[Day14] 文本/词表示方式(五)-word2vec
一. 前言
这篇是word2vec的paper,网址:https://arxiv.org/pdf/1301.3781.pdf
其实文字转向量这件事在很久之前就有许多人在研究,但过去研究的花费时间过高、架构也很复杂,paper中也有提到NNLM(Feedforward Neural Net Language Model)这种方法,於是呢,作者就决定提出一个架构简单,但又可以表示词的方法,word2vec就这样诞生了,他也分成2种方法: CBOW(Continuous Bag-of-Words)与skip-gram。
二. CBOW(Continuous Bag-of-Words)
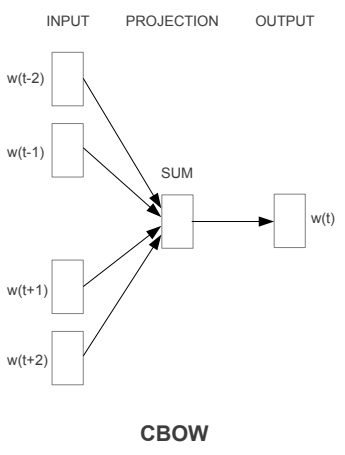
下图就是CBOW的模型,图来自原paper,是一个类神经网路的模型,只是只有一层hidden layer,其方法就是利用上下文来预测中间的词出现的机率是多少,以下图来说的话可以当成现在有五个词,利用前两个词(w(t-1)跟w(t-2))与後两个词(w(t+1)跟w(t+2))来预测中间词(w(t))出现的机率,输入及输出层都是以one-hot representation来表示的,藉由不断的训练(SGD以及Backpropagation来调整权重)input到projection的权重,最後这些权重就变成了词向量。
三. skip-gram
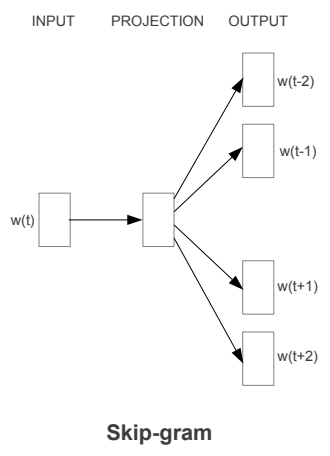
第二个word2vec的模型是skip-gram,架构图如下图,其训练方式与CBOW相同,输入及输出层也都是one-hot representation的形式,但整体概念是用中间词来训练上下文出现词的机率,跟CBOW刚好相反。以刚刚的句子“我 今天 很 帅”,就是我用 “今天” 来预测 “我” 及 “很”这2个词出现的机率,在最大化机率的过程中也训练了从input层到到projection层的权重。
四. 优缺点
通常来说,cbow的方式需预测的词较少,花费的时间较短,训练时的词向量较为平均; 而skip-gram预测的词较多,但花费的时间长,遇到僻词出现次数较少时,多次的训练会使词向量相对的更加准确。
明天会以gensim来实作word2vec
>>: Angular Reactive Form 响应式表单 (formControl)
Day 14:Disqus 留言管理指南
昨天我们在 Hexo 装设了 Disqus 留言版功能,那当真的有人留言之後,我该怎麽去管理这些留言...
Ubersuggest 免费 SEO 工具教学,支援中文关键字分析与内容建议
经营自媒体网站最重要的就是要让文章被看见,有了流量才有信服力,而要曝光文章最快的方法除了购买付费广告...
Transactions (3-2) - Weak Isolation Levels - Snapshot Isolation
续 Day 3 Snapshot Isolation 和 Repeatable read 先来看个...
Day 29 : 案例分享(9) 活动 - 线上报名、线上缴费及线上会议
案例说明及适用场景 基本上适用於所有需要活动举办的相关场域 整合网站及线上购物模组,用於广告行销及线...
[DAY 24]Embed功能
今天主要是来介绍一下文字嵌入(Embed)这功能 如果想要在讯息里使用mark down功能的话需要...