【Day 6】BERT由Transformer模型构建而成
前五天,我们讲解了BERT模型的核心概念、输入输出以及模型的类型,现在让我们进入模型的结构、原理部分,来谈一谈作为BERT模型的原始架构的Transformer模型。这是BERT基本介绍的最後一部分,在此之後,我们将会更关注如何改善BERT模型的效能,如何更好地适应下游任务等等实战技术面。
Transformer是一种Seq2seq模型
Seq2seq模型是对一类机器学习、自然语言处理模型的总称。Transformer就属於Seq2seq模型。Seq2seq的指称是就模型的「功能」而言,而非对於模型结构的指称。这里的意思是说,Seq2seq模型是为了完成Seq2seq这个固定功能的任务而产生的模型的总称,这种任务就是序列输入、序列输出。
这又是什麽意思呢?举例来说,最常见的自然语言处理应用——自动翻译,就是Seq2seq,也就是序列输入(例如一串英文文本)、序列输出(一串自动翻译好的中文文本)。它与其他自然语言任务的差别主要在於序列的输入和输出长度不一定一致,两个序列间没有必然的对应关系。你可以想想中文、英文、日文、韩文的语序、语法其实大不相同,不可能透过一一对应的方式来完成任务。
那麽Seq2seq的任务该怎麽设计相应的模型架构呢?答案是Encoder-Decoder。
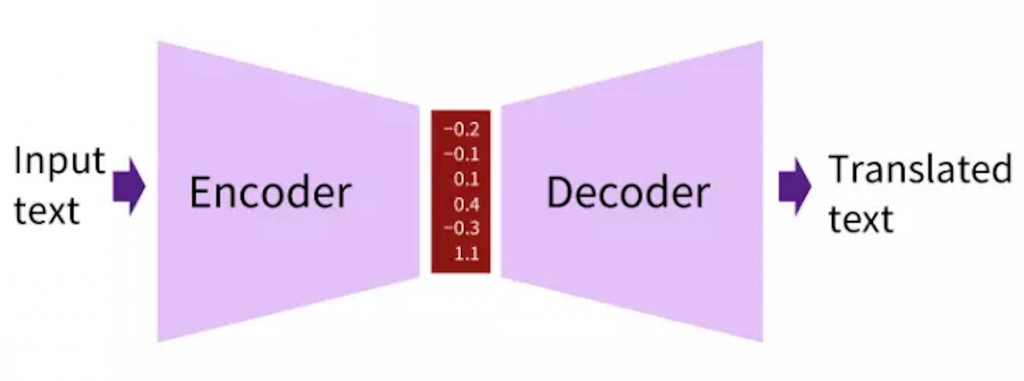
上图就是Encoder、Decoder的想法示意图。既然输入序列与输出序列长度不一致也没有一一对应关系,那不如我们就把输入序列用模型编码成一些向量,然後再将这些编码好的向量用模型解码为输出序列吧。这样序列对应的问题就可以获得解决。我们不用为了序列长度等等问题而伤脑筋。
几乎所有类神经网路模型都可以做Encoder-Decoder这件事,所以通俗来讲,只要设计成这样的结构,能够完成Seq2seq任务,就属於Seq2seq模型。但通常来说,我们只会考虑那些表现比较好的模型。MLP、CNN无法处理序列的先後次序,不适合文本处理,先排除。而剩下的模型就是具备序列记忆能力的RNN家族(包括GRU、LSTM)和Transformer了。
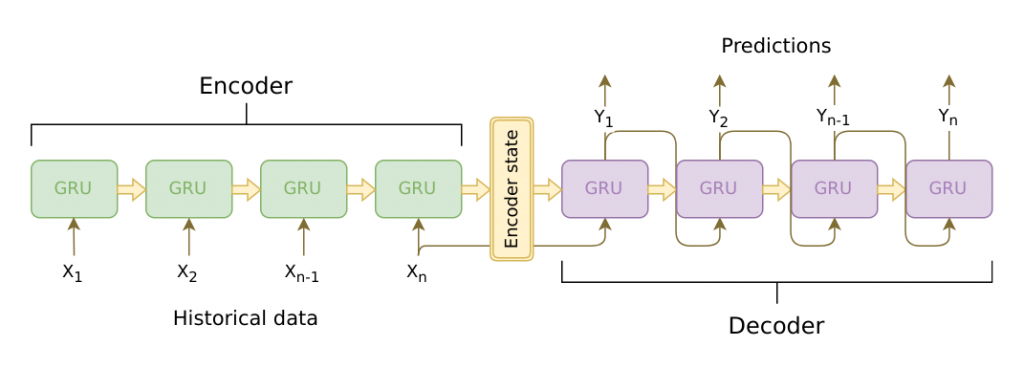
上图是以GRU为基础单位的Seq2seq模型。可以看到编码的过程就是一步步输入序列中的token进行运算,最後一个Hidden State(通常对应输入序列的结束符号)就是编码结果。而解码则是从最後一个Hidden State开始一步步进行序列生成,直到生成了一个序列结束的符号。
Transformer的核心是自注意力机制Self Attention
GRU、LSTM固然可以处理Seq2seq的任务,但是实际的表现往往难以满足应用需求。主要是因为如下几个问题:
- 模型会遗忘早期输入的序列,编码结果通常无法反映完整的序列内容。 这是RNN系列模型的老问题了。Seq2seq任务中此问题会相对更加严重,因为整个序列的资讯都被编码为最後一个Hidden State,其维度一般只有几百维,迫使模型放弃一些「不重要」的资讯。而被忘记的往往是距离远的序列前半部分输入。
- 输入与输出阶段都必须依次进行,速度缓慢。 这也是RNN类型模型难以解决的大问题,输出时也就罢了,但输入时必须一个个input的问题拖慢了整体的效率。
而能够同时解决这两个问题的模型就是Transformer。它的核心概念是注意力机制Attention。其实Attention并不是Transformer模型独有的发明,在LSTM作为Seq2seq任务模型的时代,Attention就已经被引入来提升效果了(也就是解决上面说的遗忘问题)。但Transformer的另一个优点则在发布之初是序列模型中少见的:能够进行平行运算。这大大提升了运算速度,也让BERT等包含巨量参数的预训练模型成为可能。(值得一提的是,ELMO是基於LSTM的预训练模型)
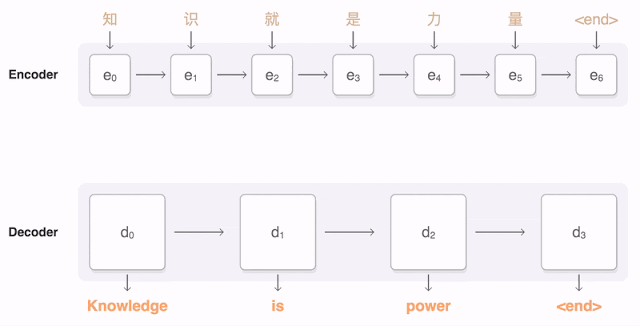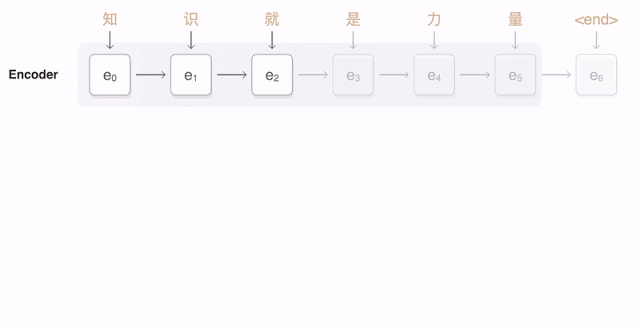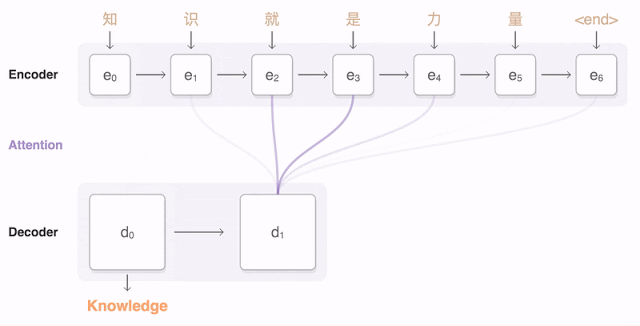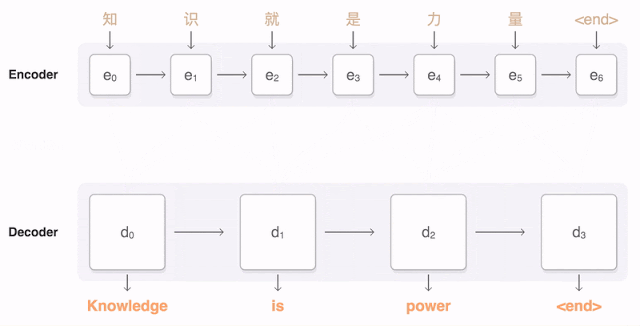
那麽,什麽是Attention(原始版本,非Transformer的)?上方是一个简单的示意图。简单地说就是让输出序列的每一个Hidden State都与每一个Encoder部分的Hidden State做点乘,计算出注意力得分,再按得分权重反馈回Decoder部分。如果得分高,Decoder的时候就会更多考虑这个Encoder部分的资讯。这避免了编码集中於输入序列最後一步的问题。
而Tranformer采用了这个Decoder部分与Encoder部分相互Attention的机制,它还额外增加了一个Self Attention自注意力机制(也就是Attention的改版),彻底取代了序列回归模型。让LSTM等等几乎要退出历史舞台... 
上图就是自注意力机制的运算过程,有兴趣的话再详细研究即可,不必完全搞懂每一步的运算细节。但要知道的是,自注意力机制的改进是将原本用在Encoder和Decoder之间的运算拿到了输入序列自身,让序列中的每一个Embedding都可以相互注意、采纳权重,自然也就取代了LSTM的那种记忆机制。而且上方的矩阵运算是可以完全平行化处理的,这样就解决了传统的Seq2seq的第二个问题。
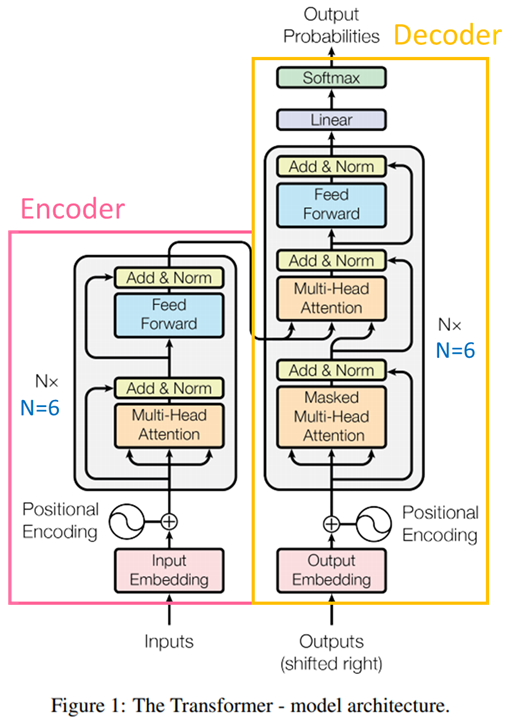
上方是Transformer的模型完整架构,已经标示出了Encoder和Decoder的范围。其中的Multi-Head Attention就是注意力所应用的地方,而其他诸如Add & Norm、Positional Encoding等属於工程上的处理,後续也有不同的修改(例如,BERT的Positonal Embedding与原始Transformer的就不一样),不属於今天重点,就不展开介绍了。
需要注意的主要是模型下方的那两个输入(虽然其中一个写了Output),这可能是让初学者困扰的地方。左边的输入就是输入序列,比较好理解。右边的输入看上去是要输入「输出」,这不是矛盾了吗?其实,右边的输出部分,Transformer仍然遵循Seq2seq的基本模式,也就是,将已经输出的部分序列再重新输入进模型,预测下一个输出,循环往复,完成整个输出序列。例如要输出一句「我要去上学」,不是一句话直接完整Output,而是从一个类似<Start>的token开始依序输出<Start>我、<Start>我要、<Start>我要去、<Start>我要去上、<Start>我要去上学、<Start>我要去上学<End>。右上角的Output Probability其实是指下一个输出token的概率分布。这整个过程被称为自回归模型。
BERT主要由Transformer的Encoder部分组成
一个基本事实:Transformer是Seq2seq模型,而Transformer是BERT模型的基本组成结构,但是BERT却并不是Seq2seq模型。
嗯嗯?怎麽回事,听起来怎麽像逻辑错误,Seq2seq的Transformer怎麽被叠了十几层之後就不是Seq2seq了。原因是,我们通常称BERT的基础结构为Transformer是一种简略的说法, 其实完整的说法是:Google-BERT由Transformer的Encoder部分组成,没有使用Decoder部分。所以BERT自然无法单独处理Seq2seq任务(需要额外加Decoder层)了。我们之前所介绍的下游任务中,也没有Seq2seq的任务举例。
但是原始版本BERT不能做,不代表BERT家族的其他成员不行。远亲的另一个预训练语言模型GPT,就是完全用Transformer的Decoder部分进行预训练的。所以GPT系列难以进行自然语言理解,却在生成任务上打遍天下无敌手。那有没有办法结合BERT与GPT?乾脆用类似完整Transformer的架构进行预训练呢?当然也有,这个模型叫做BART。既能充分理解输入序列,同时也可以生成目标序列。在一些需要情境的生成任务中尤其好用(例如生成式摘要、翻译)。
Day 10 Dart语言-混合及泛型
混合mixins 介绍:mixin是一种可以把自己的方法提供给别的类别使用,却不需要成为其他类别的父...
Day10 PHP数据类型--基本类型之数字与布尔型
这是今天要介绍的详细一点的数据类型: 整型(int/integer) 浮点型(float) 布尔型(...
DAY11 制作样板(Template)
用这个来开发样板 https://developers.line.biz/flex-simulato...
CLOUDWAYS虚拟主机限时首二月7折优惠码,只到2021/9/5
优惠码SUMMER30 优惠时间:只到2021/9/5 折扣内容:首2个月7折(适用於所有方案) ☞...
第 24 集:Bootstrap 客制化 Container 容器
此篇会教学如何将 Bootstrap container 容器,自干一个出来。 若是使用 Wrap...