想要爬个资料也困难重重
这边先说一下,关於上一篇的程序码好像有些问题,我这次找了其他资料练习,先用了另一组程序抓取,确认抓取成功後,我再用跟上次相同的程序码更正细节後再次抓取,结果却是空值,所以应该可以判断是我程序码的问题。下面就讲讲我这次的爬虫吧!
一开始我是用别的网站爬的,结果再superagent()那就抓取失败了,我也不是很确定是这网站本就不给爬还是怎样。所以就又另寻其他网站来完成这次的爬虫。
下面是这次的程序码。这边说明一下,我架设服务器主要是想要把结果看得清楚一点这样。
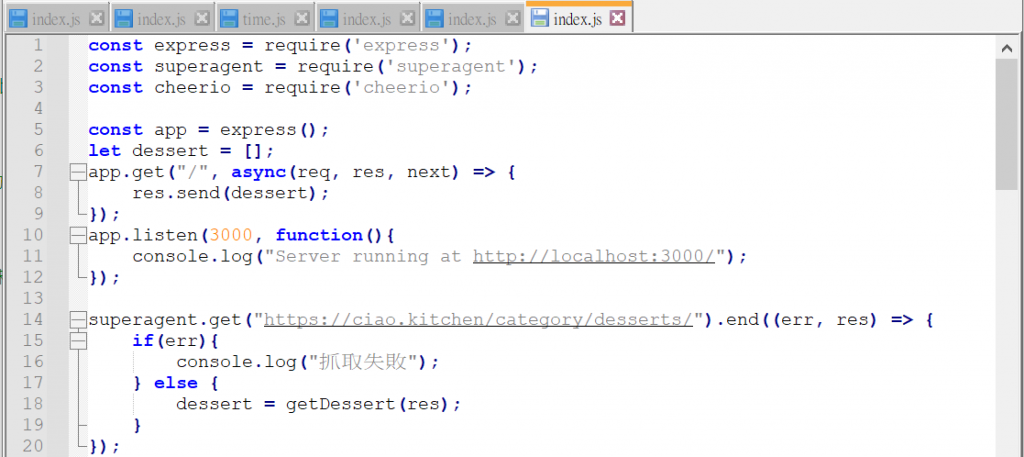


我之所以一直练习这样的爬虫,主要是我还不熟悉,就想要多练练看网站控制台html的…算分析吗?就是能不能够透过程序码来获取到想要的资讯,而不再是单纯的复制贴上。
每个人都该学的30个Python技巧|技巧 2:Python语法基本功 — 数字与字串(字幕、衬乐、练习)
昨天认识了两种编辑器,你挑好你喜欢的环境了吗,第二天就要开始进入写程序的环节罗,有没有很期待୧⍢⃝୨...
成员 3 人:别让人落单,就成功一半
「三是一个质数,是一个特别的存在。」 「三角形是最坚固的形状,最强韧的组合。」 三个人的团队,是最适...
Day 29 Rails soft delete - paranoia
记得当初上课时第一次听到软删除这个词蛮震惊的,没想到网路世界是这麽可怕的阿。 阿修说文解字 soft...
[Python]Natural Language Toolkit
http://www.nltk.org/ NLTK 是一个主流用於自然语言处理的 Python 库 ...
[DAY19]旋转木马(02)
Column object for carousel thumbnailImageUrl Strin...