Day6-AI Performance
本章开始归纳出几个K8s特性可以提升AI效能并以Spark计算圆周率Pi示范。原文写於2019如无法执行请阅读官方文件
1.Namespace
Namespace 的概念,很多程序语言都有Namespace(命名空间)的概念比如在C++中我们可以透过不同的Namespace(命名空间)创造两个相同名子的变数Variable,Namespace在K8s也是类似的用法,比如我们可以创造一个命名空间叫做Intern 一个叫做Employee,就可以在各自Namespace(命名空间)跑各自的Spark不会冲突不用排队不用考虑FIFO, Priority,另外我们也可以给予两个命名空间不同的计算资源CPU/GPU,这样就算全公司都挤在同一个云平台也不会产生实习生的程序排挤到资深人员的工作。
首先启动一组GKE群集共有5个节点每个节点4CPU, 3.6MEM,因为Saprk官方预设有启动Anti-affinity机制,毕竟Spark就是个分散式计算引擎当然要一次开5个node来玩玩才有趣,至於预设为何要开启Anti-affinity後面文章会解说。
接着点上图中的"连结"会SSH连线到GKE Master,并执行以下指令创造两个namespace。
kubectl create namespace spark-intern
kubectl create namespace spark-employee

接着在下kubectl get namespaces,我们就可以看到刚刚创建的Namespace(命名空间)

接着我们帮它配置资源使用量,下面这段程序码用cat>> filename << EOF包起来,直接复制贴上不用vi
cat >> StaffResource.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quotas
namespace: spark-intern
spec:
hard:
requests.cpu: "3"
requests.memory: 4Gi
limits.cpu: "3"
requests.memory: 4Gi
---
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quotas
namespace: spark-employee
spec:
hard:
pods: "5"
requests.cpu: "10"
requests.memory: 16Gi
limits.cpu: "10"
requests.memory: 16Gi
EOF
接着下kubectl create -f StaffResource.yaml运行yaml档

接着我们要在两个Namespace(命名空间)跑Spark官方的spark-pi程序,来看看两者是否真的有同时处理没有冲突,并且是否有依照我们所设定的资源数量进行运算,在这之前先帮spark开启对应的权限serviceaccount与clusterrolebinding即K8s群集控制权。
kubectl create serviceaccount spark-intern -n spark-intern
kubectl create clusterrolebinding spark-intern --clusterrole=edit --serviceaccount=spark-intern:spark-intern -n spark-intern
kubectl create serviceaccount spark-employee --namespace=spark-employee
kubectl create clusterrolebinding spark-employee --clusterrole=edit --serviceaccount=spark-employee:spark-employee --namespace=spark-employee

接着下载Spark程序,解压缩进入资料夹
wget http://apache.mirrors.lucidnetworks.net/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
sudo tar -xzf spark-2.4.4-bin-hadoop2.7.tgz
cd spark-2.4.4-bin-hadoop2.7
接着再找出K8s Master的IP,填入bin/spark-submit的--master参数後
K8sMaster="k8s://$(kubectl cluster-info | grep -n "Kubernetes master" | cut -f 6,6 -d " ")"
echo $K8sMaster

再来我们要来执行Saprk-pi任务,记得将echo $K8sMaster得到的字串取代bin/spark-submit的--master参数,这里我们启动两个Terminal分开执行
bin/spark-submit \
--master <K8sMasterIP ex: k8s://https://35.200.234.221> \
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=10m \
--conf spark.kubernetes.executor.limit.cores=50m \
--conf spark.kubernetes.namespace=spark-intern \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-intern \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
bin/spark-submit \
--master <K8sMasterIP ex: k8s://https://35.200.234.221>\
--deploy-mode cluster \
--name spark-pi \
--class org.apache.spark.examples.SparkPi \
--conf spark.executor.instances=5 \
--conf spark.kubernetes.driver.limit.cores=1 \
--conf spark.kubernetes.executor.request.cores=100m \
--conf spark.kubernetes.executor.limit.cores=500m \
--conf spark.kubernetes.namespace=spark-employee \
--conf spark.kubernetes.container.image=ted00132/spark:v1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-employee \
local:///opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar
接着用kubectl get pod --all-namespaces或kubectl get pod -n spark-intern或kubectl get pod -n spark-employee,就可以看到POD进程运行的状况

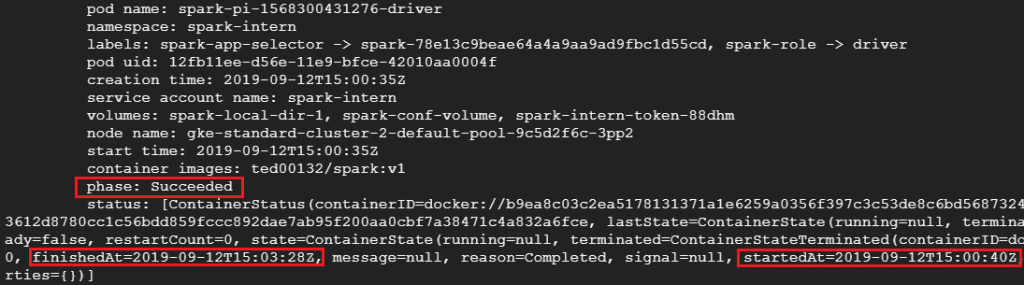
接着我们可以看到两组相同的Spark-pi程序分别在不同的namespaces命名空间执行并且依照我们给予的配额与POD/Spark-Executor数进行分散式运算,根据下图我们可以看出spark-intern中的Spark花了3分28秒才解出pi而spark-employee中的spark只花了25秒就解出pi;这跟我们给予的CPU配额与POD/Spark-Executor数呈现正相关,喜欢追根究底的朋友可以用以下指令看POD/Spark-Executor实际的配置
kubectl describe pod <pod-name or spark-executor-name> -n <namespace-name>
实际的配置会跟我们再bin/spark-submit输入的几个 --conf参数一样,并受到StaffResource.yaml所设定的配额限制,有兴趣的朋友可以试试不同参数!最後附上执行结果图。
<<: Day 13 「难兄难弟」 单元测试、Code Smell 与重构 - Data Clump 与 Primitive Obsession 篇
>>: Day 1 :Why do I write this topic?
CallStack
由於JavaScript是单线程的语言,所以从上而下设计就很重要,若有点困难可以先去看Functio...
day10: CSS style 规划 - utility CSS(Tailwind)-1
在前面章节我们介绍过 纯 CSS, CSS in JS 那接下来我们要来介绍 utility CSS...
介面隔离原则 Interface Segregation Principles
最後,我们来到了 SOLID 当中的介面隔离原则。这里我们先举先前提到过的 BaseballPlay...
[C 语言笔记--Day27] 6.S081 Lab syscall: Sysinfo ( II )
接续昨天写到一半的题目, 昨天还留下了 sys_sysinfo() 没有完成, 先来大致上分析一下这...
[Day12] Face Detection - 使用OpenCV & Dlib:Dlib MMOD
好酒沉瓮底,精彩在最後;只是要付出一点点代价。 本文开始 前面提到过,使用OpenCV &...