[Day 13] 资料产品生命周期管理-加工资料(二)
接续上篇
介绍一下一般开发 ETL 的流程。每只 ETL 都可以看作是独立的程序,有独立的开发流程。
Implment
设计原型
跟一般的软件开发一样,先从最关键的点开始做 POC,确认商业逻辑和资料是可行的再做後续开发。
如果是简单的 SQL Aggregation,就先确认 SQL 语法和逻辑没有问题;如果是比较复杂的流程(例如多个 ETL 转换),就要先确认每次 SQL 的结果与运算是没有问题的。等流程确认好之後再着手开发正式的 ETL Job。
一般来说大部分的 ETL Job 流程会很雷同,所以在设计上需要反覆将雷同的部分精炼成共同的元件,这样 Job 之间只要最小幅度的改动商业逻辑或变项就能快速开发新的 ETL Job。
变数设置
为了减少程序的变动,一些常用容易变化的部分建议抽出来做成变项,同长几个比较固定的变项会包括:
database 和 table 的名称
对於 ETL 来说, database 和 table 的名称很容易根据部署的环境和阶段来改变,透过变数来管理会比较方便。
连线方式
呈上,连线路径、帐号密码也是独立於商务逻辑会根据状况改变的部分,所以这部分也需要透过变数来管理。
如果有些 Adhoc Query 只有每次搜寻条件不一样的话,也可以将 where condition 做成变数,这样就可以很简单的下类似的查询。
设计模式标准化
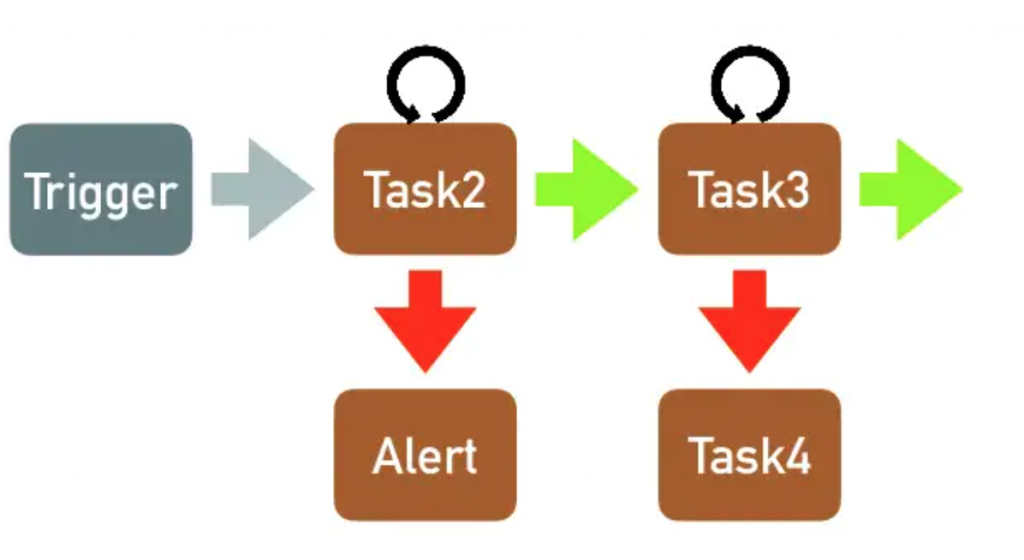
ELT 通常会有相似的模式,身为开发者当然希望能尽量减少重复,所以需要思考怎麽让 ETL 的过程变得标准化,减少开发时间。更有人认为资料工程师不应该写 Airlfow DAG,而是要开发能够产生 DAG 的工具。
Data Engineers Shouldn’t Write Airflow Dags — Part 1
测试
通常测试会有几个阶段
Unit Test
如果你有自己些处理资料小工具的话,会针对这个小工作来做 Unit Test,例如测试能不能顺利读取档案、将清除不合法的资料,再将资料存到 DB 去等等。这边通常会用 Mock 或是小量的资料来做 Unit Test。
整合测试
每个 ETL Job 是由多个小的 Task 组合再一起,这边主要是测试流程和商务逻辑。
Staging 环境测试
Staging 环境理论上资料会近似生产环境,这边主要是测试 ETL Job 能不能负荷生产环境的资料的量,包括能不能在预定的时间内将结果产出、运算资源是否足够等。
Deployment
一般程序部署流程就是分 Staging 和生产环境,但是如前面文章说的,资料很的不确定性很高,为了怕资料在意外的情况下污染到正式环境的资料,就会使用「两阶段转换」。将处理完的结果,先放到别的地方,等资料验证没有问题後,再进入正式的 DB。
然而二阶段转换并不是说单纯把资料放到 Staging 环境而已,以下就来说明开发 Data Pipeline 通常的做法,以及环境的区分。
从测试到正式环境
由於 ETL 的正确性涵盖了两部分:1. 原始资料的正确 以及 2. 商务逻辑的正确,所以一般来说,比较严谨的开发流程会是这样子:
-
测试资料 => 测试资料处理程序 => 测试 DB(先确认资料处理程序正确)
-
测试资料 => 正式资料处理程序 => 测试 DB
-
正式资料 => 正式资料处理程序 => 测试 DB (确认资料处理程序能应付正式资料)
-
正式资料 => 正式资料处理程序 => 正式 DB
这边用的方式其实都只算是一阶段的转换,加入二阶段转换後最终会像这样。
正式资料 => 正式资料处理程序 => 暂存区 => 确认资料品质 => 正式DB
其他变形应用
当然除了放到暂存区之外,也可以直接在程序里确认程序品质,放在同一个处理程序中:
正式资料 => 「正式资料处理程序 => 暂存区(in memory) => 确认资料品质」 => 正式DB
当然当资料量大,或是需要累积多一点资料一起验证时,还是会先落地在检查。
正式资料 => 正式资料处理程序 => 暂存区(in db 或其他persistance storage) => 确认资料品质 => 正式DB
当资料流是同时结合 mini-batch 一边收资料和转换资料,但是只需要 batch 近 DB 时,就很适合使用上面这种方式。例如每十分钟从 server 那边收一次 log 资料,但再转存到正式环境之前,只需要每天确认当天的总数有没有太大的差异,或是需要合并检查资料范围有没有特别的偏差值就好。这时候中间的暂存区可能就会先放在一个暂存的表格中,当作中继资料来处理和检查。
Evaluation
正式上线後,还是要注意资料品质和 ETL 运行状况,通常可以分为资料和资源两个面向来做监测:
资料面
基本的包括每天原始资料量、处理後的资料量、以及处理过程中有没有错误的状况。比较进阶的话还会监测几个关键的统计值,确保资料有没有异常。
资源面
包括运算资源以及储存资源的监控。当 ETL Job 越来越多的时候,就要观察运算环境的资源够不够,不然不同排程的运算相互冲突时,会造成运算失败或是没有在预计的时间内完成。
除此之外,储存资源的监控也是非常必要,有时候运算单元会在 local 存放暂存档案,当硬碟爆满将会造成任务失败;另外生产环境中的储存空间也是要持续监控,不管是前端收资料的 Kafka、或是存放最终资料的 DB,一但没有注意到将会造成资料永久的损失。
Iteration
加工资料如同原始资料可以分为一次性的以及会持续产生的。需要注意的问题也跟原始资料一样,如果要更改持续产生的加工资料,需要特别注意不要影响到现有的资料管线,非常推荐使用二阶段验证的方式来做迭代,以确保资料品质稳定。
Day 11:架设 Grafana (0)
做好了指标的收集,接下来还有一个很重要的步骤 --- 数据的视觉化,关於这方面的功能虽然 Prome...
Day 30 - 从写对到写好
前言 第一次参加铁人赛,完赛的这一天,简直像是学测考完走出教室的感觉!充满兴奋与骄傲! 一方面是成功...
[Day27]程序菜鸟自学C++资料结构演算法 – 堆积排序法(Heap sort)
前言:在第16、17天的时候有介绍到堆积,今天要利用堆积的特性来实现排序法,忘记或不知道堆积是甚麽的...
前端工程师也能开发全端网页:挑战 30 天用 React 加上 Firebase 打造社群网站|Day15 对文章按赞
连续 30 天不中断每天上传一支教学影片,教你如何用 React 加上 Firebase 打造社群...
Day30 - 使用 Rails Generator 快速实作卡米狗学说话
LINE Developers:https://developers.line.biz/zh-ha...