【Day 5】BERT家族的成员们
当本系列文章提到BERT时,最初是指Google所开发的BERT,但後续基本就是指所有运用Transformer和预训练模式的语言模型。今天这篇文章就是在广义的基础上带大家认识BERT这个越来越庞大的家族。只有了解不同模型的差异,我们才可以在实际应用中更有效地使用於下游任务。
以下,我们从三个不同的层次来认识BERT家族,分别是参数量、预训练语料、预训练任务/模型结构:
参数量
同样的任务、同样的基础模型结构,也可以堆出不一样的模型。这可以被理解为模型的「型号」,就像桌子有大中小一样,BERT系列模型往往都会有大中小(甚至超大、超超大)等不同的模型版本。这其中的差异就是参数量,小模型参数量少,大模型参数量大。
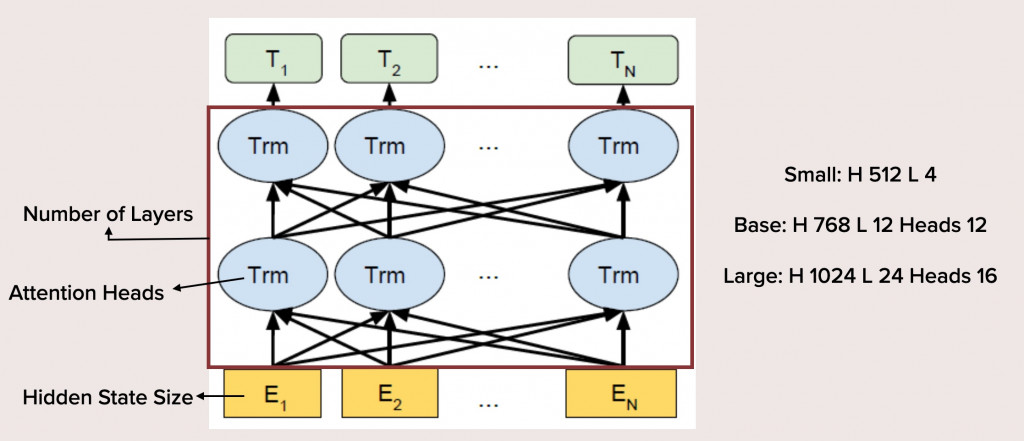
参数量如何能够有所差异呢?
这主要是三个方面的影响:
- 层数(Number of Layers):模型层数越多,参数量自然也会成倍的增长。BERT的Base版本为12层,Large版本就是2倍的24层,比较小的Tiny、Small之类版本都会精简模型层数。
- 注意力头数量(Attention Heads):这里的「注意力头」指的是Transformer模型中的自注意力机制,你可以看网路上的教学文章,非常多。自注意力头的数量越多意味着序列相互之间交叉运算量越大,参数量也是成倍地提升。BERT的Base版本有12个注意力头,Large版本虽多一些,也只有16个。
- 隐藏状态规格(Hidden State Size):也就是模型输入和输出时的Embedding Size。文本所转化为的向量的维度数量。
模型的参数量多寡的影响是非常直观的:大模型所包含的资讯更多,训练起来更困难,但理论上的效果会更好。而小模型更容易使用、训练,甚至可以装在一些嵌入式硬体中。前两年不少研究都关注於如何蒸馏预训练模型,即在尽量不伤害模型的效果的前提下减少参数量。
预训练语料
BERT的预训练文本是维基百科、一个不公开的书本资料集和网路爬虫所获得的文本。这些都属於一般领域的文本。他们可以在大多数自然语言处理任务上获得良好的结果,但并不意味着效果「最好」,在一些特殊领域可能表现也不佳。最理想的方式是根据任务所在的领域寻找对应、相关或至少近似的语料进行预训练,这样模型能更多习得领域知识,在下游任务上也会有更好的表现。
例如虽然Google有释出多语言BERT,但各国的研究者仍倾向使用自己语言所预训练出的BERT。在中文领域,这方面做得最好的是哈工大/讯飞实验室,他们释出了一系列中文的BERT模型,我实际使用过,效果颇佳。
除了语言之外,专业领域也常常用来进行不同语料的预训练。例如生物医学是一个专门的NLP应用领域,BioBERT、PubMedBERT、BlueBERT等等都是专门用於生物医学下游任务的BERT,它们通常在生医论文、临床文本资料上进行预训练。除此之外,还有法律BERT、社群媒体BERT(例如Twitter语料训练出的BERTweet)等等有待开发。
预训练任务/模型结构
预训练任务与模型结构通常是分不开的,更改预训练任务的同时也会相应修改模型结构,但核心想法仍然是预训练任务。BERT的预训练任务为「克漏字」和「下一句预测」。改善预训练任务通常有两个方向,一个是纯粹工程上的改善,另一个是为了让预训练任务更契合下游的特殊任务。
工程上的改善最着名的是RoBERTa,这是FB的研究者在BERT基础上改进、重新预训练所获得的效果更好的BERT版本。有人认为RoBERTa才是真正的BERT,Google所开发的只是一个未完成的版本。他们的改善包括对下一句预测这个任务的修正。研究者发现此任务太过於简单,往往让模型太早学会,反而不利於获得比较好的嵌入。也包括对於预训练阶段的文本长度、Batch Size的调整等等,经过了大量实验和训练技巧的运用,终於获得一个效果出色的模型。
另一个方向则是觉得BERT的初始预训练任务太「难用」,它们与实际上要进行的下游任务有差别,造成了实际效果的不佳。所以思路就是将模型的预训练任务修改为更接近下游任务的。这个方面的研究最近也取得了出色的进展,例如将GPT的文本生成任务融入BERT中的BART和PEGASUS就能在生成式摘要任务中取得不错的效果,而最近也有人针对QA任务提出了更好的预训练任务Splinter。
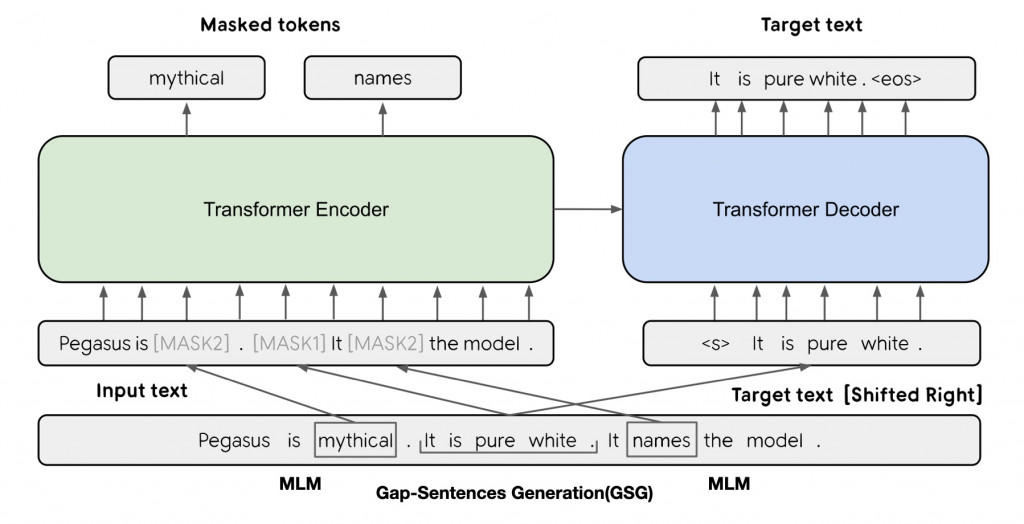
上方就是PEGASUS的预训练任务的架构,可以看到图中左半边仍然是传统BERT的克漏字任务,但右半边则是PEGASUS独创的文本重建任务,这是一种自回归式的文本序列生成。自回归指的是文本的生成是按照顺序一个个进行的,後面的新生成文本会参考已经生成的部分继续生成。这样的预训练任务让PEGASUS学会了在特定情境下生成文本,从而更接近下游的摘要任务。
>>: @Day9 | C# WixToolset + WPF 帅到不行的安装包 [自订动作介接画面-安装後执行]
【Day20】:Servo控制-By PWM输出
Servo 对於简单的角度控制,大家第一个想到的就是伺服马达了吧,大小也适中,非常适合用在机器人上。...
产生 资料库 DbContext 实体原型
Scaffold-DbCoNtext 为资料库的 DbContext 和实体类型产生程序码。 为了让...
CSS微动画 - 动起来番外篇!谈谈Animation的Step
Q: 今天是教师节呢,怎麽没有放假? A: 认真上课黑!本篇是可能实用,但更可能杀光脑细胞的ste...
Day 19-制作购物车系统之将资料汇入脚本
今天要把前面几天的资料(包括MongoDB连线、产品等)汇入到脚本 以下内容有参考教学影片,底下有附...
【Day4】[资料结构]-链结串列Linked List-实作
链结串列(Linked List)建立的方法 append: 在尾部新增节点 insertAt: 在...