Day.2 选择 - 关联式与非关联式 (SQL vs. NoSQL )
提到资料库特性势必要先了解SQL(关联式资料库)vs.NoSQL(非关联式资料库)之间的差异,在应用的选择上会带来很大的帮助。
关联式资料库RDBMS(Relational Database Menagement System)
- 资料模型-资料以一个or多个资料表(table)的方式去存放,结构化的定义表格、列、栏、索引、表格之间的关系,资料彼此之间会有明确关联性。
假设我们有以下内容,结构如下~
资料库
Database :login (有多个会员纪录相关资料表)
资料表
Table: user(会员资料),user_group(会员等级分类),user_type(会员所属平台) 分别纪录会员相关内容。
资料
Record: 会员siang的相关纪录

- 资料表:user_type
| user_id (会员ID) | user_level(会员等级) |
|---|---|
| 1992132138111 | 1 |
- table:user_group
| user_id (会员ID) | group_name (平台名称) | group_id (平台ID) |
|---|---|---|
| 1992132138111 | iTHouse99 | 133122323123 |
- table:user
| user_id (会员ID) | user_name (会员名称) | account (帐号) | password (密码) | create_time (建立时间) |
|---|---|---|---|---|
| 1992132138111 | siang | [email protected] | 1234567 | 2021-07-27 12:23:02 |
在资料表设计上会根据不同作用功能(ex.会员登入注册/商品内容/金流)资料去分成一至多个表存取相关内容,并在资料表之间设定彼此的关联性。
在上面例子中当我需要一份完整的会员资料时,便可透过会员ID这个栏位的关联性去连结其他表取得siang的所有栏位资料。
-
交易属性-ACID (评量交易操作是否正确执行与成功的标准)
- Atomicity(原子性):
在一笔交易中可能会包含多笔SQL指令(ex.本次交易需更新2笔资料的状态才算完成)。
如果执行到其中一个步骤时失败,则视为整个交易失败,这时交易期间异动过的资料会全部回到交易执行前的状态。 - Consistency(一制性):
代表当资料从状态A(余额:3000元)改变成状态B(余额:1500元)时,不同的使用者在同一时间得到的状态皆会相同(余额:1500元)。 - Isolation(隔离性):
同时间执行的交易不会互相干。(ex.2个不同交易在同时间修改同一笔纪录,其中一个交易要等待另一个交易执行完成才执行,确保不会同步进行) - Durability(持久性):
交易一旦执行成功,对数据的更改就是永久性的,即使遇到系统故障。如Mysql服务意外发生重启或关闭的情况下也有机制能在之後复原资料。
- Atomicity(原子性):
-
实务应用-在ACID的特性下,实务应用上着重於资料操作准确性与要求高度一致性。
ex.像是银行系统或库存系统一旦资料有误差在後续处理是很麻烦的~ -
扩展性-纵向扩展,透过提升机器的硬体(ex.CPU/RAM/SSD)运算能力来平衡资料库系统的负载。
-
SQL(Structured Query Language 结构化查询语言)操作-透过SQL指令语言能在关联式资料库里做到新增、修改、删除资料的动作与建立及修改资料库内容。
非关联式资料库NoSQL(Not Only SQL)
Not Only SQL代表不同於以往关联式资料库资料利用的方式,设计需求用来处理大量快速变化的非结构化资料。
开始前先复习一下关联式资料库的储存资料方法 :
1.需事先定义好资料表的关系栏位。
2.储存资料格式上需根据定义好的资料结构描述去新增对应值。
-
资料模型-分成多种不同属性特点的模型。
ex.键值资料库/文件资料库/图形资料库/列式资料库等...。 资料库模型参考文件 -
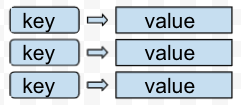
键值类型资料库(Key-value Oriented Database)
每笔资料包含一组key(索引键)和value(资料内容),使用键值key-value对应关系存放资料,透过唯一索引键key(Primary key概念所以不会有重复值,同时也是效率好的原因)便可直接存取该key对应值。
储存的资料格式:没有限定结构内容,可以是(JSON,二进位资料,文字...)。
以後端来说常遇到有些资料的需求得频繁的对资料存取更新,如果透过关联式资料库操作势必会增加机器的负载量,而利用Nosql特性便可达到快速存取作用并且在写入资料格式上也不会被局限住。
ex. 常用的Redis(引用官方LOGO)

要注意Key-value储存资料的方式,如果要修改现有纪录值(value)的话,在执行上会覆写掉原本的全部纪录。看以下例子~
假设我要修改siang01的account值改成[email protected]。在记录更动时只写 {"account":"[email protected]"}
修改前:
| Key | Value |
|---|---|
| siang01 | {"user_id":"1992132138111","user_name":siang,"account":"[email protected]"} |
修改後:
| Key | Value |
|---|---|
| siang01 | {"account":"[email protected]"} |
- 文件类型资料库 (Document Oriented Database)
资料库(储存文件档的集合) -> 集合(由多个文件所组成) -> 文件(资料内容)透过唯一索引键去找对应文件档,键值对形式存储。
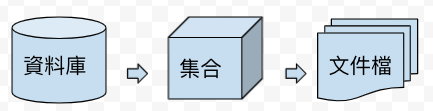
储存的资料格式(value): XML or JSON格式储存为文件档。
| Key | Document |
|---|---|
| siang01 | {"user_id":1992132138111,"user_name":siang,"account":[email protected],"password": 1234567,"create_time": "2021-07-27 12:23:02"} |
SQL vs. NoSQL
相较於关联式资料库需表格化的预定义资料结构与关联性。 NoSQL属於动态结构,以键值对储存,相对之下不局限於固定的结构根据需要增加键值对,有效减少空间与时间的开销。
上面只举例几个类型,针对nosql部分要了解每个不同类型DB资料储存上的差异与着重特色参考Microsoft这篇文件在分类应用上写的很详细!推~
https://docs.microsoft.com/zh-tw/azure/architecture/data-guide/big-data/non-relational-data
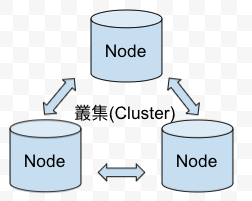
- 扩展性-横向扩展,藉由增加更多节点 (增加相同资料库系统的机器),分散服务请求到各个节点上,每个节点负责部分资料,称为分散式架构。
SQL vs. NoSQL
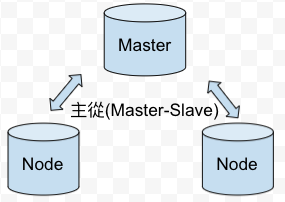
关联式资料库: 应用上由Master去负责全部资料的写入请求,读取的话转由slave去分散master的负担。
非关联式资料库: 在分散式架构下,每一个节点都等同於Master的概念,都能提供资料的读写请求。
-
交易属性- CAP理论
(关联式资料库透过ACID原则去保证资料的正确一致性,非关联式资料库主要了解CAP和最终一制性所代表的意思。)
ps.可以发现关联式ACID与非关联式CAP都有A和C,不过意义是完全不同的!
-
最终一致性:
代表在分散式系统架构下,所有对资料的更新操作最终都会反应在所有节点副本(每一台机器)上,但重要的是需要一些时间,最後资料副本会趋渐於一致。 -
那我们要知道在一个分散式的资料储存架构下,不可能同时满足以下三个条件,所以势必得做出取舍~看以下例子
- Consistency (一致性):
在任何时间,使用者在不同节点下用相同的指令取得的资料结果都是最新的。 - Availability (可用性):
每次的请求(EX: 读取or 写入资料)都可以得到资料库回应。 - Partition tolerance (分区容错性):
在分散式架构下就算有任何一个节点发生错误,整个系统还是可以保持正常运作。
(在关联性资料库中只要主要的那台机器Master出现异常状况整个系统服务是会受到影响的!!)
- Consistency (一致性):
CA (牺牲分区容错性)分散式的架构下基本上不会选择,违反了设计初衷。
CP (牺牲可用性)分散式的架构下,资料会保证是一致性的,但相对的如果有节点异常失效造成资料尚未同步完整,会导致资料异常。(EX: 讯息类系统)
AP (牺牲一致性)分散式的架构下,用牺牲一致性换取系统高可用性,虽然在回传资料上可能回传不正确,但系统是保证可用的。在最後仍可以达到最终一致性只是相对的需要点时间去同步内容!!(EX:直播按赞功能,如果在同一时间有大量人数按赞,在每个人即时看到的按赞人数上可能会不同。随着人数递减,经过一点时间後在去看按赞统计人数是会达成一致的)
实务上三者中只能保证其中2个条件,无法达到同时符合一致性&可用性&分区容错性的完美需求。
(ex.就像如果需要较高的一致性,那在分区容错性上可能较差,除非你在可用性上让步。)
- 实务应用-着重於资料的快速读取与可用性。
应用选择上
-
(资料多寡)
nosql优点就是在大数据时的效能,但如果你的资料量没有达到一定的量,在效能上还是可能会比关联式资料库差。 -
(语法使用)
因为结构上的设计,nosql没办法像关联式资料库那样使用join语法去查询资料。 -
(资料格式)
如果在应用上变动幅度小且有明确的资料格式则选关联式资料库。 -
(资料应用)
资料要求准确性高不能出错选关联式资料库,而资料使用频繁度很高且结构不固定选非关联式资料库。
透过几个重点像是ACID/CAP或资料存取架构,可以看到SQL与NOSQL之间的不同之处,在实际应用上还是取决於需求层面的变化。
下集预告: 万事起头需先把环境设置好,带点轻松的资料库安装与环境部署~
铁人赛 Day2 -- Visual Studio Code 一键叫出HTML & 唯一好用快捷键
下载完VSCode之後 Part1 : 我们可以在延伸模组的地方搜寻并安装你所需要的模组 Part2...
用订便当讲解订定题目的用途 | ML#Day12
我们做一个题目,基本上简单可分成两种用途: 了解关系 预测未来 故事例子 假设工作日常之中,我负责帮...
[Day11]什麽是智慧合约?
智慧合约是一种可以让你避免有中间人介入的合约。如果你想要签约买车、买房子,都需要透过仲介、业务销售...
【把玩Azure DevOps】Day29 再次建立Release pipeline:多个不同Artifacts来源
前面的文章建立过了Release pipeline,但是那次并没有加入多个不同的Artifacts来...
[Python] 关键字yield和return究竟有什麽不同?
学习Scrapy的过程中碰到 yeild 这个关键字,我使用Python快半年了,还真的是第一次遇到...