浅谈分支预测与 Hazards 议题
本篇章介绍经常发生在 Pinpline 上的潜在伤害 (Hazards) 以及针对各种 Case 所设立的解决机制。
Hazards
-
Structural Hazards
在同一个 Clock Cycle 中,若 Pipeline 有两个以上的指令需要使用同一个资源,便会产生 Structural Hazards 的问题。如此一来,後面的指令便会需要延後放入流水线,造成处理器无法在理想状况下运行(一个 Cycle 处理一条指令)。
该情况又称为流水线泡沫化。
为避免该状况发生,在处理器设计阶段时必须考虑设置两个以上的 Data Unit 去处理指令以及资料的记忆体操作。或是将 Instruction 和 Data 的快取区隔开来。
-
Data Hazards
假设有两个算数指令,分别是
ADD和SUB,并且SUB的输入资料是ADD的输出资料。若SUB在执行时,ADD处理的结果还没有被写回记忆体,便会造成 Data Hazards 。细节可以参考 NCTU OCW 的 9:10 处。
若不希望两个指令中间有太多的闲置周期,可以利用 Forwarding 的技术解决,请见下图。
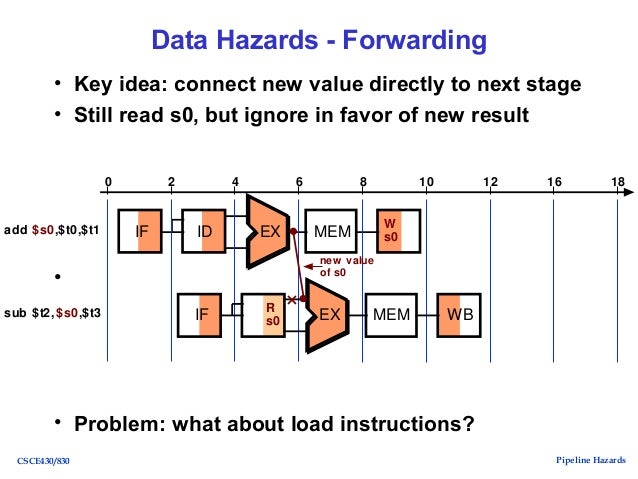
其主要概念是: 不等到第一个指令将结果写回,直接在第一个指令完成 Execution 时将结果传送给第二个指令的 Execution Input 。
图片取自 slideshare 。
Fowarding 确实能够解决上述的 Case ,不过仍然会遇到流水线泡沫化的情况产生,像是:
- Load-Use Data Hazards
若第一个指令为 Load 类型,则须要等到 Memory Access 阶段才能将结果 Forward 给後一个指令的 Execution 。
细节可以参考 NCTU OCW 的22:16 处。
因此,我们日常开发所使用的编译器都会对程序语言做 Code Re-Ordering 减少流水线泡沫化的状况产生,简单的举例如下:
若在 C 程序码中有两项加法操作:int a = b + e; int c = b + f;若我们真的按照程序码的逻辑工作,计算机会这样处理我们的程序:
- 读取 b 变数所存放的值并放到 register 1。
- 读取 e 变数所存放的值并放到 register 2。
- 将两项 register 存放的值相加并放入 register 3。
- 将 register 3 的值写回记忆体。
- 读取 f 变数所存放的值并放到 register 4。
- 将两项 register 存放的值相加并放入 register 5。
- 将 register 5 的值写回记忆体。
若这样做,即使有 Forwarding 还是会在
2.和3.之间以及5.和6.之间产生泡沫化的状况。一共需要 13 个 Clock Cycle 才能完成。详细计算方式如下:
第一个指令需要等待完整的流水线周期: 5
之後每个指令需要等待一个周期: 6
一共产生了两次泡沫化: 2而聪明的编译器会将我们的程序码做编排优化:
- 读取 b 变数所存放的值并放到 register 1。
- 读取 e 变数所存放的值并放到 register 2。
- 读取 f 变数所存放的值并放到 register 4。
- 将两项 register(1,2) 存放的值相加并放入 register 3。
- 将 register 3 的值写回记忆体。
- 将两项 register(1,4) 存放的值相加并放入 register 5。
- 将 register 5 的值写回记忆体。
在搭配 Forwarding 的前提下,我们就可以避免泡沫化的问题发生,加速程序码的运作。
- Load-Use Data Hazards
-
Control Hazards
Control hazards 发生在处理器被要求作条件分支时,做条件分支分析需等到条件需求被运算出来,才知道要执行的下一条指令位置,而在 pipeline 的处理过程中可以先利用 Branch prediction 猜测下一条指令。如果判断错误会造成的暂存器资料改变,需要还原回来以及对 pipeline 做清空的操作,十分浪费效能。
Branch prediction
Branch prediction 主要有两类:
- Static Branch prediction
静态的分支预测不会根据条件来调整策略,最常见的有:- loop 一律猜测会往前跳 (backward branch is taken) 。
由於while,for等loop通常都会重复执行一次以上。假设它一定会向後跳转,只要在回圈执行超过两次的状态下就能出现成效。 - if-else 一律猜测不会进行跳转 (forward branch is not taken) 。
不论是一个条件分支或是多个条件分支,一定只有一个分支会如期运行,其他不符合条件都会向前进行转跳。为避免大家搞混前後的定义,特别补充一下。
向前跳转的定义: 跳转後指令的位置大於目前指令。
向後跳转的定义: 跳转後指令的位置小於目前指令,也就是往回跳。
- loop 一律猜测会往前跳 (backward branch is taken) 。
- Dynamic Branch prediction
动态的分支预测会根据不同的使用情况做出调整。假设程序码当中用了 100 次BEQ条件转跳指令,动态分支预测会为 100 个BEQ指令个别建立历史纪录。这麽做的原因是: 不同的BEQ的比较条件不尽相同,若这 100 个指令都参照同一个历史纪录,会造成大量的错误预测,导致处理器需要反覆的清空流水线。
二位元饱和计数器
由於现今的处理器多采用动态分支预测提高处理器的工作效率,本节就特别以饱和计数器为例,向大家介绍最简单的动态预测策略。

图片来源: Link 。
计数器一共有 4 个状态机,其状态分别是:
| MSB | LSB |
|---|---|
| 0 | 0 |
| 0 | 1 |
| 1 | 0 |
| 1 | 1 |
若 MSB == 0 不转跳,
反之,若 MSB == 1 则转跳。
这样子做的好处是: 不会因为犯错一次就改变想法,假设原本预测不转跳,那必须要连续猜错两次才会改变想法。
如果设计者希望计数器猜错更多次才改变想法,我们可以将计数器从二位元增加至三位元,甚至是更多位元。不过,一昧的增加位元不一定能带来更好的性能。
Reference
DAY30-参赛心得
这个暑假就像开头第一篇说的,应该是大部分人度过最长的一个暑假,我原本也没什麽目标,打算好好休养生息,...
kbars API测试
今天要测试永丰提供的kbars API, (1)老规矩先进行汇入使用的库以及登入的动作, 今天使用的...
33岁转职者的前端笔记-DAY 30 终点也是起点
终於来到第30天了!!! 没想到自已可以连续发文30天 要一边上班一边写文章真的不容易呢 尤其是刚到...
Day.25 提升大数据资料管理 - 资料表分区 ( MYSQL Partition)_2
今天延续昨天的内容,继续介绍表分区类型~明天呢我们就将资料表分区的流程实际用到实务上使用,达到每天...
认识HTML(三)
常见的HTML elements 标题headings 若想在文字中设定像章节名称之类的标题,可以使...