DAY11 资料前处理-资料不平衡处理方法
试想一下,如果有个模型号称有99%的准确率,那这个模型好不好呢?答案是不一定,在处理分类问题时,我们很常会遇到的一个状况就是"资料不平衡",也就是负样本的数量远小於正样本。
举个例子,我们在分析信用卡盗刷的资料时,盗刷算是负样本,发生的次数绝对比正常交易来的多,因此,若完全不做任何处理,我们的模型会大量的学习到正样本的资料,在预测时很容易发生过度拟合(Over-fitting)的问题,假设正常比盗刷的比例是99:1,我们的模型预测100份资料都是正常,这样的准确率是99%,可是他完全没有预测到错误的那笔,那这个模型还有用吗?因此,处理资料不平衡的问题也是一项重要的前处理!
一、不平衡资料(Imbalanced Data)
不平衡资料通常发生在良率分析、好坏分辨等案例,因为坏的都是少数案例,我们想要训练模型挑出这些资料所做的分析。
那所谓不平衡的标准是多少呢?我们可以用铁达尼号资料集看一下。
利用套件看出特徵的资料量
train_df['Survived'].value_counts()
画出圆饼图查看样本比例
import matplotlib.pyplot as plt
plt.figure( figsize=(10,5) )
train_df['Survived'].value_counts().plot( kind='pie', colors=['lightcoral','skyblue'], autopct='%1.2f%%' )
plt.title( 'Survival' ) # 图标题
plt.ylabel( '' )
plt.show()
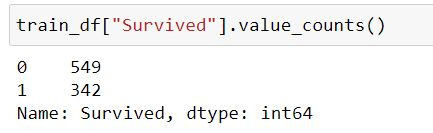
可以看到比例存活与罹难的比例大概是6:4,这样就是个差不多正常的比例。可以处理也可以不处理,接着让我们来看看另一份资料集。
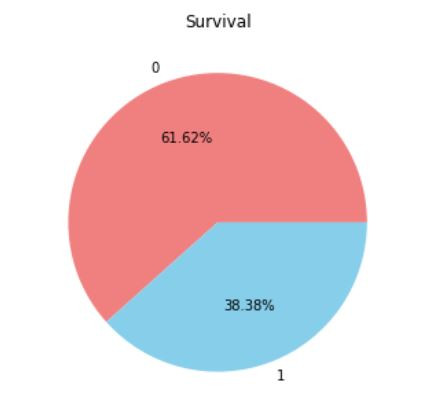
这是一份半导体制造的良率分析,-1代表Pass,1代表Fail,资料占比如下
这样的资料集就是比例相当悬殊的,我们必须经过处理後才能丢进模型训练,否则就会发生过度拟合的问题,而处理方法分为上采样(OverSampling)以及下采样(UnderSampling)。
二、下采样(UnderSampling)
下采样的方法是透过删除较多的样本数,使两个类别的样本数量达到平衡,这样的方法虽然方便,但其实缺点也很明显,我们会失去大量的数据,以上面半导体的资料集来举例,我们假如使用下采样的方法,我们最後的资料集只会有原本的10%,这样的方法其实是很不推荐的。
三、上采样(OverSampling)
上采样的作法与下采样相反,是透过一些方法提升样本数较少的资料,最常见的方法之一就是SMOTE,他是一种数据合成的方法,概念是在少数样本附近的位置,"人工合成"出一些样本,程序码也非常简单,我们以Secom的资料集来做示范。
先分出训练集及测试集
要先做资料分割的动作的原因是,测试集是为了让我们检视最真实的评估结果,因此尽量保留它的完整性,不要去做过多的加工处理。
import numpy as np
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3,random_state=11)
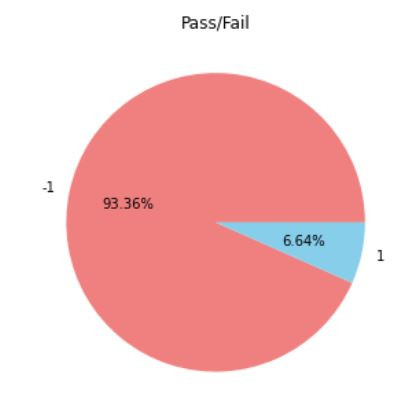
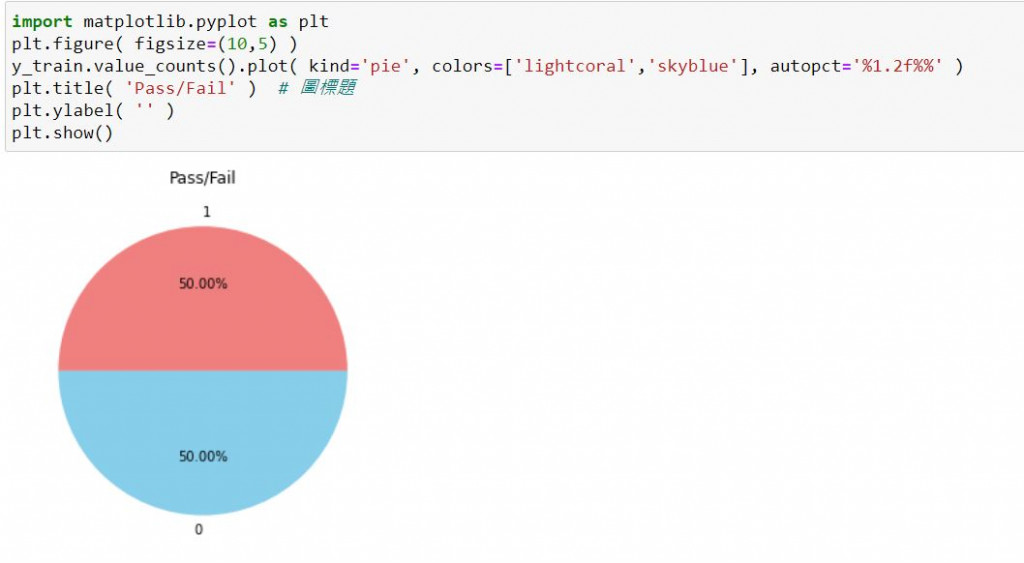
接着看一下资料的占比
import matplotlib.pyplot as plt
plt.figure( figsize=(10,5) )
y_train.value_counts().plot( kind='pie', colors=['lightcoral','skyblue'], autopct='%1.2f%%' )
plt.title( 'Pass/Fail' ) # 图标题
plt.ylabel( '' )
plt.show()
做SMOTE处理
from imblearn.over_sampling import SMOTE
X_train, y_train = SMOTE().fit_resample(X_train, y_train)
看看成果
四、上采样+下采样
上采样的效果明显比下采样还要来的好,但也存在一个缺点,因为我们会大量的对少数样本附近进行复制,很可能合成出一些杂讯或是靠近正样本的资料,而下采样的方法中有一个叫做Tomek Link的方法,他的概念是能删除一些边界辨识度不高的样本,因此我们可以先采用上采样合成样本後,再进行下采样,把一些是杂讯的资料点剃除,程序码也非常简单。
from imblearn.under_sampling import TomekLinks
X_res, y_res = TomekLinks().fit_resample(X_train, y_train)
五、结论
资料不平衡的状况在真实情况中蛮常发生的,今天也介绍了一些常见的处理方法,不管使用何种方法最好都透过交叉验证去检视资料的合理性,虽然合成的方法可能会缺少一点解释力,毕竟资料是凭空出现的,我们也不好去解释他,因此最好的处理方法还是想尽办法去找到更多资料,希望这篇文章对大家有所帮助。
>>: 文章内搜寻,doc docx txt 子目录下所有档 (Python)
Day 13 - .NET Core奇遇记
主导的第一个计画就是帮厂商开发一个平台并且包含3D模型模拟的功能,然後需要有一个後台给厂商能够上传图...
初探 OpenTelemetry
为什麽会接触到 OpenTelemetry,算是因为 Log 的追踪关系,在後台上有两三个 Spri...
各种 Code Generator 的功能
上一篇我们有提到用 KAPT 参数去呼叫 纯 Kotlin 和 Android 的 code gen...
RISC-V: Branch 指令
亲爱的,帮忙去超市买 1 颗苹果回来,如果他们有鸡蛋的话,买 6 颗。 Simple logic p...
制作响应式网站-30天学会HTML+CSS,制作精美网站
响应式网页设计是什麽 响应式网页设计(Responsive Web Design)简称RWD,是开发...