DAY10 资料前处理-资料编码、资料切割
一、资料编码
当拿到类别型资料特徵的时候,我们必须将文字转换成数字供电脑去做计算。举例来说:员工年龄分布(如上图),员工所在部门(如下图)。有发现转换方式不太相同吗?我们在下面来做讲解。
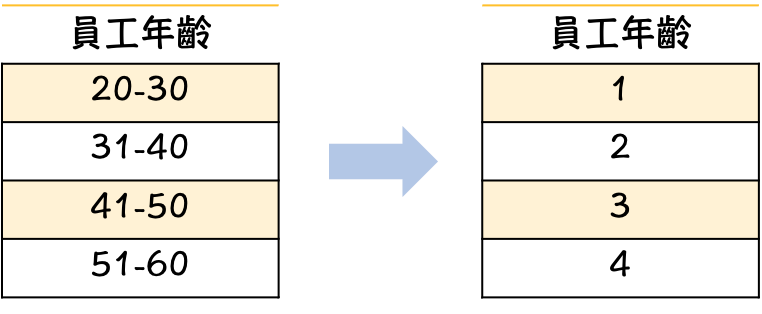
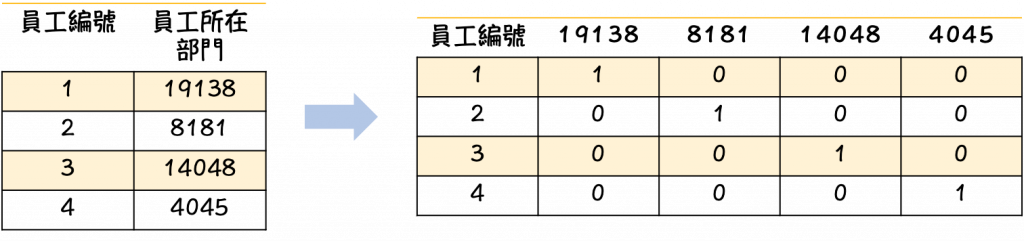
资料编码一般分为Label Encoding 及 One-Hot Encoding两种方法。
1. Label Encoding 跟 One-hot Encoding的差别
为何要分有顺序跟无顺序呢?因为如果把无顺序的资料标示成1、2、3电脑会认为3>2>1,但实际上并非如此。所以最後会导致後面在跑模型的时候会不太准确。

2. Label Encoding实作
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
le.fit(df['你要转换的特徵名称'])
le.transform(df['你要转换的特徵名称'])
3. One-Hot Encoding实作
利用pandas的套件可以快速做出
资料集来源:https://aidea-web.tw/topic/2f3ee780-855b-4ea7-8fc8-61f26447af1d
#先生成虚拟变数
temp_department=pd.get_dummies(df_X["归属部门"],prefix="归属部门")
#将原先资料的特徵删除
df_X=df_X.drop("归属部门",1)
#将原先资料与虚拟变数合并
df_X=pd.concat([df_X,temp_department],axis=1)
二、资料切割
机器学习模型需要资料才能训练,如果将所有资料都丢给模型做训练,这样就没有额外资料来评估模型的好坏,而为了避免模型可能会有过拟合 (Over-fitting) 的情形发生,需透过验证/测试集评估模型是否过拟合。(如下图)就有点类似学校考试的概念,如果一直给学生考一样的考试,那他到最後几乎就是把答案背起来而已,不会去了解题目内容,看似这个学生考得很高分,但实际上他根本就不会,因此在丢给模型训练前,我们要先将资料分配好。
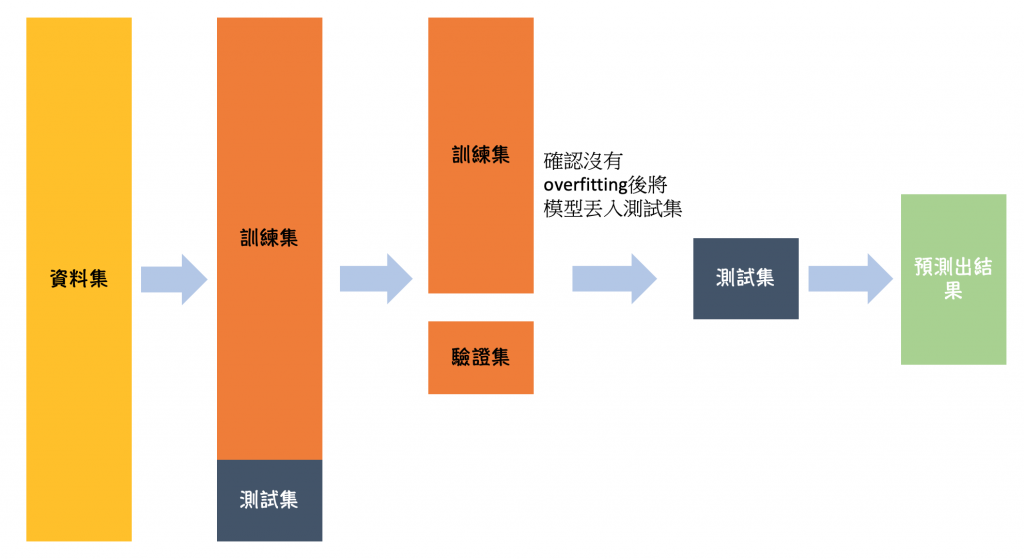
一般来说会将资料分成三份:
- 训练资料:主要训练的资料集。把它想成为了考试平时上课的内容。
- 验证资料:验证主要资料及模型的好坏。把它想成平时小考,测验上课内容。
- 测试资料:我们预测的资料。把它想成大考,评估这整个所训练出来的结果。
而在切分资料时又分成两种方式:
1.正常顺序切割
一般然说我们会将训练资料与测试资料切割成8:2或7:3的比例
wilt_all = pd.read_csv('wilt_all.csv') #载入资料
#利用模型等比例切割
right_ratio_x_train, right_ratio_x_test, right_ratio_y_train, right_ratio_y_test = train_test_split(wilt_all, labels, test_size=0.2, random_state=666)
#转换
right_ratio_y_train = le.transform(right_ratio_y_train)
right_ratio_y_test = le.transform(right_ratio_y_test)
把结果print出来
print('right_ratio_y_train class n:', sum(right_ratio_y_train==0))
print('right_ratio_y_train class w:', sum(right_ratio_y_train==1))
print('right_ratio_y_train ratio n:', sum(right_ratio_y_train==0)/len(right_ratio_y_train))
print('right_ratio_y_train ratio w:', sum(right_ratio_y_train==1)/len(right_ratio_y_train))
print('------------------------------------------')
print('right_ratio_y_test class n:', sum(right_ratio_y_test==0))
print('right_ratio_y_test class w:', sum(right_ratio_y_test==1))
print('right_ratio_y_test ratio n:', sum(right_ratio_y_test==0)/len(right_ratio_y_test))
print('right_ratio_y_test ratio w:', sum(right_ratio_y_test==1)/len(right_ratio_y_test))
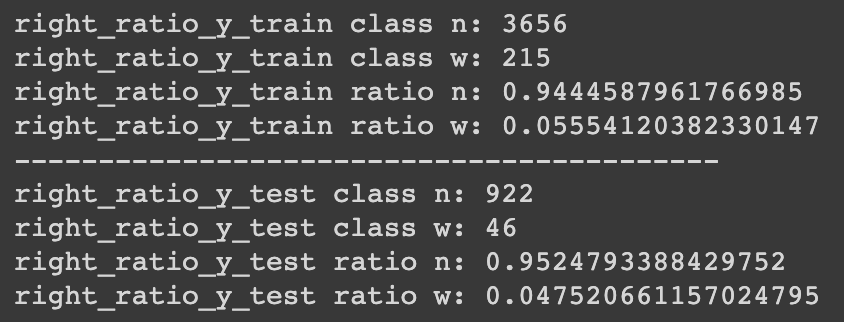
可以发现资料已经被我们等比例切割了。
2.K-fold Cross-validation
为了避免正常切割,导致有些资料训练不到。因此衍生出将资料切成k份让每个资料都轮流当训练集跟验证集。如下图所示。
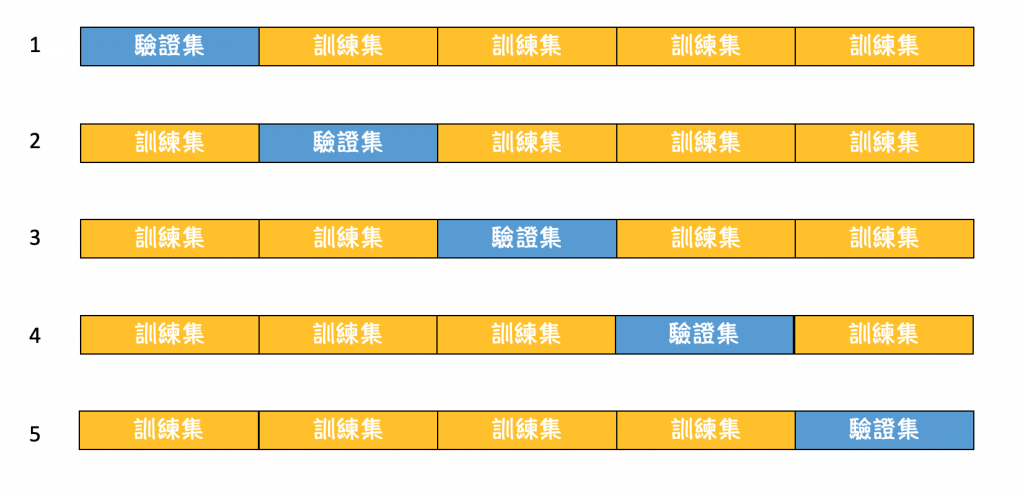
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import cross_val_score
#能够利用cross validation计算模型之表现,看模型表现是否平均
NB_model = GaussianNB()
scores = cross_val_score(NB_model, right_ratio_x_train, right_ratio_y_train, cv=5, scoring='f1')
scores
三、结论
资料编码跟资料分割都是资料前处理中重要的步骤,大家可以试着去找资料来做看看,顺便判断哪些资料需要做资料编码,哪些不需要。不知不觉我们的挑战也进行三分之一了,希望目前的教学对大家都有些许帮助,有什麽问题也欢迎拿出来一起讨论喔。
<<: 【Day 1】Startup x macOS setup x 一起来挖萝卜坑
>>: Day 8 : Docker 基本操作 Image 篇
Day 02: ML基础第二步 Anaconda开发环境
前言 Python虽然可以直接使用Windows的Console直接执行程序,但是不只对於笔者,对於...
第九天:使用 Gradle Wrapper
在开发 JVM 专案时,有时会遇到这些实务问题: 专案使用的 Gradle 版本跟自己本机安装的不同...
Docker:甚麽是容器?
VM暂时告一段落,其实unraid上面的插件还是以容器(docker)最为大宗 像我们後面要做的云端...
架站:Wordpress
为何选择Wordpress? 虽然内容管理系统(CMS)也有其他的选择(例如 Joomla!),但整...
我们的基因体时代-AI, Data和生物资讯 Day11-基因疗法中之腺病毒载体与机器学习
上一篇我们的基因体时代-AI, Data和生物资讯 Day10-基因疗法中之腺病毒载体与机器学习分享...