AI ninja project [day 8] 文字转语音
除了有语音转文字的服务,
GCP 也提供了文字转语音的服务。
可以想像过去我们在游戏或是动画中需要很多配音员,
现在我们只要有文字,就能生成该角色的声音。
首先是安装:
pip install google-cloud-texttospeech
下面程序码,是使用的方式:
import os
from google.cloud import texttospeech
credential_path = "cred.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
# Instantiates a client
client = texttospeech.TextToSpeechClient()
# Set the text input to be synthesized
synthesis_input = texttospeech.SynthesisInput(text="Hello, World!")
# Build the voice request, select the language code ("en-US") and the ssml
# voice gender ("neutral")
voice = texttospeech.VoiceSelectionParams(
language_code="en-US", ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)
# Select the type of audio file you want returned
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3
)
# Perform the text-to-speech request on the text input with the selected
# voice parameters and audio file type
response = client.synthesize_speech(
input=synthesis_input, voice=voice, audio_config=audio_config
)
with open("output.mp3", "wb") as out:
out.write(response.audio_content)
print('Audio content written to file "output.mp3"')
synthesis_input为输入的台词,
而texttospeech.VoiceSelectionParams参数的部分,为声音的调整,
可以从下面的function列出可选用的语音参数:
import os
credential_path = "cred.json"
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path
def list_voices():
"""Lists the available voices."""
from google.cloud import texttospeech
client = texttospeech.TextToSpeechClient()
# Performs the list voices request
voices = client.list_voices()
for voice in voices.voices:
# Display the voice's name. Example: tpc-vocoded
print(f"Name: {voice.name}")
# Display the supported language codes for this voice. Example: "en-US"
for language_code in voice.language_codes:
print(f"Supported language: {language_code}")
ssml_gender = texttospeech.SsmlVoiceGender(voice.ssml_gender)
# Display the SSML Voice Gender
print(f"SSML Voice Gender: {ssml_gender.name}")
# Display the natural sample rate hertz for this voice. Example: 24000
print(f"Natural Sample Rate Hertz: {voice.natural_sample_rate_hertz}\n")
list_voices()
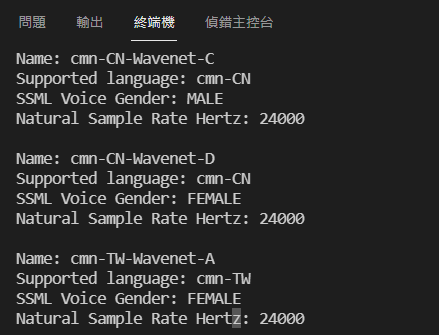
选定之後,我们可以从官网看一下VoiceSelectionParams的参数:
https://cloud.google.com/text-to-speech/docs/reference/rpc/google.cloud.texttospeech.v1#voiceselectionparams
可以发现给定language_code、name、ssml_gender可以完成设定。
而audio_encoding选择格式为mp3,其他格式也能从文件做查询:
https://cloud.google.com/text-to-speech/docs/reference/rpc/google.cloud.texttospeech.v1#google.cloud.texttospeech.v1.AudioEncoding
储存mp3,完成这天的进度。
价格的话也是不贵,免费空间也是很大的,可以从图片中做参考:

>>: Day8: [资料结构]Hash Table - 杂凑表
2021-11-24 盘势分析
加权指数 完成W底後,在10/19站上颈线,直接一路狂奔直到11/19,历经1个月的多头格局, 在这...
Day 1 : 前言与DevOps
前言 大家好,我是Lufor,第一次参加铁人赛。这是我的主要Blog网址: https://lufo...
[Day 12] 第一主餐 pt.5-MySQL Django一起串联,就是这麽简单
在昨天我们成功透过url取得我们的django连接以及内容了 今天我们要再回到虚拟环境,架设MySQ...
AIS3
今天来分享我在 AIS 的所见所闻! 进入正题 前些天的文章中已经向各位分享 AIS 的报名方式 (...
Day 27 PostgreSQL 慢查询提速 50+ 倍?
Odoo的整体运作速度算是很快, 但遇到单资料表破千万笔资料时, 仍然有不断转圈圈的时候, 那该怎麽...