[自然语言处理基础] 文本预处理(I):断开文本的锁练
前言
上次我们提到原始文本往往夹带大量无意义的字符,於是我们利用了正则表达式来清理资料。然而此时的文本由大量的语句所构成,各个语句中又带有复杂的文法结构(例如倒装修词、时态差异、关系代名词、分词构句、形容词的前後位修式等)和各种对於电脑来说晦涩难懂的资讯(例如华丽的词藻),尚未能进行分析与处理。因此我们仍需要将清理过後的文字资料进一步拆解成电脑可以处理的最小单位。以英文而言,词(word)可以被视为一种最小单位,词与词之间有着明显的分隔,而中文的字(character)不一定能单独表示其在文本中所呈现的意义,很难区隔出可处理的最小单位。本篇的自然语言处理技巧围绕在以英文为代表的屈折语(fusional language: 为印欧语系中普遍的语言,如法文、德文、西班牙文等拼音文字),可藉由词与词之间的空格找出最小单位,而暂不涉及以中文为代表的孤立语(isolating language)或以日文、韩文为代表的黏着语(agglutinative language)。
由於中文词集是一个开放集合,不存在任何一个词典或方法可以尽列所有的中文词。当处理不同领域的文件时,领域相关的特殊词汇或专有名词,常常造成分词系统因为参考词汇的不足而产生错误的切分。
断句(Sentence Segmenation)与断词(Tokenisation)
让我们直接来瞧瞧以下这篇短文:
"When you start coding, it makes you feel smart in itself, like you're in the Matrix [film]," says Janine Luk, a 26 year-old software engineer who works in London. Born in Hong Kong, she started her career in yacht marketing in the south of France but found it's "a bit repetitive and superficial". So, she started teaching herself to code after work, followed by a 15-week coding boot camp.
文字出处:Why coders love the AI that could put them out of a job| BBC Business
在 Python 的实践上,我们使用自然语言处理工具箱 NLTK (Natural Language Processing Toolkit) 来协助我们进行处理任务。第一步我们欲将以上的字串拆分成多个句子,此步骤称之为断句(Sentence Segmentation)。句号(.)是判断句子结束很好的依据,但仍有些例外-省略用的句号,如 Mr. Williams、 Ph.D. 等。 好消息是, NLTK工具箱当中的 tokenize 模组,已经定义好了函式 sent_tokenize() 用来实现断句:
from nltk.tokenize import sent_tokenize
raw_text = '''"When you start coding, it makes you feel smart in itself, like you're in the Matrix [film]," says Janine Luk, a 26 year-old software engineer who works in London. Born in Hong Kong, she started her career in yacht marketing in the south of France but found is's "a bit repetitive and superficial". So, she started teaching herself to code after work, followed by a 15-week coding boot camp.'''
# removing double quotes
text = re.sub(r"\"", '', raw_text)
# breaking text into sentences
text_sentences = sent_tokenize(text)
# printing out sentences
for i, sent in enumerate(text_sentences):
print("Sentence {}: {}".format(i + 1, sent), end = "\n\n")
我们将拆解的句子一一条列出来:

接下来我们进一步将句子拆分成更小的单位-单词。值得注意的是,在英文当中单词通常被认为能够表示意义的最小单位-词条(Token),将字串拆分成词条的过程就是断词(word segementation),又称记号化(Tokenisation)。此词我们引入另一个拆分函式 word_tokenize() :
from nltk.tokenize import word_tokenize
for i, sent in enumerate(text_sentences):
print("Sentence {}: {}".format(i + 1, sent))
tokens = word_tokenize(sent)
print(tokens, end = "\n\n")
经过断词之後,我们检视最短的第三句中的词条:

由於词条可以是单词、标点符号(可以注意 NLTK 的 word_tokenize() 将之也视为词条)、数字、有着特殊意义的符号(如 $ 、 € 、 ¥ 等货币符号),断词的方法并不唯一。我们亦可以根据需求设计其他的 tokenisers ,详见本文最下方的连结 [2]。
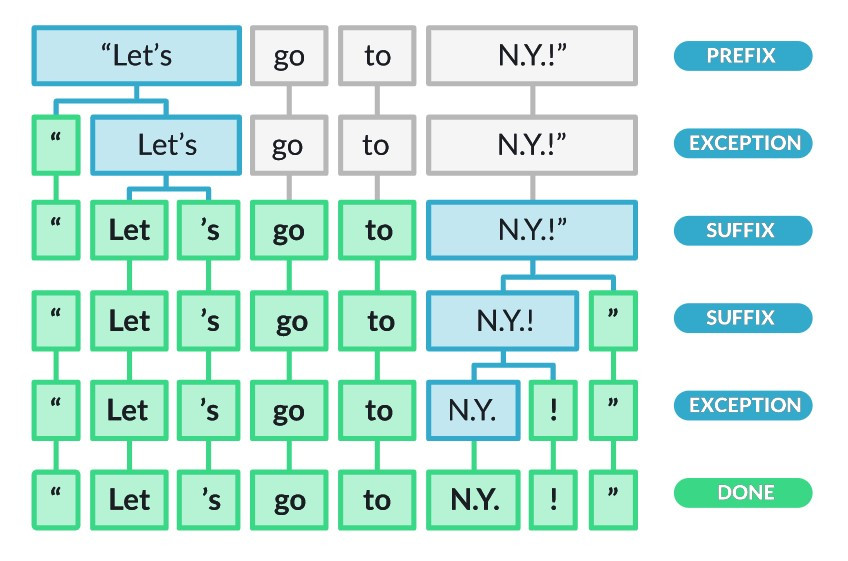
Tokeniser 的设计依赖於语言的选择
图片出处:spaCy 101: Everything you need to know
关於预处理就先介绍到这边,明天我们将介绍文字的正规化!
默默祈祷疫苗的副作用不要太强
Gute Nacht!
阅读更多
IT铁人DAY 1-进入物件导向世界前的心理准备
在开始之前,还是很惊讶自己有天可以在这里写文章,分享自身所学的IT技术,提供给大家参考。那其实我...
见习村27 - First non-repeating character
27 - First non-repeating character Don't say so mu...
通过 ESG 保证增加价值的 3 种方法
环境、社会和治理 (ESG) 保证正日益成为全球组织关注的焦点——稽核团队需要做好应对的准备。 投资...
[Day_5]Python 字串(2)
字串的内建函式 字串类别内建许多函式, 只要是Python字串就自动拥有这些函式, 以下介绍常用的内...
【从零开始的 C 语言笔记】第二十篇-While Loop(2)
不怎麽重要的前言 上一篇介绍了while loop的概念,让大家在回圈的使用上可以相对的弹性。 这次...