[Day 11] 资料产品生命周期管理-原始资料
不同类型的资料产品在其各自专案周期有需要注意的地方,以下我们将说明在处理原始资料时,各阶段应该做的事情
Initiate
在初始阶段,最重要的就是要了解搜集资料的需求。尽管我们很难知道这些资料未来还需要做哪些用途,但至少要把当下的需求弄清楚。我们可以把常见资料需求分为几种类型:
-
纪录资讯 - 这边指的就是单纯留存用的纪录、像是 Log 讯息、系统资讯、Audit 资料,这些记录会一直被写入DB 或储存装置,写下去之後也不太会修改。
-
分析建模 - 有些资料是为了分析用途,像是统计分析、市场调查,这些资料需要考量到分析和建模的方便,会尽量以「大表」的形式来搜集。
-
前端互动 - 像是大家在看的 Blog、或是电商网站等,需要将这些要呈现的资讯、以及跟使用者互动的资料存在後端资料库,这些资料会根据使用者互动写入或是被读取,通常会将资料做正规化。
Design
设计阶段当然就是根据之前调查的用途,来决定资料的搜集方式。一般来说在设计上要考量几点:
- 资料搜集方式 - 考虑资料要怎麽搜集,是要抽样呢还是全收、是用系统纪录还是人工、如果是系统的话要用 DB、Excel 作为後台还是其他方式。
- 资料内容 - 资料要存哪些内容、需要用什麽格式来存、如果是存 DB 的话、个别栏位又是什麽属性。
- 纪录资讯 - 由於这些纪录资料之後可能会被拿来查询,所以在设计上需要考量到 Log 等级、栏位好不好被检索、有没有足够的资讯、资讯的格式是否一致等等。
细节设计方式可以参考:The Art of Logging
- 分析建模 - 有些资料是为了分析用途,像是统计分析、市场调查,这些资料需要考量到分析和建模的方便,会尽量以「大表」的形式来搜集。
关於调查的资料设计可以参考:Survey Data
- 前端互动 - 像是大家在看的 Blog、或是电商网站等,需要将这些要呈现的资讯、以及跟使用者互动的资料存在後端资料库,这些资料会根据使用者互动写入或是被读取,通常会将资料做正规化。
资料正规化介绍:
https://en.wikipedia.org/wiki/Database_normalization
Data Model
在设计阶段,如果资料很复杂,最重要的事情就是需要整理 Data 之间的关联,通常会用 Data Model 的方式来呈现。Data Model 的设计除了考量需求之外,也须要一并考量储存方式和资料内容。
(https://www.instaclustr.com/cassandra-nosql-data-model-design-2/)
Implement
在开发阶段要注意的事情倒不是很多。只要注意好设计规格,基本上用哪种语言来实作都差不多。
-
纪录资讯:要注意需要在开发时设定好 Logger Level,这样才能方便调整届时程序输出的资讯。Logging facility for Python
-
分析建模:如果是一次性的分析资料在开发时更要注意资料的正确性,没有处理好就付之一炬了。
-
前端互动:在开发这种跟资料库串接的後端程序时有非常多设计方式以及眉角需要注意,不是几句话就写得完了,这边就真的只能给几个关键字让大家查询,像是:
- RESTful API:API 实作(一):规划 RESTful API 要注意什麽
- MVC: Design Patterns - MVC Pattern
- Event Sourcing: Pattern: Event sourcing
Deployment
由於搜集资料的程序坏了就没救了,部署搜集资料的程序时,需要严格的测试来避免资料丢失或脏资料进入,因此在部署之前「通常」会有严格的测试和 QA 机制。
这部分要测试的东西(针对资料的部分)包括几点:
- 基本资料规格是否正确
- 是不是有意外的状况会产生意外的资料,例如问卷逻辑没有设定好,造成不可能出现的答案;或是没有检查资料的正确性,产生意外的资料(像是不符合 email 规范的 email)。
- 当资料大量产生时,可能造成的问题(例如资料延迟、储存空间是否足够、应用是否可以顺利读写)
Evaluation
上线之後需要评估的东西基本除了资料规格、资料量、意外的状况之外,也要特别评估资料是否能够回答一开始在发想阶段的商务需求,是不是有少收的或多收的情况出现。
Iteration
在迭代阶段当然就是根据之前的评估结果来做改善,这边我们特别分为一次性的资料搜集以及持续性的资料搜集来介绍需要留意的地方:
一次性的资料搜集
如果是一次性的资料搜集,像是单次的调查、或是单次的活动,已经搜集的资料并不会影响新的资料时,在迭代上其实就可以放心的改善。
持续性的资料搜集
反之,如果像是 Log 蒐集、交易资料搜集、或是後端资料库,过去的资料会延续到未来使用时,在迭代上就需要特别小心。例如我们在做资料分析的时候可能都会用到最近半年的资料,如果资料来源在第三个月有经历改版,那就会影响到分析的状况,而这个影响会持续三个月,一直到旧版本的资料不再被纳入分析为止。或例如像下图的状况:在 v1 的时候我们会蒐集使用者的点击资料。到了 v2 的时候可能因为前端 App 改版,造成点击量突然提高,发现後紧急更新了 v 2.1 来修正这个异常。
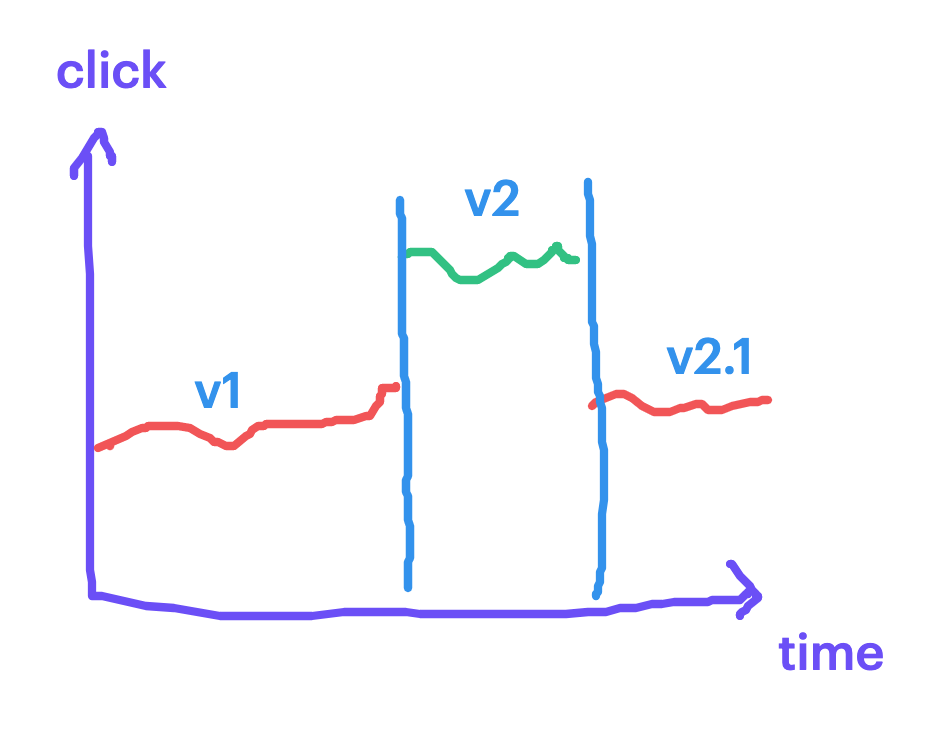
因此在持续性的资料蒐集时特别需要留意以下状况:
- 资料版本 - 由於资料在蒐集内容上或定义可能有变化,需要区分出不同版本的资料定义。
- 蒐集资料工具的版本 - 例如 App,有时 App 的改版会造成资料蒐集的异常。
- 前後资料的呼应:
- 同一个栏位的定义在改版前後是不是一致?
- 资料格式是不是一致?
- 淘汰或是新增的资料?
References
https://www.codeproject.com/Articles/42354/The-Art-of-Logging
>>: Day 10:Component, Component, Component
Kotlin Android 第17天,从 0 到 ML - MVVM架构 - LiveData
前言: 学会了ViewModel,接下来就是建立观察 LiveData。 大纲 : LiveData...
个人管理 - 技术提升
试想,24岁研究所毕业,就算是25岁投入职场,到了30岁,那个时候的自己是怎麽样的自己? 前面提到,...
当执行一个耗时较久动作时,提供良好的使用者体验
你我应该都有类似的不佳体验:点下一个按钮时,画面什麽也没有改变,你以为刚刚没点到,又再点了一次,发现...
Day 20:县市乡镇小工具包(util)
本篇文章同步发表在 HKT 线上教室 部落格,线上影音教学课程已上架至 Udemy 和 Youtu...
[Day 24] Facial Landmark: MTCNN
侦测人脸位置与人脸关键点,两个混 合 在 一 起 MTCNN -- Multi-task Casc...