DAY13 特徵工程-资料标准化与降维
一、为何要做标准化
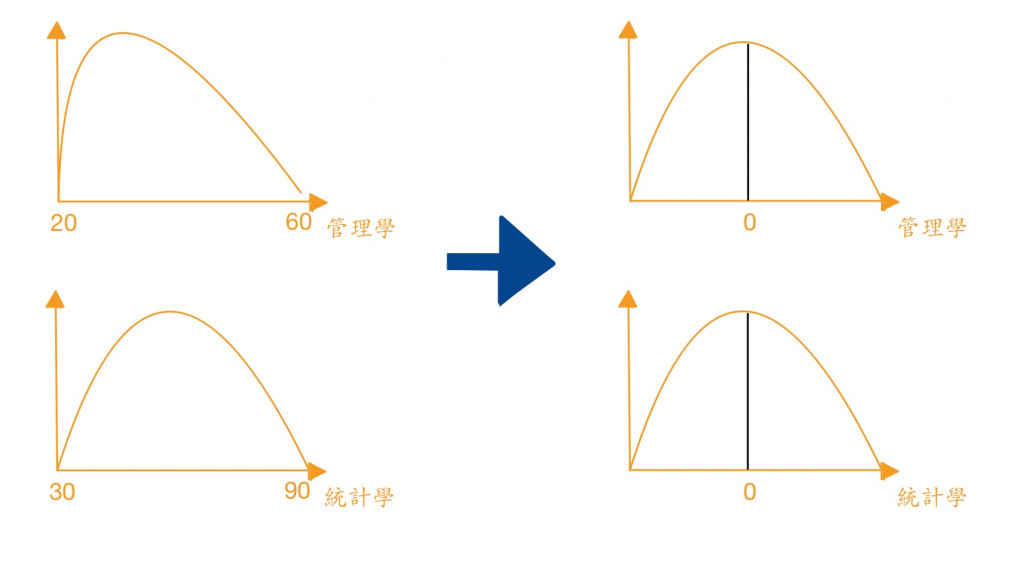
以最简单的方式来说,一份资料中,不可能每个特徵的范围都是一样的,当我们需要拿两笔特徵资料来做处理时,就必须让他们的评比标准都相同才会准确。举里来说,研究所考试中有些科目是可以选考的,有些人选管理学、有些人选统计来考,但因为题目不一样你不能直接拿两笔资料的分数来排名。因此我们必须透过标准化的方法把两笔资料的范围变成相同,资料拿来比较才具有意义且公平。
二、标准化方法
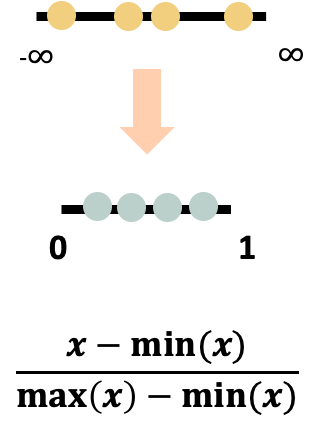
1. 正规化
又称最大最小化。可防止较大初始值域与较小初始值域属性间互相比较的情况,以及权
重过大的问题。将值压缩到[0,1]之间。可以避免离群值影响资料。(如下图)
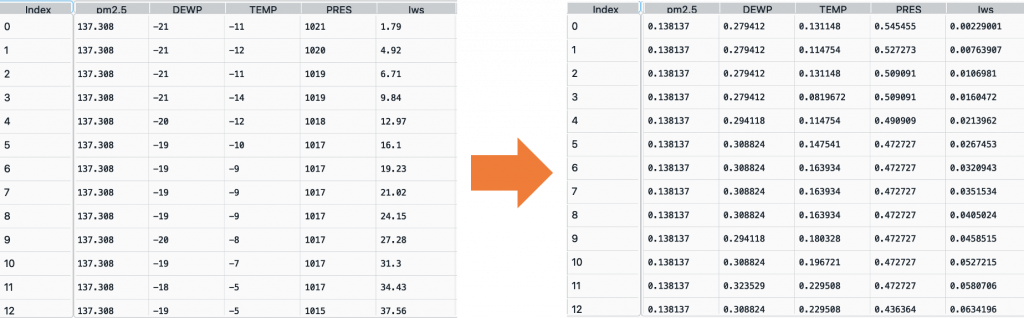
train=pd.read_csv("train.csv")
y=pd.DataFrame(train["pm2.5"])
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
y_train_scaled = scaler.fit_transform(y)
train_scaled = scaler_two.fit_transform(train)
train_scaled=pd.DataFrame(train_scaled,columns = ['month', 'day', 'hour', 'pm2.5', 'DEWP', 'TEMP', 'PRES', 'Iws', 'Is','Ir', 'cbwd_NE', 'cbwd_NW', 'cbwd_SE', 'cbwd_cv', 'year_2010',
'year_2011', 'year_2012', 'year_2013', 'year_2014'])
2. 标准化
将不同的资料变成相同的标准值,以我刚才举的例子来说,透过标准化,我们可以将资料变成平均值为0变异数为1的标准常态分配,而转换过後我们就可以拿来做比较了。
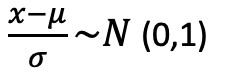
def normalize(x_train, x_test, method = 'StandardScaler'):
'''
method = 'StandardScaler', 'PowerTransformer', 'MinMaxScaler'
'''
if method == 'StandardScaler':
normalize_function = preprocessing.StandardScaler()
if method == 'PowerTransformer':
normalize_function = preprocessing.PowerTransformer(method='yeo-johnson', standardize=True) # yeo-johnson, box-cox
if method == 'MinMaxScaler':
normalize_function = preprocessing.MinMaxScaler()
features = x_train.columns
for feature in features:
reshape = np.array(x_train[feature]).reshape(-1, 1)
x_train[feature] = normalize_function.fit_transform(reshape)
reshape = np.array(x_test[feature]).reshape(-1, 1)
x_test[feature] = normalize_function.transform(reshape)
return x_train, x_test
right_ratio_x_train, right_ratio_x_test = normalize(right_ratio_x_train, right_ratio_x_test)
3. log转换
当资料为常态分配的时候,他的范围介於-∞<x<∞之间,但生活中很少有资料介於这个范围。因此我们将资料经过log转换後,资料的范围就会介於0<x<∞之间了。
log_df = np.log1p(df["你要转换的资料名称"])
三、为何要做降维
在使用一些监督式学习的模型时,丢入训练的资料维度对结果有很大的影响,当丢入训练的资料的维度较大时,我们需要用一些方法来降低数据维度,虽然不能保证说用这个方法就一定能让结果变好,但在做资料分析时就要有勇於尝试的态度,才有机会找到最适合这笔资料的处理方法。
四、降维的方法
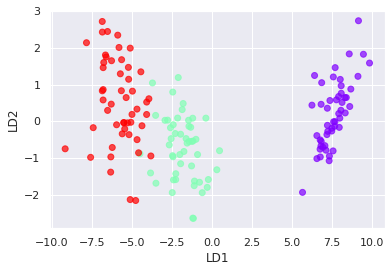
1. LDA
是一种用来确定“最佳”变量集,识别一个新的轴,并用来分类
用内建资料集资料鸢尾花实作
import numpy as np
import pandas as pd
from sklearn import datasets
#载入资料集
iris = datasets.load_iris()
iris.keys()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
#使用LDA将资料变成二维
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)#将资料缩减成两个维度
X_lda = lda.fit_transform(X, y)
lda.explained_variance_ratio_
2. PCA(主成分分析)
主成份分析的主要目的为,用较少的变数解释原始资料中大部分的变异,并将原本相关性很高的变数转换成相互独立的变数,降低变数的维度。
底下我们用内建资料集资料鸢尾花实作
import numpy as np
import pandas as pd
from sklearn import datasets
#载入资料集
iris = datasets.load_iris()
iris.keys()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_train)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.scatter(
X_pca[:,0],
X_pca[:,1],
c=y_train,
cmap='rainbow',
alpha=0.7,
edgecolors='b')
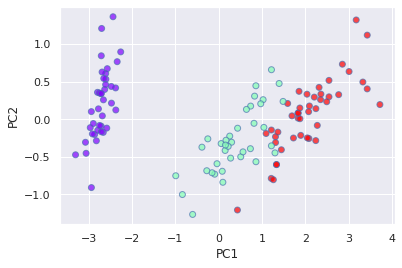
3. LDA和PCA差别
PCA 是一种非监督式算法,其目标是找到资料集中的主成分之间最大的变异数。
LDA 是一种监督式的半别方法,将资料投影到轴上。可以形成特徵内彼此之间最小差异,与不同特徵最大差异。
五、结论
今天所介绍的这些方法参杂了很多数学概念,若读者们有兴趣可以自行到网路上去收寻相关的数学知识来看,对知识的了解越深越广,在资料分析这条路上才能走得更加长久喔~
写机器人必备 -- 函式的操作
创建第一个函式 def functionname([parameterlist]): ["...
[铁人12:Day 28] 「AI 的未来十年」摘要 4:混合式架构
要把那些技术混合在一起,才能达到我们的目标呢? 符号式操作 (Symbolic Operation)...
[2021铁人赛 Day04] General Skills 01
引言 今天我们就正式来解题吧! 就先从最基础的 General Skills 开始, 一边解题一边...
追求JS小姊姊系列 Day5 -- 工具人登场
前情提要 突然出现在我身後的三人组是!郑列,方函式,阿物件 而三人中,站在最前方的就是郑列。 三人:...
DAY 29:Iterator Pattern,迭代各种不同的物件
什麽是 Iterator Pattern? 将不同资料物件透过一致的方式取得其中的元素 问题情境 s...