[Day 24] Facial Landmark: MTCNN
侦测人脸位置与人脸关键点,两个混 合 在 一 起
MTCNN -- Multi-task Cascaded Convolutional Networks
从完成名称可以看出一些端倪:
- 多任务 (multi task):同时学习侦测人脸与辨识人脸关键点任务
- 级联 (Cascade):与Day9的哈尔特徵检测法一样,使用每一层计算的输出当作下一层的输入,从简单的判断开始去除不需要的区域,再慢慢深入去判断需要的结果
- 卷积网路 (Convolutional network):Day 18已简单说明过,就是影像处理最常用到的神经网路结构
到这里你已经知道MTCNN的精随了,剩下的就是如何训练MTCNN。
但这部分是需要精心设计训练资料,以及分阶段训练MTCNN (P-Net -> R-Net -> O-Net),
这里我们只专注在如何使用,
Let's Go!
本文开始
- 开启专案,在
facial_landmark目录下新增mtcnn_predictor.py - 在你的Python环境中安装
- mtcnn (版本:0.1.1)
- tensorflow (任意2.0以上版本)
- 打开
mtcnn_predictor.py,输入下面到目前为止最简单的程序码:import time import cv2 import mtcnn from imutils.video import WebcamVideoStream def main(): # 初始化模型 detector = mtcnn.MTCNN() # 启动WebCam vs = WebcamVideoStream().start() time.sleep(2.0) while True: frame = vs.read() rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) faces = detector.detect_faces(rgb) for face in faces: (x, y, w, h) = face['box'] keypoints = face['keypoints'] conf = face['confidence'] cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2) cv2.putText(frame, f"confidence: {str(round(conf, 3))}", (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 2) for (s0, s1) in keypoints.values(): cv2.circle(frame, (s0, s1), 2, (0, 0, 255), -1) cv2.imshow("Frame", frame) key = cv2.waitKey(1) & 0xFF if key == ord("q"): break # 清除用不到的物件 cv2.destroyAllWindows() vs.stop() if __name__ == '__main__': main() - 直接在terminal输入
python facial_landmark/mtcnn_predictor.py
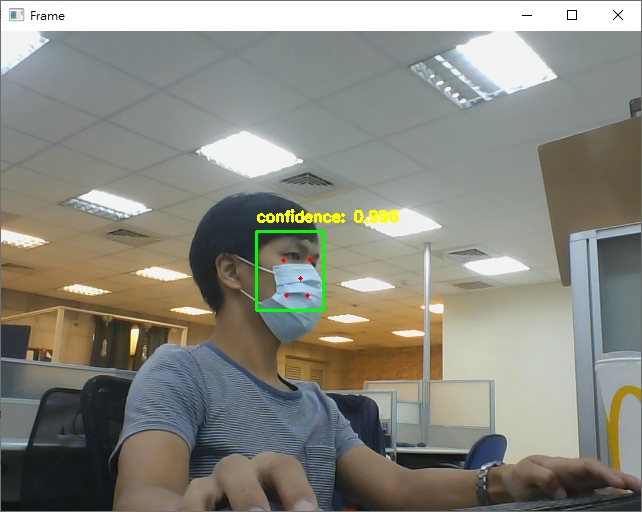
这次我给模型更困难的辨识情况:
- 离镜头更远
- 使用侧面脸
- 戴上口罩
但实际辨识结果你可以看到:不但辨识率有90%以上,也可以大致上辨别出眼、鼻、嘴等的位置。
而实际上,
FaceNet网路在训练人脸辨识时也是使用MTCNN当作人脸侦测与人脸关键点任务使用
好工具,不学起来用吗?
<<: 用React刻自己的投资Dashboard Day22 - API与前端资料需求比对
>>: Day 22 - Spring Boot & Interceptor
创建App-现界面与连接
创建App-现界面与连接 经过了十五天的努力,现在就来看看现有的界面功能吧,我依照功能来区分:登入、...
DAY12 如何使用样板
做完大概长这样,左边的图片就会是显示在line上面的样子,有兴趣可以自己摸索一下,这边还有一个重点是...
[ Day 16 ] - 事件
事件 指的是在 DOM 上所发生的事件,换句话是可以是特定的动作被触发後,必须要执行对应的事情。 (...
DAY3-EXCEL统计分析:认识离散型机率
离散型机率 离散行机率包括很多种,例如:白努利型分布(Bernoulli distribution)...
[区块链&DAPP介绍 Day28] Dapp 实战 留言版 - 2
今天来把剩下的留言板,前端的部分完成吧 先看看 js 的 code import Web3 from...