的触发 MM...
老肝哥-菜鸟Java的LeetCode历程,第十三题:Roman to Integer,朝远大目标前进!
嘿嘿!各位好你最好的朋友老肝哥照惯例又来了 今天老肝哥心情其实不错 因为自己又坚持一天了,但老肝哥在...
JS Library 学习笔记:Three.js 初见面,在2D画面创造三维世界 (一)
引入Z轴创造体积、呈现空间感外,光影也是 3D 重要元素,光的强弱、位置、角度、色彩等,会与物体的「...
Java学习之路03---标识符、关键字、变数概念
架构图 前言 Java程序是一系列对象的集合,而对象之间透过彼此之间调用方法来达到开发目的,因此在认...
Angular 深入浅出三十天:表单与测试 Day05 - 如何写出优秀的测试?
昨天介绍了开始撰写测试之前必须要知道的二三事之後,想必大家已经对如何开始撰写测试有了一些概念,但测...